Təhlükəsizlik məlumat portalı. Kalman skalyar ölçmələr üçün Kalman filtrini süzür
Wiener filtrləri emal prosesləri və ya bütövlükdə proseslərin bölmələri (blok emalı) üçün ən uyğundur. Ardıcıl emal müşahidə prosesi zamanı süzgəc girişində alınan məlumatları nəzərə almaqla hər takt siklində siqnalın cari qiymətləndirilməsini tələb edir.
Wiener filtrasiyası ilə hər bir yeni siqnal nümunəsi bütün filtr çəki əmsallarının yenidən hesablanmasını tələb edəcəkdir. Hal-hazırda, daxil olan adaptiv filtrlər yeni məlumatlarəvvəllər hazırlanmış siqnal qiymətləndirməsinin davamlı tənzimlənməsi üçün istifadə olunur (radarda hədəf izləmə, idarəetmədə avtomatik idarəetmə sistemləri və s.). Kalman filtri kimi tanınan adaptiv rekursiv filtrlər xüsusi maraq doğurur.
Bu filtrlər avtomatik tənzimləmə və idarəetmə sistemlərində idarəetmə dövrələrində geniş istifadə olunur. Onların işini dövlət məkanı kimi təsvir etmək üçün istifadə edilən xüsusi terminologiya ilə sübut olunduğu kimi, onların gəldiyi yer budur.
Neyron hesablama praktikasında həll edilməli olan əsas problemlərdən biri neyron şəbəkələrinin öyrədilməsi üçün sürətli və etibarlı alqoritmlərin əldə edilməsidir. Bu baxımdan, əks əlaqə dövrəsində xətti filtr təlim alqoritmindən istifadə etmək faydalı ola bilər. Öyrənmə alqoritmləri iterativ xarakter daşıdığından, belə filtr ardıcıl rekursiv qiymətləndirici olmalıdır.
Parametrlərin qiymətləndirilməsi problemi
Statistik həllər nəzəriyyəsində böyük praktiki əhəmiyyət kəsb edən problemlərdən biri aşağıdakı kimi formalaşdırılan sistemlərin vəziyyət vektorlarının və parametrlərinin qiymətləndirilməsi problemidir. Tutaq ki, birbaşa ölçülə bilməyən $X$ vektor parametrinin dəyərini qiymətləndirmək lazımdır. Əvəzində $X$-dan asılı olaraq başqa $Z$ parametri ölçülür. Qiymətləndirmə tapşırığı suala cavab verməkdir: $Z$ bilməklə $X$ haqqında nə demək olar. Ümumiyyətlə, $X$ vektorunun optimal qiymətləndirilməsi proseduru qiymətləndirmənin keyfiyyəti üçün qəbul edilmiş meyardan asılıdır.
Məsələn, parametrlərin qiymətləndirilməsi probleminə Bayes yanaşması təxmin edilən parametrin ehtimal xassələri haqqında tam apriori məlumat tələb edir ki, bu da çox vaxt mümkün olmur. Bu hallarda, onlar daha az apriori məlumat tələb edən ən kiçik kvadratlar metoduna (LSM) müraciət edirlər.
$Z$ müşahidə vektorunun xətti model tərəfindən $X$ parametr qiymətləndirmə vektoru ilə əlaqəli olduğu və müşahidədə təxmin edilən parametrlə korrelyasiya olunmayan səs-küy $V$ olduğu hal üçün ən kiçik kvadratların tətbiqini nəzərdən keçirək:
$Z = HX + V$, (1)
burada $H$ müşahidə olunan kəmiyyətlər və təxmin edilən parametrlər arasındakı əlaqəni təsvir edən transformasiya matrisidir.
Kvadrat xətanı minimuma endirən $X$ təxmini aşağıdakı kimi yazılır:
$X_(ots)=(H^TR_V^(-1)H)^(-1)H^TR_V^(-1)Z$, (2)
Qoy $V$ səsi korrelyasiyasız olsun, bu halda $R_V$ matrisi sadəcə olaraq eynilik matrisidir və qiymətləndirmə tənliyi sadələşir:
$X_(ots)=(H^TH)^(-1)H^TZ$, (3)
Matris formasında yazmaq çoxlu kağıza qənaət edir, lakin bəziləri üçün qeyri-adi ola bilər. Yu.M.Korşunovun “Kibernetikanın riyazi əsasları” monoqrafiyasından götürülmüş aşağıdakı nümunə bütün bunları göstərir.
Aşağıdakı elektrik dövrəsi var:
Bu halda müşahidə edilən kəmiyyətlər $A_1 = 1 A, A_2 = 2 A, V = 20 B$ alət oxunuşlarıdır.
Bundan əlavə, müqavimətin $R = 5$ Ohm olduğu bilinir. Minimum orta kvadrat xəta meyarı baxımından $I_1$ və $I_2$ cərəyanlarının qiymətlərini ən yaxşı şəkildə qiymətləndirmək tələb olunur. Burada ən vacibi, müşahidə edilən kəmiyyətlər (cihazın oxunması) ilə təxmin edilən parametrlər arasında müəyyən əlaqənin olmasıdır. Və bu məlumat kənardan gətirilir.
Bu vəziyyətdə, bunlar Kirchhoff qanunlarıdır, filtrləmə vəziyyətində (bunu daha sonra müzakirə edəcəyik) - cari dəyərin əvvəlkilərdən asılılığını qəbul edən bir zaman seriyasının avtoreqressiv modeli.
Beləliklə, statistik həllər nəzəriyyəsi ilə heç bir şəkildə əlaqəli olmayan Kirchhoff qanunlarını bilmək bizə müşahidə olunan dəyərlərlə təxmin edilən parametrlər arasında əlaqə yaratmağa imkan verir (elektrik mühəndisliyini öyrənənlər yoxlaya bilər, qalanları olacaq onların sözünü qəbul etmək):
$$z_1 = A_1 = I_1 + \xi_1 = 1$$
$$z_2 = A_2 = I_1 + I_2 + \xi_2 = 2$$
$$z_2 = V/R = I_1 + 2 * I_2 + \xi_3 = 4$$
Bu vektor şəklindədir:
$$\begin(vmatrix) z_1\\ z_2\\ z_3 \end(vmatrix) = \begin(vmatrix) 1 & 0\\ 1 & 1\\ 1 & 2 \end(vmatrix) \begin(vmatrix) I_1\ \ I_2 \end(vmatrix) + \begin(vmatrix) \xi_1\\ \xi_2\\ \xi_3 \end(vmatrix)$$
Və ya $Z = HX + V$, harada
$$Z= \begin(vmatrix) z_1\\ z_2\\ z_3 \end(vmatrix) = \begin(vmatrix) 1\\ 2\\ 4 \end(vmatrix) ; H= \begin(vmatrix) 1 & 0\\ 1 & 1\\ 1 & 2 \end(vmatrix) ; X= \begin(vmatrix) I_1\\ I_2 \end(vmatrix) ; V= \begin(vmatrix) \xi_1\\ \xi_2\\ \xi_3 \end(vmatrix)$$
Səs-küy dəyərlərinin bir-biri ilə əlaqəsiz olduğunu nəzərə alaraq, 3-cü düstura uyğun olaraq ən kiçik kvadratlar metodundan istifadə edərək I 1 və I 2 qiymətləndirməsini tapacağıq:
$H^TH= \begin(vmatrix) 1 & 1& 1\\ 0 & 1& 2 \end(vmatrix) \begin(vmatrix) 1 & 0\\ 1 & 1\\ 1 & 2 \end(vmatrix) = \ start(vmatrix) 3 & 3\\ 3 & 5 \end(vmatrix) ; (H^TH)^(-1)= \frac(1)(6) \begin(vmatrix) 5 & -3\\ -3 & 3 \end(vmatrix) $;
$H^TZ= \begin(vmatrix) 1 & 1& 1\\ 0 & 1& 2 \end(vmatrix) \begin(vmatrix) 1 \\ 2\\ 4 \end(vmatrix) = \begin(vmatrix) 7\ \ 10 \end(vmatrix); X(ots)= \frac(1)(6) \begin(vmatrix) 5 & -3\\ -3 & 3 \end(vmatrix) \begin(vmatrix) 7\\ 10 \end(vmatrix) = \frac (1)(6) \begin(vmatrix) 5\\ 9 \end(vmatrix)$;
Beləliklə, $I_1 = 5/6 = 0,833 A$; $I_2 = 9/6 = 1,5 A$.
Filtrləmə tapşırığı
Sabit dəyərlərə malik parametrlərin qiymətləndirilməsi problemindən fərqli olaraq, süzgəc problemi qiymətləndirmə proseslərini tələb edir, yəni səs-küylə təhrif edilən və buna görə də birbaşa ölçmə üçün əlçatmaz olan zamanla dəyişən siqnalın cari təxminlərinin tapılmasını tələb edir. Ümumiyyətlə, filtrləmə alqoritmlərinin növü siqnalın və səs-küyün statistik xüsusiyyətlərindən asılıdır.
Faydalı siqnalın zamanın yavaş-yavaş dəyişən funksiyası olduğunu və müdaxilənin əlaqəsiz səs-küy olduğunu fərz edəcəyik. Siqnalın və səs-küyün ehtimal xarakteristikaları haqqında apriori məlumatın olmaması səbəbindən yenə də ən kiçik kvadratlar metodundan istifadə edəcəyik.
