Analýza velkých objemů dat. Big Data Machine. Škálování a vrstvení
Na základě materiálů z výzkumu a trendů
O velkých datech se v IT a marketingovém tisku mluví již několik let. A je to jasné: digitální technologie pronikly do života moderní muž"Všechno je napsáno." Roste objem dat o různých aspektech života a zároveň rostou možnosti pro ukládání informací.
Globální technologie pro ukládání informací
Zdroj: Hilbert a Lopez, „Světová technologická kapacita pro ukládání, komunikaci a výpočet informací“, Science, 2011 Global.
Většina odborníků se shoduje, že zrychlení růstu dat je objektivní realitou. Sociální sítě, mobilní zařízení, data z měřicích zařízení, obchodní informace – to je jen několik typů zdrojů, které mohou generovat gigantické objemy informací. Podle studie IDCDigitální vesmír, zveřejněné v roce 2012, v příštích 8 letech dosáhne množství dat na světě 40 ZB (zettabajtů), což odpovídá 5200 GB na každého obyvatele planety.
Růst shromažďování digitálních informací v USA

Zdroj: IDC
Významnou část informací nevytvářejí lidé, ale roboti interagující jak mezi sebou, tak s jinými datovými sítěmi – jako jsou např. chytrých zařízení. Při tomto tempu růstu se množství dat ve světě podle výzkumníků každý rok zdvojnásobí. Počet virtuálních a fyzické servery na světě se zdesetinásobí díky rozšiřování a vytváření nových datových center. V důsledku toho roste potřeba tato data efektivně využívat a zpeněžit. Protože používání velkých dat v podnikání vyžaduje značné investice, musíte situaci jasně porozumět. A je to v podstatě jednoduché: efektivitu podnikání můžete zvýšit snížením nákladů a/nebo zvýšením objemu prodeje.
Proč potřebujeme velká data?
Paradigma velkých dat definuje tři hlavní typy problémů.
- Ukládání a správa stovek terabajtů nebo petabajtů dat, která konvenční relační databáze nemohou efektivně využít.
- Uspořádejte nestrukturované informace sestávající z textů, obrázků, videí a dalších typů dat.
- Big Data analýza, která nastoluje otázku způsobů práce s nestrukturovanými informacemi, generování analytických reportů a také implementaci prediktivních modelů.
Trh projektů Big Data se prolíná s trhem business analytics (BA), jehož celosvětový objem podle odborníků v roce 2012 činil asi 100 miliard dolarů. Zahrnuje komponenty síťových technologií, servery, software a technické služby.
Využití technologií Big Data je také relevantní pro řešení třídy pojištění příjmů (RA), která jsou určena k automatizaci činností společností. Moderní systémy garance příjmu zahrnují nástroje pro odhalování nesrovnalostí a hloubkovou analýzu dat, umožňující včasné odhalení případných ztrát nebo zkreslení informací, které by mohly vést ke snížení finančních výsledků. Na tomto pozadí ruské společnosti, potvrzující přítomnost poptávky po technologiích Big Data na domácím trhu, poznamenávají, že faktory, které stimulují rozvoj Big Data v Rusku, jsou růst dat, zrychlení rozhodování managementu a zlepšení jejich kvality.
Co vám brání pracovat s velkými daty
Dnes je analyzováno pouze 0,5 % nashromážděných digitálních dat, a to navzdory skutečnosti, že objektivně existují celoodvětvové problémy, které lze vyřešit pomocí analytická řešení Třída Big Data. Vyspělé IT trhy již mají výsledky, které lze použít k vyhodnocení očekávání spojených s akumulací a zpracováním velkých dat.
Zvažuje se kromě vysoké ceny jeden z hlavních faktorů, který zpomaluje realizaci projektů Big Data problém výběru zpracovávaných dat: to znamená určení, která data je třeba načíst, uložit a analyzovat a která by měla být ignorována.
Mnoho obchodních zástupců poznamenává, že potíže s implementací projektů Big Data jsou spojeny s nedostatkem specialistů - obchodníků a analytiků. Rychlost návratnosti investic do Big Data přímo závisí na kvalitě práce zaměstnanců zabývajících se hloubkovou a prediktivní analýzou. Obrovský potenciál dat, která již v organizaci existují, často nemohou sami marketéři efektivně využít kvůli zastaralým obchodním procesům nebo interním předpisům. Proto jsou projekty Big Data podniky často vnímány jako náročné nejen na implementaci, ale také na vyhodnocení výsledků: hodnoty shromážděných dat. Specifická povaha práce s daty vyžaduje, aby obchodníci a analytici přeorientovali svou pozornost od technologie a vytváření sestav k řešení konkrétních obchodních problémů.
Vzhledem k velkému objemu a vysoká rychlost tok dat, proces jejich sběru zahrnuje ETL procedury v reálném čase. Pro referenci:ETL - zAngličtinaVýpis, Přeměnit, Zatížení- doslova "extrahování, transformace, načítání") - jeden z hlavních procesů v řízení datové sklady, kam patří: získávání dat z externí zdroje, jejich transformace a čištění podle potřeb Na ETL je třeba nahlížet nejen jako na proces přesouvání dat z jedné aplikace do druhé, ale také jako na nástroj pro přípravu dat k analýze.
A pak otázky zajištění bezpečnosti dat přicházejících z externích zdrojů musí mít řešení, která odpovídají objemu shromážděných informací