Əvvəlcə $z_n, z_(n-1), z_(n-2)\nöqtələr z_(n-) zaman seriyasının mövcud $k$ ən son dəyərlərinə əsaslanaraq, $x_n$ cari dəyərinin təxminini alırıq. (k-1))$. Müşahidə modeli parametrlərin qiymətləndirilməsi məsələsində olduğu kimidir:
Aydındır ki, $Z$ $z_n, z_(n-1), z_(n-2)\nöqtələrin z_(n-(k-1))$ zaman sıralarının müşahidə edilmiş qiymətlərindən ibarət sütun vektorudur. , $V $ səs-küy sütununun vektorudur $\xi _n, \xi _(n-1),\xi_(n-2)\nöqtələr \xi _(n-(k-1))$, əsl siqnalı təhrif edir. . $H$ və $X$ simvolları nə deməkdir? Məsələn, $X$ sütun vektoru zaman seriyasının cari dəyərini qiymətləndirmək üçün lazım olan hər şeydən danışa bilərikmi? Və $H$ transformasiya matrisi dedikdə nə nəzərdə tutulduğu ümumiyyətlə aydın deyil.
Bütün bu suallara yalnız siqnal yaratma modeli konsepsiyası nəzərə alınarsa cavab vermək olar. Yəni orijinal siqnalın hansısa modeli lazımdır. Bu başa düşüləndir, siqnalın və müdaxilənin ehtimal xüsusiyyətləri haqqında aprior məlumat olmadıqda, yalnız fərziyyələr irəli sürmək olar. Bunu qəhvə zəminində falçılıq adlandıra bilərsiniz, lakin ekspertlər fərqli terminologiyaya üstünlük verirlər. Onların saç qurutma maşınlarında buna parametrik model deyilir.
Bu halda, bu xüsusi modelin parametrləri təxmin edilir. Müvafiq siqnal yaratma modelini seçərkən yadda saxlayın ki, istənilən analitik funksiya Taylor seriyasına genişləndirilə bilər. Taylor seriyasının diqqətəlayiq xüsusiyyəti ondan ibarətdir ki, müəyyən $x=a$ nöqtəsindən $t$ istənilən sonlu məsafədə olan funksiyanın forması $x=a nöqtəsinin sonsuz kiçik qonşuluğunda funksiyanın davranışı ilə unikal şəkildə müəyyən edilir. $ (söhbət onun birinci və daha yüksək dərəcəli törəmələrindən gedir).
Beləliklə, Teylor sıralarının mövcudluğu o deməkdir ki, analitik funksiya çox güclü birləşmə ilə daxili struktura malikdir. Məsələn, özümüzü Taylor seriyasının üç şərti ilə məhdudlaşdırsaq, siqnal yaratma modeli belə görünəcəkdir:
$x_(n-i) = F_(-i)x_n$, (4)
$$X_n= \begin(vmatrix) x_n\\ x"_n\\ x""_n \end(vmatrix) ; F_(-i)= \begin(vmatrix) 1 & -i & i^2/2\\ 0 & 1 & -i\\ 0 & 0 & 1 \end(vmatrix) $$
Yəni 4-cü düstur çoxhədlinin verilmiş sırası üçün (nümunədə 2-yə bərabərdir) zaman ardıcıllığında siqnalın $n$-ci qiyməti ilə $(n-i)$- arasında əlaqə qurur. ci. Beləliklə, bu vəziyyətdə təxmin edilən vəziyyət vektoru təxmin edilən dəyərin özündən əlavə, siqnalın birinci və ikinci törəmələrini əhatə edir.
Avtomatik idarəetmə nəzəriyyəsində belə bir filtr 2-ci dərəcəli astatizmə malik filtr adlanır. Bu hal üçün $H$ çevrilmə matrisi (cari və $k-1$ əvvəlki nümunələrdən istifadə etməklə təxmin edilir) belə görünür:
$$H= \begin(vmatrix) 1 & -k & k^2/2\\ - & - & -\\ 1 & -2 & 2\\ 1 & -1 & 0.5\\ 1 & 0 & 0 \ son(vmatrix)$$
Bütün bu ədədlər Taylor seriyasından bitişik müşahidə olunan dəyərlər arasındakı zaman intervalının sabit və 1-ə bərabər olduğu fərziyyəsi ilə əldə edilir.
Beləliklə, süzgəc problemi, bizim irəli sürdüyümüz fərziyyələrə əsasən, parametrlərin qiymətləndirilməsi probleminə endirildi; bu halda qəbul etdiyimiz siqnal yaratma modelinin parametrləri təxmin edilir. Və dövlət vektorunun qiymətlərinin qiymətləndirilməsi $X$ eyni düstur 3 istifadə edərək həyata keçirilir:
$$X_(ots)=(H^TH)^(-1)H^TZ$$
Əslində, biz siqnal yaratma prosesinin avtoreqressiv modelinə əsaslanan parametrik qiymətləndirmə prosesini həyata keçirmişik.
Formula 3 proqram təminatında asanlıqla həyata keçirilə bilər, bunun üçün siz $H$ matrisini və $Z$ müşahidə sütunu vektorunu doldurmalısınız. Belə filtrlər adlanır sonlu yaddaşa malik filtrlər, çünki onlar cari təxmin $X_(noc)$ əldə etmək üçün son $k$ müşahidələrindən istifadə edirlər. Hər yeni müşahidə addımında mövcud müşahidələr toplusuna yenisi əlavə edilir və köhnəsi atılır. Bu təxminlərin əldə edilməsi prosesi adlanır sürüşən pəncərə.
Artan yaddaşı olan filtrlər
Sonlu yaddaşa malik filtrlərin əsas çatışmazlığı ondan ibarətdir ki, hər yeni müşahidədən sonra yaddaşda saxlanılan bütün məlumatları yenidən hesablamaq lazımdır. Bundan əlavə, təxminlərin hesablanması yalnız ilk $k$ müşahidələrinin nəticələri toplanandan sonra başlaya bilər. Yəni bu filtrlər uzun keçici proses müddətinə malikdir.
Bu çatışmazlıqla mübarizə aparmaq üçün daimi yaddaşı olan filtrdən olan filtrə keçmək lazımdır artan yaddaş. Belə bir filtrdə qiymətləndirmənin aparıldığı müşahidə edilən dəyərlərin sayı cari müşahidənin n sayına uyğun olmalıdır. Bu, $X$ təxmin edilən vektorunun komponentlərinin sayına bərabər olan bir sıra müşahidələrdən başlayaraq təxminlər əldə etməyə imkan verir. Bu isə qəbul edilmiş modelin sırası ilə müəyyən edilir, yəni modeldə Taylor seriyasından neçə termindən istifadə olunur.
Bu zaman n artdıqca filtrin hamarlama xassələri yaxşılaşır, yəni təxminlərin dəqiqliyi artır. Bununla belə, bu yanaşmanın birbaşa tətbiqi hesablama xərclərinin artması ilə əlaqələndirilir. Buna görə yaddaşı artan filtrlər kimi həyata keçirilir təkrarlanan.
Məsələ burasındadır ki, n zamanında bizdə artıq $X_((n-1)ots)$ təxminimiz var ki, orada $z_n, z_(n-1), z_(n-2) \dots z_ bütün əvvəlki müşahidələr haqqında məlumat var. (n-(k-1))$. $X_(nots)$ təxmini $X_((n-1))(\mbox (ots))$ təxminində saxlanılan məlumatdan istifadə etməklə $z_n$ növbəti müşahidədən əldə edilir. Bu prosedur təkrarlanan filtrləmə adlanır və aşağıdakılardan ibarətdir:
- $X_((n-1))(\mbox (ots))$ təxmininə əsasən $i = 1$ üçün düstur 4-dən istifadə edərək $X_n$ təxminini proqnozlaşdırın: $X_(\mbox (notspriori)) = F_1X_( (n-1 )ots)$. Bu a priori təxmindir;
- $z_n$ cari müşahidənin nəticələrinə görə, bu a priori təxmin doğruya, yəni posterioriyə çevrilir;
- bu prosedur $r+1$-dan başlayaraq hər addımda təkrarlanır, burada $r$ filtrin sırasıdır.
Son təkrarlanan filtrləmə düsturu belə görünür:
$X_((n-1)oc) = X_(\mbox (nocapriori)) + (H^T_nH_n)^(-1)h^T_0(z_n - h_0 X_(\mbox (nocapriori))))$, (6) )
ikinci sifariş filtrimiz üçün harada:
Formula 6-a uyğun işləyən artan yaddaş filtri Kalman filtri kimi tanınan filtrləmə alqoritminin xüsusi halıdır.
Bu formulun praktikada tətbiqi zamanı yadda saxlamaq lazımdır ki, ona daxil olan aprior qiymətləndirmə 4-cü düsturla müəyyən edilir və $h_0 X_(\mbox (nocapriori))$ dəyəri $X_( vektorunun birinci komponentini təmsil edir. \mbox (nocapriori))$.
Artan yaddaş filtrinin bir mühüm xüsusiyyəti var. Formula 6-ya baxsanız, yekun qiymətləndirmə proqnozlaşdırılan təxmin vektorunun və düzəliş müddətinin cəmidir. Bu düzəliş kiçik $n$ üçün böyükdür və $n$ artdıqca azalır, $n \rightarrow \infty$-da sıfıra meyl edir. Yəni n artdıqca süzgəcin hamarlaşdırıcı xüsusiyyətləri artır və ona daxil edilmiş model üstünlük təşkil etməyə başlayır. Amma real siqnal modelə ancaq müəyyən dərəcədə uyğun gələ bilər. ayrı sahələr, buna görə də proqnozun dəqiqliyi pisləşir.
Bununla mübarizə aparmaq üçün müəyyən $n$-dan başlayaraq, düzəliş müddətinin daha da azaldılmasına qadağa qoyulur. Bu, filtr zolağının dəyişdirilməsinə bərabərdir, yəni kiçik n üçün filtr daha geniş bant genişliyi (daha az inertial), böyük n üçün isə daha inertial olur.
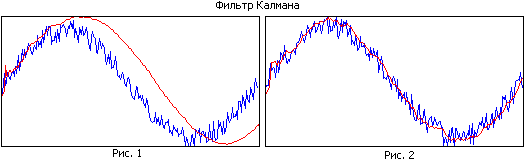
Şəkil 1 və Şəkil 2-ni müqayisə edin. Birinci şəkildə filtrin böyük yaddaşı var və o, yaxşı hamarlanır, lakin dar banda görə təxmin edilən trayektoriya realdan geri qalır. İkinci şəkildə, filtr yaddaşı daha kiçikdir, daha pis düzəldir, lakin real trayektoriyanı daha yaxşı izləyir.
Ədəbiyyat
- Yu.M.Korşunov “Kibernetikanın riyazi əsasları”
- A.V.Balakrişnan "Kalman filtrasiya nəzəriyyəsi"
- V.N.Fomin "Təkrarlanan qiymətləndirmə və adaptiv filtrasiya"
- C.F.N.Cowan, P.M. "Adaptiv filtrlər" verin
Bu filtrdən müxtəlif sahələrdə - radiotexnikadan tutmuş iqtisadiyyata qədər istifadə olunur. Burada biz bu filtrin əsas ideyasını, mənasını, mahiyyətini müzakirə edəcəyik. O, mümkün olan ən sadə dildə təqdim olunacaq.
Tutaq ki, müəyyən bir obyektin bəzi kəmiyyətlərini ölçmək lazımdır. Radiotexnikada onlar ən çox müəyyən bir cihazın (sensor, antenna və s.) çıxışında gərginliklərin ölçülməsi ilə məşğul olurlar. Elektrokardioqraf ilə nümunədə (bax) insan bədənindəki biopotensialların ölçülməsi ilə məşğul oluruq. İqtisadiyyatda, məsələn, ölçülən dəyər valyuta məzənnələri ola bilər. Hər gün məzənnə fərqlidir, yəni. hər gün “ölçüləri” bizə fərqli qiymət verir. Və ümumiləşdirsək, deyə bilərik ki, insan fəaliyyətinin böyük hissəsi (əgər hamısı deyilsə) müəyyən kəmiyyətlərin daimi ölçülməsi və müqayisəsi ilə nəticələnir (kitaba bax).
Beləliklə, tutaq ki, biz daim nəyisə ölçürük. Biz həmçinin hesab edirik ki, ölçmələrimiz həmişə müəyyən xəta ilə gəlir - bu başa düşüləndir, çünki ideal ölçmə vasitələri yoxdur və hər biri xəta ilə nəticə verir. Ən sadə halda təsvir ediləni aşağıdakı ifadəyə endirmək olar: z=x+y, burada x ölçmək istədiyimiz həqiqi qiymətdir və ideal ölçmə cihazımız olsaydı, ölçüləcəkdi, y ölçüdür. səhv təqdim edildi ölçü aləti, və z ölçdüyümüz dəyərdir. Beləliklə, Kalman filtrinin vəzifəsi ölçdüyümüz z-dən təxmin etməkdir (müəyyən etmək), z-ni aldığımız zaman x-in həqiqi dəyərinin nə olduğunu (həqiqi dəyəri və ölçmə xətasını ehtiva edir). X-in həqiqi dəyərini z-dən süzgəcdən keçirmək (alaq otunu təmizləmək) lazımdır — z-dən təhrif edən y səsini çıxarmaq üçün. Yəni, əlimizdə yalnız bir məbləğ olduğundan, bu məbləği hansı şərtlərin verdiyini təxmin etməliyik.
Yuxarıdakıların işığında, indi hər şeyi aşağıdakı kimi formalaşdıraq. Yalnız iki təsadüfi ədəd olsun. Bizə yalnız onların məbləği verilir və bizdən şərtlərin nə olduğunu müəyyən etmək üçün bu məbləğdən istifadə etmək tələb olunur. Məsələn, bizə 12 rəqəmi verildi və deyirlər: 12 x və y ədədlərinin cəmidir, sual x və y nəyə bərabərdir. Bu suala cavab vermək üçün tənlik qururuq: x+y=12. İki naməlum olan bir tənlik aldıq, buna görə də, ciddi şəkildə desək, bu məbləği verən iki ədəd tapmaq mümkün deyil. Ancaq bu rəqəmlər haqqında hələ də nəsə deyə bilərik. Deyə bilərik ki, bunlar ya 1 və 11, ya 2 və 10, ya 3 və 9, ya da 4 və 8 və s., həmçinin ya 13 və -1, ya da 14 və -2, ya da 15 və - rəqəmləri idi. 3 və s. Yəni, cəmindən çoxluğu müəyyən edə bilərik (12-ci misalımızda) mümkün variantlar, cəmi tam olaraq 12 verir. Bu variantlardan biri axtardığımız cütdür ki, əslində hazırda 12 verir.Onu da qeyd etmək lazımdır ki, cəmi 12 verən ədəd cütləri üçün bütün variantlar göstərilən düz xətti təşkil edir. x+y=12 (y=-x+12) tənliyi ilə verilmiş şəkildə 1-də.
Şəkil 1
Beləliklə, axtardığımız cüt bu düz xəttin bir yerində yerləşir. Yenə deyirəm, heç bir əlavə ipucu bilmədən bütün bu variantlardan əslində mövcud olan - 12 rəqəmini verən cütü seçmək mümkün deyil. Bununla belə, Kalman filtrinin icad edildiyi vəziyyətdə belə ipuçları mövcuddur. Təsadüfi ədədlər haqqında əvvəlcədən məlum olan bir şey var. Xüsusilə, orada hər bir cüt nömrə üçün paylama histoqramı məlumdur. Adətən bu çox təsadüfi ədədlərin baş verməsinin kifayət qədər uzun müşahidəsindən sonra əldə edilir. Yəni, məsələn, təcrübədən məlumdur ki, 5% hallarda adətən x=1, y=8 cütü görünür (bu cütü aşağıdakı kimi işarə edirik: (1,8)), 2% hallarda cüt x=2, y=3 (2,3), 1% hallarda cüt (3,1), 0,024% hallarda cüt (11,1) və s. Yenə deyirəm, bu histoqram verilir bütün cütlər üçünədədlər, o cümlədən 12-yə qədər toplayanlar. Beləliklə, 12-yə qədər toplayan hər bir cüt üçün deyə bilərik ki, məsələn, cüt (1, 11) zamanın 0,8% -ində, cüt ( 2, 10) görünür. – 1% hallarda, cüt (3, 9) – 1,5% hallarda və s. Beləliklə, biz histoqramdan istifadə edərək cütlüyün şərtlərinin cəminin 12-yə bərabər olduğunu müəyyən etmək üçün istifadə edə bilərik. Məsələn, 30% hallarda cəmi 12. Qalan 70% -də isə qalan cütlər düşür - bunlar (1,8), (2, 3), (3,1) və s. – 12-dən başqa rəqəmlər toplayanlar. Üstəlik, məsələn, (7,5) cütü 27% hallarda, 12-yə qədər toplayan bütün digər cütlər isə 0,024%+0,8% +1-də görünür. %+1,5%+…=3% hallarda. Beləliklə, histoqramdan öyrəndik ki, cəmi 12-yə çatan rəqəmlər 30% hallarda görünür. Üstəlik, biz bilirik ki, 12 yuvarlanırsa, çox vaxt (30% -dən 27%) bunun səbəbi cütdür (7,5). Yəni əgər artıq 12 yuvarlanırsa, deyə bilərik ki, 90% hallarda (30% -dən 27% - və ya eynidir, hər 30-dan 27 dəfə) 12-nin yuvarlanmasının səbəbi cütdür (7,5). ). Ən çox 12-yə bərabər məbləğin alınmasının səbəbinin (7.5) cütü olduğunu bilərək, çox güman ki, indi düşdüyünü güman etmək məntiqlidir. Əlbətdə ki, bu hələ bir fakt deyil ki, əslində indi 12 rəqəmi bu xüsusi cüt tərəfindən əmələ gəlir, lakin növbəti dəfə 12-yə rast gəlsək və yenə də (7,5) cütünü fərz etsək, onda təxminən 90% 100% hallarda biz haqlı olacağıq. Ancaq (2, 10) cütlüyünü təxmin etsək, 30% hallardan yalnız 1% -də haqlı olacağıq ki, bu da cütü təxmin edərkən 90% ilə müqayisədə düzgün təxminlərin 3,33% -ə bərabərdir (7,5). Budur - Kalman filtr alqoritminin nöqtəsi budur. Yəni, Kalman filtri cəmini cəmi ilə təyin edərkən səhv etməyəcəyinə zəmanət vermir, lakin minimum dəfə səhv edəcəyinə zəmanət verir (səhv ehtimalı minimal olacaq), çünki o, statistikadan istifadə edir - ədəd cütlərinin meydana gəlməsinin histoqramı. Kalman filtrləmə alqoritminin tez-tez ehtimal paylama sıxlığından (PDD) istifadə etdiyini də vurğulamaq lazımdır. Ancaq oradakı mənanın histoqramla eyni olduğunu başa düşmək lazımdır. Üstəlik, histoqram PDF əsasında qurulmuş bir funksiyadır və onun yaxınlaşmasıdır (məsələn, bax).
Prinsipcə, biz bu histoqramı iki dəyişənin funksiyası kimi təsvir edə bilərik - yəni xy müstəvisinin üstündə müəyyən bir səth şəklində. Səthin daha yüksək olduğu yerdə müvafiq cütün əldə edilməsi ehtimalı daha yüksəkdir. Şəkil 2 belə bir səthi göstərir.

Şəkil 2
Yuxarıdakı x+y=12 düz xəttindən göründüyü kimi (bunun cəmi 12 verən cüt variantları var) səth nöqtələri müxtəlif hündürlüklərdə yerləşir və ən yüksək hündürlük koordinatları (7,5) olan variant üçündür. Və 12-yə bərabər bir cəmlə qarşılaşdığımızda, 90% hallarda bu məbləğin meydana çıxmasının səbəbi məhz cütdür (7,5). Bunlar. Məhz 12-yə qədər toplanan bu cüt, cəmi 12 olmaq şərtilə ən yüksək baş vermə ehtimalına malikdir.
Beləliklə, burada Kalman filtrinin ideyası təsvir edilmişdir. Məhz bu əsasda onun hər cür modifikasiyası qurulur - bir pilləli, çox addımlı təkrarlanan və s. Kalman filtrinin daha dərindən öyrənilməsi üçün kitabı tövsiyə edirəm: Van Trees G. Aşkarlama, qiymətləndirmə və modulyasiya nəzəriyyəsi.
p.s. Riyaziyyat anlayışlarının izahı ilə maraqlananlar üçün, necə deyərlər, “barmaqlarda” biz bu kitabı və xüsusən də onun “Riyaziyyat” bölməsindəki fəsilləri tövsiyə edə bilərik (kitabın özünü və ya ayrı-ayrı fəsilləri ondan əldə edə bilərsiniz. ).
1İnteqrasiya edilmiş müasir inkişaflarda Kalman filtrindən istifadənin tədqiqi naviqasiya sistemləri. Tikinti nümunəsi verilmiş və təhlil edilmişdir riyazi model, pilotsuz uçuş aparatlarının koordinatlarının təyin edilməsinin dəqiqliyini artırmaq üçün genişləndirilmiş Kalman filtrindən istifadə edir. Qismən filtr hesab olunur. etdi qısa baxış elmi əsərlər, naviqasiya sistemlərinin etibarlılığını və nasazlığa dözümlülüyünü artırmaq üçün bu filtrdən istifadə etməklə. Bu məqalə İHA yerləşdirmə sistemlərində Kalman filtrinin istifadəsinin bir çox müasir inkişaflarda tətbiq edildiyi qənaətinə gəlməyə imkan verir. Bu istifadənin çoxlu sayda varyasyonları və aspektləri var ki, bu da xüsusilə standart peyk naviqasiya sistemlərinin nasazlığı halında artan dəqiqlikdə nəzərəçarpacaq nəticələr verir. Bu, bu texnologiyanın müxtəlif təyyarələr üçün dəqiq və nasazlığa davamlı naviqasiya sistemlərinin inkişafı ilə bağlı müxtəlif elmi sahələrə təsirinin əsas amilidir.
Kalman filtri
naviqasiya
pilotsuz uçuş aparatı (PUA)
1. Makarenko G.K., Aleşechkin A.M. Peyk radionaviqasiya sistemlərindən gələn siqnallardan istifadə edərək obyektin koordinatlarını təyin edərkən filtrləmə alqoritminin öyrənilməsi // TUSUR Hesabatları. – 2012. – No 2 (26). – səh. 15-18.
2. Bar-Şalom Y., Li X. R., Kirubarajan T. Tətbiqlərlə qiymətləndirmə
İzləmə və Naviqasiya // Nəzəriyyə Alqoritmləri və Proqram təminatı. – 2001. – Cild. 3. – S. 10-20.
3. Bassem I.S. Pilotsuz Uçuş Aparatlarının (İHA) Görmə Əsaslı Naviqasiyası (VBN) // KALQARİ UNİVERSİTETİ. – 2012. – Cild. 1. – S. 100-127.
4. Conte G., Doherty P. Aero Image Matching əsasında İnteqrasiya edilmiş İHA Naviqasiya Sistemi // Aerokosmik Konfrans. – 2008. – Cild. 1. – S. 3142-3151.
5. Guoqiang M., Drake S., Anderson B. İHA lokalizasiyası üçün genişləndirilmiş Kalman filtrinin dizaynı // Məlumat, Qərar və Nəzarətdə. – 2007. – Cild. 7. – S. 224–229.
6. Kiçik Pilotsuz Uçuş Aparatlarından istifadə edərək Hədəfin Lokallaşdırılması üçün Ponda S.S Trayektoriyasının Optimizasiyası // Massaçusets Texnologiya İnstitutu. – 2008. – Cild. 1. – S. 64-70.
7. Wang J., Garrat M., Lambert A. Pilotsuz uçuş aparatlarını idarə etmək üçün gps/ins/vision sensorlarının inteqrasiyası // IAPRS&SIS. – 2008. – Cild. 37. – S. 963-969.
Pilotsuz uçuş aparatlarının (PUA) müasir naviqasiyasının təxirəsalınmaz vəzifələrindən biri koordinatların təyin edilməsinin dəqiqliyini artırmaq vəzifəsidir. Bu problem naviqasiya sistemlərinin inteqrasiyası üçün müxtəlif variantlardan istifadə etməklə həll edilir. Müasir inteqrasiya seçimlərindən biri GPS/QLONASS naviqasiyasının natamam və səs-küylü ölçmələrdən istifadə edərək dəqiqliyi rekursiv şəkildə qiymətləndirən Genişləndirilmiş Kalman filtri ilə birləşməsidir. Hal-hazırda, genişləndirilmiş Kalman filtrinin müxtəlif variasiyaları mövcuddur və inkişaf etdirilir, o cümlədən müxtəlif sayda vəziyyət dəyişənləri. Bu işdə onun istifadəsinin müasir inkişaflarda nə qədər effektiv ola biləcəyini göstərəcəyik. Belə bir filtrin xarakterik təsvirlərindən birini nəzərdən keçirək.
Riyazi modelin qurulması
IN bu misalda biz yalnız İHA-nın üfüqi müstəvidə hərəkəti haqqında danışacağıq, əks halda biz sözdə 2d lokalizasiya problemini nəzərdən keçirəcəyik. Bizim vəziyyətimizdə bu, praktiki olaraq rast gəlinən bir çox vəziyyətlər üçün İHA-nın təxminən eyni hündürlükdə qala bilməsi ilə əsaslandırılır. Bu fərziyyə təyyarə dinamikasının simulyasiyalarını sadələşdirmək üçün geniş istifadə olunur. İHA-nın dinamik modeli aşağıdakı tənliklər sistemi ilə müəyyən edilir:
burada () zamandan asılı olaraq PUA-nın üfüqi müstəvidə koordinatları, PUA-nın istiqaməti, PUA-nın bucaq sürəti və PUA-nın yer sürəti funksiyaları yerinə yetirir və sabit hesab ediləcəkdir. Onlar bir-birindən müstəqildirlər, kovaryansları məlumdur ![]() və , müvafiq olaraq və bərabərdir və külək, pilot manevrləri və s. səbəb olduğu İHA sürətlənməsində dəyişiklikləri modelləşdirmək üçün istifadə olunur. Dəyərlər və İHA-nın maksimum bucaq sürətindən və İHA-nın xətti sürətindəki dəyişikliklərin eksperimental qiymətlərindən əldə edilir - Kronecker simvolu.
və , müvafiq olaraq və bərabərdir və külək, pilot manevrləri və s. səbəb olduğu İHA sürətlənməsində dəyişiklikləri modelləşdirmək üçün istifadə olunur. Dəyərlər və İHA-nın maksimum bucaq sürətindən və İHA-nın xətti sürətindəki dəyişikliklərin eksperimental qiymətlərindən əldə edilir - Kronecker simvolu.
Bu tənliklər sistemi modeldəki qeyri-xəttiliyə və səs-küyün mövcudluğuna görə təxmini olacaqdır. Bu halda ən sadə yaxınlaşma üsulu Eyler yaxınlaşması üsuludur. İHA-nın dinamik hərəkət sisteminin diskret modeli aşağıda göstərilmişdir.
![]()
fasiləsiz vəziyyət vektorunun dəyərini təxmin etməyə imkan verən diskret Kalman filtr vəziyyəti vektoru. ∆ - k və k+1 ölçmələri arasında vaxt intervalı. () və () sıfır orta ilə ağ Gauss səs-küy dəyərlərinin ardıcıllığıdır. Birinci ardıcıllıq üçün kovariasiya matrisi:
Eynilə, ikinci ardıcıllıq üçün:
(2) sisteminin tənliklərində müvafiq əvəzetmələri etdikdən sonra əldə edirik:
Ardıcıllıq və bir-birindən müstəqildir. Onlar həmçinin müvafiq olaraq kovariasiya matrisləri ilə sıfır orta ağ Qauss səs-küy ardıcıllığıdır. Bu formanın üstünlüyü ondan ibarətdir ki, o, hər ölçü arasında diskret səs-küyün dəyişməsini göstərir. Nəticədə aşağıdakı diskret dinamik modeli əldə edirik:
 (3)
(3)
Üçün tənlik:
= ![]() + , (4)
+ , (4)
burada, x və y k-zaman anında İHA-nın koordinatları və səhvi təyin etmək üçün istifadə edilən sıfır orta dəyəri olan təsadüfi parametrlərin Qauss ardıcıllığıdır. Bu ardıcıllığın () və () -dən asılı olmadığı qəbul edilir.
(3) və (4) ifadələri İHA-nın yerini qiymətləndirmək üçün əsas rolunu oynayır k-e koordinatları uzadılmış Kalman filtrindən istifadə etməklə əldə edilir. Naviqasiya sistemlərinin nasazlığının modelləşdirilməsi ilə əlaqədar bu tip filtr onun əhəmiyyətli səmərəliliyini göstərir.
Daha aydınlıq üçün kiçik bir sadə misal verək. Bəzi İHA-nın bir qədər sabit sürətlənmə ilə bərabər sürətlə uçmasına icazə verin.
Burada, x İHA-nın t-zamandakı koordinatıdır və δ bəzi təsadüfi dəyişəndir.
Fərz edək ki, bir təyyarənin yeri haqqında məlumatları qəbul edən GPS sensorumuz var. Bu prosesin modelləşdirilməsinin nəticəsini MATLAB proqram paketində təqdim edək.

düyü. 1. Kalman filtrindən istifadə edərək sensor oxunuşlarının süzülməsi
Şəkildə. 1 Kalman süzgəcindən istifadənin nə qədər effektiv ola biləcəyini göstərir.
Bununla belə, real vəziyyətlərdə siqnallar çox vaxt qeyri-xətti dinamika və anormal səs-küyə malikdir. Məhz belə hallarda uzadılmış Kalman filtrindən istifadə olunur. Səs-küy fərqləri çox böyük deyilsə (yəni, xətti yaxınlaşma adekvatdır), genişləndirilmiş Kalman filtrinin istifadəsi problemin yüksək dəqiqliklə həllini təmin edir. Bununla belə, səs-küyün Qauss olmadığı halda, uzadılmış Kalman filtrindən istifadə etmək olmaz. Bu halda, adətən, Markov zəncirləri ilə Monte Karlo metodlarına əsaslanan ədədi inteqral üsullardan istifadə edən qismən filtr istifadə olunur.
Qismən filtr
Genişləndirilmiş Kalman filtrinin ideyalarını inkişaf etdirən alqoritmlərdən birini - qismən filtri təsəvvür edək. Qismən filtrləmə prosesin ehtimal paylanmasını təmsil edən hissəciklər dəsti üzərində Monte Karlo hovuzunu həyata keçirməklə işləyən suboptimal filtrləmə üsuludur. Burada hissəcik təxmin edilən parametrin əvvəlki paylanmasından götürülən elementdir. Qismən filtrin əsas ideyası ondan ibarətdir ki, paylanmanın təxminini göstərmək üçün çoxlu sayda hissəciklər istifadə edilə bilər. İstifadə olunan hissəciklərin sayı nə qədər çox olarsa, hissəciklər dəsti əvvəlki paylanmanı bir o qədər dəqiq göstərəcək. Hissəcik filtri, qiymətləndirmək istədiyimiz parametrlərin əvvəlcədən paylanmasından N hissəcik yerləşdirməklə işə salınır. Filtrləmə alqoritmi bu hissəciklərin keçməsini nəzərdə tutur xüsusi sistem, sonra isə bu hissəciklərin ölçülməsindən əldə edilən məlumatlardan istifadə edərək çəkin. Yaranan hissəciklər və onlarla əlaqəli kütlələr qiymətləndirmə prosesinin posterior paylanmasını təmsil edir. Dövr hər yeni ölçmə üçün təkrarlanır və hissəciklərin çəkiləri sonrakı paylanmanı təmsil etmək üçün yenilənir. Ənənəvi hissəciklərin filtrasiyası yanaşmasının əsas problemlərindən biri odur ki, yanaşma adətən çox az çəkiyə malik olan digər hissəciklərin əksəriyyətindən fərqli olaraq çox böyük çəkiyə malik bir neçə hissəciklə nəticələnir. Bu, filtrasiyanın qeyri-sabitliyinə gətirib çıxarır. Bu problem köhnə hissəciklərdən ibarət paylamadan N yeni hissəciklərin alındığı bir nümunə alma sürətini tətbiq etməklə həll edilə bilər. Qiymətləndirmənin nəticəsi hissəciklər dəstinin orta qiymətinin nümunəsi götürülməklə əldə edilir. Əgər bir neçə müstəqil nümunəmiz varsa, onda seçmə ortası son dispersiyanı verən ortanın dəqiq təxmini olacaq.
Hissəcik filtri suboptimal olsa belə, hissəciklərin sayı sonsuzluğa meylləndiyi üçün alqoritmin səmərəliliyi Bayes hesablama qaydasına yaxınlaşır. Buna görə də, əldə etmək üçün mümkün qədər çox hissəciklərin olması arzu edilir ən yaxşı nəticə. Təəssüf ki, bu, hesablamaların mürəkkəbliyinin güclü artmasına gətirib çıxarır və nəticədə dəqiqlik və hesablama sürəti arasında güzəştə getməyə məcbur edir. Beləliklə, hissəciklərin sayı dəqiqliyin qiymətləndirilməsi tapşırığına qoyulan tələblərə əsasən seçilməlidir. Hissəcik filtrinin işləməsi üçün digər vacib amil nümunə götürmə sürətinin məhdudlaşdırılmasıdır. Daha əvvəl qeyd edildiyi kimi, seçmə sürəti hissəciklərin süzülməsi üçün vacib parametrdir və onsuz alqoritm sonda degenerasiyaya uğrayacaq. İdeya ondan ibarətdir ki, çəkilər çox qeyri-bərabər paylanırsa və nümunə götürmə həddinə çatmaq üzrədirsə, o zaman aşağı çəkili hissəciklər atılır və qalan dəst yeni nümunələrin götürülə biləcəyi yeni ehtimal sıxlığı təşkil edir. Nümunə alma dərəcəsi həddinin seçilməsi olduqca çətin məsələdir, çünki həm də yüksək tezlikli filtrin səs-küyə həddindən artıq həssas olmasına səbəb olur və çox aşağı olması böyük xətaya səbəb olur. Həmçinin mühüm amil ehtimal sıxlığıdır.
Ümumilikdə, hissəcik filtrləmə alqoritmi stasionar hədəflər üçün və naməlum sürətlənmə dinamikası ilə nisbətən yavaş hərəkət edən hədəflər üçün yaxşı mövqe hesablama performansını göstərir. Ümumiyyətlə, hissəcik filtrləmə alqoritmi uzadılmış Kalman filtrindən daha sabitdir və degenerasiyaya və ciddi uğursuzluqlara daha az meyllidir. Qeyri-xətti, qeyri-qaus paylanması hallarında bu alqoritm filtrləmə hədəfin yerini təyin etməkdə çox yaxşı dəqiqlik göstərir, halbuki genişləndirilmiş Kalman filtrləmə alqoritmi belə şəraitdə istifadə edilə bilməz. Bu yanaşmanın çatışmazlıqlarına onun genişləndirilmiş Kalman filtrinə nisbətən daha yüksək mürəkkəbliyi, həmçinin bu alqoritm üçün düzgün parametrlərin necə seçiləcəyinin həmişə aydın olmaması daxildir.
Bu sahədə perspektivli tədqiqatlar
Təqdim etdiyimizə bənzər Kalman filtr modelinin istifadəsini burada görmək olar, burada inteqrasiya edilmiş sistemin işini yaxşılaşdırmaq üçün istifadə olunur (coğrafi baza ilə uyğunlaşma üçün GPS + kompüter görmə modeli) və vəziyyət. peyk naviqasiya avadanlığının nasazlığı da simulyasiya edilir. Kalman filtrindən istifadə edərək, nasazlıq halında sistemin nəticələri əhəmiyyətli dərəcədə yaxşılaşdırıldı (məsələn, hündürlüyün təyin edilməsində səhv təxminən iki dəfə azaldı və müxtəlif oxlar boyunca koordinatların təyin edilməsində səhvlər demək olar ki, 9 dəfə azaldı). . Kalman filtrinin oxşar istifadəsi də verilmişdir.
Metodlar toplusu nöqteyi-nəzərindən maraqlı bir problem həll olunur. O, həmçinin model konstruksiyasında bəzi fərqlərlə 5 ştatlı Kalman filtrindən istifadə edir. Əldə edilən nəticə əlavə inteqrasiya vasitələrinin (fotoşəkillər və termal təsvirlərdən istifadə olunur) istifadəsi sayəsində təqdim etdiyimiz modelin nəticəsini üstələyir. Bu vəziyyətdə Kalman filtrinin istifadəsi bizə verilən nöqtənin məkan koordinatlarını təyin edərkən səhvi 5,5 m dəyərə qədər azaltmağa imkan verir.
Nəticə
Sonda qeyd edirik ki, Kalman filtrinin İHA yerləşdirmə sistemlərində istifadəsi bir çox müasir inkişaflarda tətbiq olunur. Fərqli vəziyyət faktorları ilə bir neçə oxşar filtrin eyni vaxtda istifadəsinə qədər bu istifadənin çox sayda varyasyonları və aspektləri var. Kalman filtrlərinin inkişafı üçün ən perspektivli istiqamətlərdən biri, səhvləri rəngli səs-küylə təmsil olunacaq və real problemlərin həlli üçün onu daha da dəyərli edəcək dəyişdirilmiş bir filtrin yaradılması kimi görünür. Bu sahədə həm də qeyri-qaus səs-küyünü süzə bilən qismən filtr böyük maraq doğurur. Bu müxtəliflik və xüsusilə standart peyk naviqasiya sistemlərinin sıradan çıxması halında dəqiqliyin artırılmasında nəzərəçarpacaq nəticələr, bu texnologiyanın müxtəlif təyyarələr üçün dəqiq və nasazlığa davamlı naviqasiya sistemlərinin inkişafı ilə bağlı müxtəlif elmi sahələrə təsirinin əsas amilləridir. .
Rəyçilər:
Labunets V.G., texnika elmləri doktoru, professor, kafedranın professoru nəzəri əsaslar Rusiyanın ilk Prezidenti B.N. adına Ural Federal Universitetinin radiotexnikası. Yeltsin, Yekaterinburq;
İvanov V.E., texnika elmləri doktoru, professor, rəhbər. Rusiyanın birinci Prezidenti adına Ural Federal Universitetinin Texnologiya və Kommunikasiyalar kafedrası B.N. Yeltsin, Yekaterinburq.
Biblioqrafik keçid
Gavrilov A.V. İHA KOORDİNATLARININ NEMLƏNDİRİLMƏSİ PROBLEMLƏRİNİN HƏLLİ ÜÇÜN KALMAN FİLTRİNDƏN İSTİFADƏ EDİLMƏSİ // Müasir məsələlər elm və təhsil. – 2015. – No 1-1.;URL: http://science-education.ru/ru/article/view?id=19453 (giriş tarixi: 02/01/2020). “Təbiət Elmləri Akademiyası” nəşriyyatında çap olunan jurnalları diqqətinizə çatdırırıq.
Təsadüfi Meşə mənim ən çox sevdiyim məlumat mədən alqoritmlərindən biridir. Birincisi, inanılmaz dərəcədə çox yönlüdür, həm reqressiya, həm də təsnifat problemlərini həll etmək üçün istifadə edilə bilər. Anomaliyaları axtarın və proqnozlaşdırıcıları seçin. İkincisi, bu, səhv tətbiq etmək həqiqətən çətin olan bir alqoritmdir. Sadəcə ona görə ki, digər alqoritmlərdən fərqli olaraq onun bir neçə fərdiləşdirilə bilən parametrləri var. Həm də təbiətcə təəccüblü dərəcədə sadədir. Və eyni zamanda, heyrətamiz dərəcədə dəqiqdir.
Belə gözəl alqoritmin arxasında hansı fikir dayanır? İdeya sadədir: tutaq ki, çox zəif alqoritmimiz var, deyək ki, . Bu zəif alqoritmdən istifadə edərək çoxlu müxtəlif modellər düzəltsək və onların proqnozlarının nəticələrini orta hesabla götürsək, yekun nəticə xeyli yaxşı olar. Buna hərəkətdə ansambl öyrənmə deyilir. Təsadüfi Meşə alqoritmi buna görə də "Təsadüfi Meşə" adlanır; alınan məlumatlar üçün bir çox qərar ağacı yaradır və sonra onların proqnozlarının nəticəsini orta hesabla alır. Burada mühüm məqam hər bir ağacın yaranmasında təsadüf ünsürüdür. Axı, aydındır ki, bir çox eyni ağaclar yaratsaq, onların orta hesablanmasının nəticəsi bir ağacın dəqiqliyinə sahib olacaqdır.
O necə işləyir? Fərz edək ki, bəzi giriş məlumatlarımız var. Hər bir sütun hansısa parametrə, hər sətir hansısa məlumat elementinə uyğun gəlir.
Biz təsadüfi olaraq bütün verilənlər dəstindən müəyyən sayda sütun və sətir seçə və onların əsasında qərar ağacı qura bilərik.

10 may 2012-ci il, cümə axşamı
12 yanvar 2012-ci il, cümə axşamı

Hamısı budur. 17 saatlıq uçuş başa çatıb, Rusiya xaricdə qalır. Və rahat 2 otaqlı mənzilin pəncərəsindən San-Fransisko, məşhur Silikon Vadisi, Kaliforniya, ABŞ bizə baxır. Bəli, son vaxtlar çox yazmamağımın səbəbi budur. Biz köçdük.
Bütün bunlar 2011-ci ilin aprelində Zynga ilə telefonla müsahibəm zamanı başladı. Sonra hər şey reallıqla əlaqəsi olmayan bir növ oyun kimi görünürdü və bunun nəyə gətirib çıxaracağını təsəvvür belə edə bilmirdim. 2011-ci ilin iyununda Zynqa Moskvaya gələrək bir sıra müsahibələr keçirdi, telefon müsahibəsindən keçən 60-a yaxın namizədə baxıldı və onlardan 15-ə yaxın şəxs seçildi (dəqiq sayını bilmirəm, bəziləri sonradan fikrini dəyişdi, digərləri dərhal imtina etdi). Müsahibə təəccüblü dərəcədə sadə oldu. Proqramlaşdırma problemi yoxdur, lyukların forması ilə bağlı çətin suallar yoxdur, əsasən söhbət etmək qabiliyyətinizi sınayırsınız. Bilik isə, məncə, yalnız səthi qiymətləndirilib.
Və sonra rigmarole başladı. Əvvəlcə nəticələri, sonra təklifi, sonra LCA-nın təsdiqini, sonra viza ərizəsinin təsdiqini, sonra ABŞ-dan gələn sənədləri, sonra səfirlikdəki növbəni, sonra əlavə yoxlamanı, sonra vizanı gözlədik. Hərdən mənə elə gəlirdi ki, hər şeydən əl çəkib qol vurmağa hazıram. Hərdən şübhə edirdim ki, bizə bu Amerika lazım olub, axı Rusiya da pis deyil. Bütün proses təxminən altı ay çəkdi, nəhayət, dekabrın ortalarında biz viza aldıq və yola düşməyə hazırlaşmağa başladıq.
Bazar ertəsi mənim yeni yerdə ilk iş günüm idi. Ofisdə nəinki işləmək, hətta yaşamaq üçün hər bir şərait var. Öz aşpazlarımızdan səhər yeməyi, nahar və şam yeməkləri, hər küncdə doldurulmuş müxtəlif yeməklər, idman zalı, masaj və hətta bərbər. Bütün bunlar işçilər üçün tamamilə pulsuzdur. Bir çox insanlar işə velosipedlə gedirlər və bir neçə otaq nəqliyyat vasitələrinin saxlanması üçün təchiz edilmişdir. Ümumiyyətlə, mən Rusiyada belə bir şey görməmişəm. Bununla belə, hər şeyin öz qiyməti var, dərhal xəbərdarlıq edildi ki, çox işləməli olacağıq. Onların standartlarına görə, "çox"un nə olduğu mənə çox aydın deyil.
Ümid edirəm ki, işin çoxluğuna baxmayaraq, yaxın gələcəkdə bloq yazmağı davam etdirə və bəlkə də Amerika həyatı və Amerikada proqramçı kimi işləmək haqqında nəsə danışa biləcəyəm. Gözlə və gör. Bu arada hər kəsi Yeni İl və Milad bayramı münasibətilə təbrik edirəm və yenidən görüşərik!
İstifadə nümunəsi üçün dividend gəlirini çap edək rus şirkətləri. Baza qiymət olaraq reyestr bağlandığı gün səhmin bağlanış qiymətini götürürük. Nədənsə bu məlumat Troyka veb saytında mövcud deyil, lakin dividendlərin mütləq dəyərlərindən daha maraqlıdır.
Diqqət! Kodun icrası xeyli vaxt aparır, çünki... Hər bir promosyon üçün siz finam serverlərinə müraciət etməli və onun dəyərini əldə etməlisiniz.
Nəticə<- NULL for(i in (1:length(divs[,1]))){ d <- divs if (d$Divs>0)( cəhd edin(( sitatlar<- getSymbols(d$Symbol, src="Finam", from="2010-01-01", auto.assign=FALSE) if (!is.nan(quotes)){ price <- Cl(quotes) if (length(price)>0)(dd<- d$Divs result <- rbind(result, data.frame(d$Symbol, d$Name, d$RegistryDate, as.numeric(dd)/as.numeric(price), stringsAsFactors=FALSE)) } } }, silent=TRUE) } } colnames(result) <- c("Symbol", "Name", "RegistryDate", "Divs") result

Eynilə, siz əvvəlki illərin statistikasını qura bilərsiniz.
İnternetdə, o cümlədən Habré-də Kalman filtri haqqında çoxlu məlumat tapa bilərsiniz. Ancaq düsturların özləri üçün asanlıqla həzm olunan bir nəticə tapmaq çətindir. Nəticəsiz, bütün bu elm bir növ şamanizm kimi qəbul edilir, düsturlar simasız simvollar toplusuna bənzəyir, ən əsası isə nəzəriyyənin səthində yatan bir çox sadə ifadələr dərk olunmur. Bu məqalənin məqsədi bu filtr haqqında mümkün qədər əlçatan bir dildə danışmaq olacaq.
Kalman filtri güclü məlumat filtrləmə vasitəsidir. Onun əsas prinsipi ondan ibarətdir ki, filtrasiya hadisənin özünün fizikası haqqında məlumatlardan istifadə edir. Tutaq ki, əgər siz avtomobilin spidometrindən məlumatları süzürsünüzsə, o zaman avtomobilin ətaləti sizə sürətdə çox sürətli sıçrayışları ölçmə xətası kimi qəbul etmək hüququ verir. Kalman filtri maraqlıdır, çünki müəyyən mənada ən yaxşı filtrdir. "Ən yaxşı" sözlərinin tam olaraq nə demək olduğunu aşağıda daha ətraflı müzakirə edəcəyik. Məqalənin sonunda göstərəcəyəm ki, bir çox hallarda düsturları o dərəcədə sadələşdirmək olar ki, onlardan demək olar ki, heç nə qalmır.
Təhsil proqramı
Kalman filtri ilə tanışlıqdan əvvəl ehtimal nəzəriyyəsindən bəzi sadə tərifləri və faktları xatırlatmağı təklif edirəm.
Təsadüfi dəyər
Təsadüfi dəyişən verildiyini deyəndə, bu dəyərin təsadüfi qiymətlər ala biləcəyini nəzərdə tuturlar. Fərqli ehtimallarla fərqli dəyərlər alır. Siz yuvarladığınız zaman, məsələn, bir zərb, diskret dəyərlər dəsti görünəcək: . Məsələn, gəzən zərrəciyin sürətindən danışarkən, açıq-aydın, davamlı dəyərlər toplusu ilə məşğul olmalıyıq. Biz təsadüfi dəyişənin "çıxarılmış" dəyərlərini vasitəsilə işarə edəcəyik, lakin bəzən təsadüfi dəyişəni işarələdiyimiz hərfdən istifadə edəcəyik: .
Davamlı dəyərlər çoxluğu vəziyyətində, təsadüfi dəyişən ehtimal sıxlığı ilə xarakterizə olunur, bu da bizə təsadüfi dəyişənin uzunluq nöqtəsinin kiçik bir qonşuluğunda "düşməsi" ehtimalının -ə bərabər olduğunu diktə edir. Şəkildən göründüyü kimi, bu ehtimal qrafikin altındakı kölgəli düzbucaqlının sahəsinə bərabərdir:
Həyatda çox vaxt təsadüfi dəyişənlər ehtimal sıxlığı bərabər olduqda Gauss paylanır.
Görürük ki, funksiya bir nöqtədə mərkəzi olan zəng formasına və xarakterik sıra genişliyinə malikdir.
Gauss paylanmasından bəhs etdiyimiz üçün onun haradan gəldiyini qeyd etməmək ayıb olardı. Riyaziyyatda rəqəmlər möhkəm şəkildə qurulduğu və ən gözlənilməz yerlərdə tapıldığı kimi, Qauss paylanması da ehtimal nəzəriyyəsində dərin kök salmışdır. Qaussun hər yerdə mövcudluğunu qismən izah edən diqqətəlayiq ifadələrdən biri belədir:
İxtiyari paylanma ilə təsadüfi bir dəyişən olsun (əslində bu özbaşınalığa bəzi məhdudiyyətlər var, lakin onlar heç də sərt deyil). Təcrübələr aparaq və təsadüfi dəyişənin “çıxmış” dəyərlərinin cəmini hesablayaq. Gəlin çoxlu belə təcrübələr edək. Aydındır ki, hər dəfə məbləğin fərqli dəyərini alacağıq. Başqa sözlə, bu məbləğin özü özünəməxsus paylanma qanunu ilə təsadüfi dəyişəndir. Belə çıxır ki, kifayət qədər böyük olduqda, bu məbləğin paylanma qanunu Qauss paylanmasına meyllidir (yeri gəlmişkən, "zəngin" xarakterik eni kimi böyüyür). Vikipediyada daha ətraflı oxuyuruq: mərkəzi limit teoremi. Həyatda çox vaxt çox sayda eyni şəkildə paylanmış müstəqil təsadüfi dəyişənlərin cəmi olan kəmiyyətlər var və buna görə də onlar Gauss paylanmışdır.
Orta dəyər
Təsadüfi dəyişənin orta qiyməti, çoxlu təcrübələr aparsaq və atılan dəyərlərin arifmetik ortasını hesablasaq, limitdə əldə edəcəyimiz şeydir. Orta qiymət müxtəlif yollarla işarələnir: riyaziyyatçılar onu vasitəsilə (riyazi gözlənti), xarici riyaziyyatçılar isə (gözlənti) vasitəsilə işarə etməyi xoşlayırlar. Fiziklər vasitəsilə və ya. Biz onu xarici şəkildə təyin edəcəyik: .
Məsələn, Qauss paylanması üçün orta qiymətdir.
Dispersiya
Qauss paylanması vəziyyətində biz aydın görürük ki, təsadüfi dəyişən öz orta dəyərinin müəyyən qonşuluğuna düşməyə üstünlük verir. Qrafikdən göründüyü kimi, dəyərlərin xarakterik yayılması . Əgər paylanmasını bilsək, ixtiyari təsadüfi dəyişən üçün bu dəyərlərin yayılmasını necə qiymətləndirə bilərik? Siz onun ehtimal sıxlığının qrafikini çəkə və xarakterik genişliyi gözlə təxmin edə bilərsiniz. Amma biz cəbri yolla getməyə üstünlük veririk. Orta dəyərdən orta sapma uzunluğunu (modulu) tapa bilərsiniz: . Bu dəyər dəyərlərin xarakterik yayılmasının yaxşı qiymətləndirilməsi olacaqdır. Amma siz və mən çox yaxşı bilirik ki, düsturlarda modullardan istifadə etmək baş ağrısıdır, ona görə də bu düstur nadir hallarda xarakterik səpələnməni qiymətləndirmək üçün istifadə olunur.
Daha sadə bir yol (hesablamalar baxımından sadə) tapmaqdır. Bu kəmiyyət dispersiya adlanır və çox vaxt kimi işarələnir. Dispersiyanın kökü standart kənarlaşma adlanır. Standart sapma təsadüfi dəyişənin yayılmasının yaxşı qiymətləndirilməsidir.
Məsələn, Qauss paylanması üçün hesablaya bilərik ki, yuxarıda müəyyən edilmiş dispersiya tam olaraq --ə bərabərdir, yəni standart kənarlaşma - -ə bərabərdir, bu da həndəsi intuisiyamızla çox uyğundur.
Əslində burada kiçik bir fırıldaq gizlənir. Fakt budur ki, Qauss paylanmasının tərifində eksponentin altında bir ifadə var. Bu ikisi dəqiq məxrəcdədir ki, standart kənarlaşma əmsala bərabər olsun. Yəni, Qauss paylama düsturunun özü xüsusi hazırlanmış formada yazılıb ki, biz onun standart sapmasını hesablayaq.
Müstəqil təsadüfi dəyişənlər
Təsadüfi dəyişənlər asılı və ya olmaya bilər. Təsəvvür edin ki, təyyarəyə iynə atıb hər iki ucun koordinatlarını qeyd edin. Bu iki koordinat asılıdır; onlar təsadüfi dəyişənlər olsalar da, aralarındakı məsafənin həmişə iynənin uzunluğuna bərabər olması şərti ilə əlaqələndirilir.
Təsadüfi dəyişənlər, əgər birincinin nəticəsi ikincinin nəticəsindən tamamilə müstəqildirsə, müstəqildir. Əgər təsadüfi dəyişənlər müstəqildirlərsə, onda onların məhsulunun orta qiyməti onların orta qiymətlərinin hasilinə bərabərdir:
Sübut
Məsələn, mavi gözlərə sahib olmaq və məktəbi qızıl medalla bitirmək müstəqil təsadüfi dəyişənlərdir. Əgər mavi gözlülər, deyək ki, qızıl medalçılar, sonra mavi gözlü medalçılar.Bu misal bizə deyir ki, əgər təsadüfi dəyişənlər onların ehtimal sıxlığı ilə müəyyən edilirsə və , onda bu dəyərlərin müstəqilliyi ehtimal sıxlığı ilə ifadə olunur ( birinci dəyər atıldı və ikinci) düsturla tapılır:
Bundan dərhal belə çıxır:
Gördüyünüz kimi, sübut davamlı dəyərlər spektrinə malik olan və onların ehtimal sıxlığı ilə təyin olunan təsadüfi dəyişənlər üçün aparılmışdır. Digər hallarda sübut ideyası oxşardır.
Kalman filtri
Problemin formalaşdırılması
Ölçəcəyimiz və sonra filtrləyəcəyimiz dəyəri işarə edək. Bu, mövqe, sürət, sürətlənmə, rütubət, üfunət dərəcəsi, temperatur, təzyiq və s. ola bilər.
Sadə bir nümunə ilə başlayaq ki, bu da bizi ümumi problemin formalaşdırılmasına aparacaq. Təsəvvür edin ki, radio ilə idarə olunan avtomobilimiz yalnız irəli və geri gedə bilir. Biz avtomobilin çəkisini, formasını, yol səthini və s.-i bilə-bilə idarəetmə joystiğinin hərəkət sürətinə necə təsir etdiyini hesabladıq.
Sonra avtomobilin koordinatları qanuna uyğun olaraq dəyişəcək:
Real həyatda biz hesablamalarımızda avtomobilə təsir edən kiçik pozuntuları (külək, qabar, yolda çınqıllar) nəzərə ala bilmirik, ona görə də avtomobilin real sürəti hesablanmış sürətdən fərqli olacaq. Yazılı tənliyin sağ tərəfinə təsadüfi dəyişən əlavə olunacaq:
Bizdə avtomobilin üzərində GPS sensoru quraşdırılıb, o, avtomobilin həqiqi koordinatını ölçməyə çalışır və təbii ki, onu dəqiq ölçə bilmir, ancaq səhvlə ölçür, bu da təsadüfi dəyişəndir. Nəticədə sensordan səhv məlumatlar alırıq:
Tapşırıq ondan ibarətdir ki, səhv sensor oxunuşlarını bilərək, avtomobilin həqiqi koordinatı üçün yaxşı bir təxmini tapın.
Ümumi problemin tərtibində hər şey koordinata görə cavabdeh ola bilər (temperatur, rütubət...) və biz sistemin xaricdən idarə olunmasına cavabdeh olan üzvü (maşınla olan nümunədə) kimi işarə edəcəyik. Koordinatlar və sensor oxunuşları üçün tənliklər belə görünəcək:
Gəlin bildiklərimizi ətraflı müzakirə edək:
Qeyd etmək lazımdır ki, filtrləmə tapşırığı hamarlaşdırma işi deyil. Biz sensor məlumatlarını hamarlaşdırmağa çalışmırıq, real koordinata ən yaxın dəyəri əldə etməyə çalışırıq.
Kalman alqoritmi
Biz induksiya ilə mübahisə edəcəyik. Təsəvvür edin ki, ci addımda biz artıq sensordan sistemin həqiqi koordinatına yaxın olan süzülmüş dəyər tapmışıq. Unutmayın ki, naməlum koordinatın dəyişməsini idarə edən tənliyi bilirik:
Buna görə də, hələ sensordan dəyəri almadan, addımda sistemin bu qanuna uyğun olaraq inkişaf edəcəyini və sensorun -ə yaxın bir şey göstərəcəyini güman edə bilərik. Təəssüf ki, hələlik daha dəqiq bir şey deyə bilmərik. Digər tərəfdən, addım zamanı əllərimizdə qeyri-dəqiq sensor oxunması olacaq.
Kalmanın fikri belədir. Həqiqi koordinata ən yaxşı yaxınlaşmanı əldə etmək üçün sensorun qeyri-dəqiq oxunması ilə onun görməsini gözlədiyimiz proqnoz arasında orta yer seçməliyik. Sensorun oxunmasına çəki verəcəyik və çəki proqnozlaşdırılan dəyərdə qalacaq:
Bu əmsal Kalman əmsalı adlanır. Bu, iterasiya addımından asılıdır, ona görə də yazmaq daha düzgün olardı, lakin hələlik hesablama düsturlarını qarışdırmamaq üçün onun indeksini buraxacağıq.
Kalman əmsalını elə seçməliyik ki, nəticədə alınan optimal koordinat dəyəri həqiqi qiymətə ən yaxın olsun. Məsələn, sensorumuzun çox dəqiq olduğunu bilsək, onun oxunmasına daha çox güvənirik və dəyəri daha çox çəki (birə yaxın) veririk. Sensor, əksinə, heç də dəqiq deyilsə, nəzəri olaraq proqnozlaşdırılan dəyərə daha çox diqqət yetirəcəyik.
Ümumiyyətlə, Kalman əmsalının dəqiq dəyərini tapmaq üçün səhvi minimuma endirmək kifayətdir:
Səhv üçün ifadəni yenidən yazmaq üçün (1) tənliklərindən (çərçivədəki mavi fonda olanlar) istifadə edirik:
Sübut
İndi səhvi minimuma endirən ifadənin nə demək olduğunu müzakirə etməyin vaxtıdır? Axı, səhv, gördüyümüz kimi, təsadüfi bir dəyişəndir və hər dəfə fərqli dəyərlər alır. Minimum xətanın nə demək olduğunu müəyyən etmək üçün həqiqətən hamıya uyğun bir yanaşma yoxdur. Təsadüfi dəyişənin dispersiyası vəziyyətində olduğu kimi, onun dispersiyasının xarakterik genişliyini qiymətləndirməyə çalışdığımız zaman burada hesablamalar üçün ən sadə meyar seçəcəyik. Kvadrat səhvin ortasını minimuma endirəcəyik:
Son ifadəni yazaq:
Sübut
İfadəyə daxil olan bütün təsadüfi dəyişənlərin müstəqil olmasından belə nəticə çıxır ki, bütün “çarpaz” şərtlər sıfıra bərabərdir:
Biz ondan istifadə etdik ki, onda dispersiya düsturu daha sadə görünür: .
Bu ifadə o zaman minimum dəyər alır (törəməni sıfıra bərabərləşdiririk):
Burada biz artıq Kalman əmsalı üçün addım indeksi ilə ifadə yazırıq və bununla da onun iterasiya addımından asılı olduğunu vurğulayırıq.
Nəticədə alınan optimal dəyəri minimuma endirdiyimiz ifadə ilə əvəz edirik. alırıq;
Problemimiz həll olundu. Kalman əmsalını hesablamaq üçün iterativ düstur əldə etdik.
Gəlin əldə etdiyimiz bilikləri bir çərçivədə ümumiləşdirək:
Misal
Matlab kodu
Hamısını sil, hamısını təmizlə; N=100% nümunə sayı a=0.1% sürətlənmə sigmaPsi=1 sigmaEta=50; k=1:N x=k x(1)=0 z(1)=x(1)+normrnd(0,sigmaEta); t=1 üçün:(N-1) x(t+1)=x(t)+a*t+normrnd(0,sigmaPsi); z(t+1)=x(t+1)+normrnd(0,sigmaEta); son; %kalman filter xOpt(1)=z(1); eOpt(1)=sigmaEta; t=1 üçün:(N-1) eOpt(t+1)=sqrt((sigmaEta^2)*(eOpt(t)^2+sigmaPsi^2)/(sigmaEta^2+eOpt(t)^2+ sigmaPsi^2)) K(t+1)=(eOpt(t+1))^2/sigmaEta^2 xOpt(t+1)=(xOpt(t)+a*t)*(1-K(t) +1))+K(t+1)*z(t+1) sonu; süjet(k,xOpt,k,z,k,x)
Təhlil
Kalman əmsalının iterasiya addımları ilə necə dəyişdiyini izləsəniz, onun həmişə müəyyən bir dəyərə sabitləşdiyini göstərə bilərsiniz. Məsələn, sensorun və modelin orta kvadrat səhvləri onla bir nisbətə malik olduqda, iterasiya addımından asılı olaraq Kalman əmsalının qrafiki belə görünür:
Aşağıdakı nümunədə bunun həyatımızı necə asanlaşdıra biləcəyini müzakirə edəcəyik.
İkinci misal
Təcrübədə tez-tez olur ki, biz süzgəcdən keçirdiklərimizin fiziki modeli haqqında heç nə bilmirik. Məsələn, siz sevdiyiniz akselerometrdən oxunuşları süzgəcdən keçirmək istəyirdiniz. Siz akselerometri hansı qanunla döndərmək istədiyinizi əvvəlcədən bilmirsiniz. Toplaya biləcəyiniz ən çox məlumat sensor xətası fərqidir. Belə bir çətin vəziyyətdə, hərəkət modelinin bütün cəhaləti təsadüfi bir dəyişənə yönəldilə bilər:
Lakin, açığını desəm, belə bir sistem artıq təsadüfi dəyişənə qoyduğumuz şərtləri ödəmir, çünki indi bütün naməlum hərəkət fizikası orada gizlənir və buna görə də biz deyə bilmərik ki, zamanın müxtəlif anlarında model xətaları müstəqildir. bir-birinə və onların orta dəyərləri sıfıra bərabərdir. Bu halda, ümumiyyətlə, Kalman filtr nəzəriyyəsi tətbiq olunmur. Lakin, biz bu fakta diqqət yetirməyəcəyik, lakin süzülmüş məlumatların gözəl görünməsi üçün əmsalları gözlə seçərək, bütün böyük düsturları axmaqcasına tətbiq edəcəyik.
Ancaq fərqli, daha sadə bir yol tuta bilərsiniz. Yuxarıda gördüyümüz kimi, Kalman əmsalı həmişə artdıqca dəyərə sabitləşir. Buna görə də əmsalları seçmək və mürəkkəb düsturlardan istifadə edərək Kalman əmsalını tapmaq əvəzinə bu əmsalı həmişə sabit hesab edib yalnız bu sabiti seçə bilərik. Bu fərziyyə demək olar ki, heç nəyi pozmayacaq. Birincisi, biz artıq qeyri-qanuni olaraq Kalman nəzəriyyəsindən istifadə edirik, ikincisi, Kalman əmsalı sürətlə sabitləşir. Sonda hər şey daha sadə olacaq. Bizə ümumiyyətlə Kalmanın nəzəriyyəsindən heç bir düstur lazım deyil, sadəcə olaraq məqbul dəyəri seçib onu iterativ düstura daxil etməliyik:
Aşağıdakı qrafik uydurma sensordan iki fərqli şəkildə süzülmüş məlumatları göstərir. Bir şərtlə ki, hadisənin fizikası haqqında heç nə bilməsək. Birinci üsul Kalmanın nəzəriyyəsindəki bütün düsturlarla dürüstdür. İkincisi isə düsturlar olmadan sadələşdirilmişdir.
Gördüyümüz kimi, üsullar demək olar ki, fərqlənmir. Kiçik bir fərq yalnız Kalman əmsalı hələ sabitləşməmiş başlanğıcda müşahidə olunur.
Müzakirə
Gördüyümüz kimi, Kalman filtrinin əsas ideyası süzülmüş dəyərə uyğun əmsal tapmaqdır
orta hesabla, koordinatın real dəyərindən ən az fərqlənəcək. Biz görürük ki, süzülmüş dəyər sensorun oxunuşunun və əvvəlki süzülmüş dəyərin xətti funksiyasıdır. Və əvvəlki süzülmüş dəyər, öz növbəsində, sensorun oxunmasının və əvvəlki filtrlənmiş dəyərin xətti funksiyasıdır. Zəncir tamamilə dönənə qədər və s. Yəni süzülmüş dəyər asılıdır hər kəsəvvəlki sensor oxunuşları xətti olaraq:
Buna görə də Kalman filtri xətti filtr adlanır.
Sübut edilə bilər ki, bütün xətti filtrlərdən Kalman filtri ən yaxşısıdır. Ən yaxşısı o mənada ki, filtrin orta kvadrat xətası minimaldır.
Çoxölçülü hal
Kalman filtrinin bütün nəzəriyyəsi çoxölçülü vəziyyətə ümumiləşdirilə bilər. Oradakı düsturlar bir az daha qorxulu görünür, lakin onları əldə etmək ideyası birölçülü vəziyyətdə olduğu kimidir. Onları bu gözəl məqalədə görə bilərsiniz: http://habrahabr.ru/post/140274/.
Və bu gözəldə video Onlardan necə istifadə olunacağına dair bir nümunə verilmişdir.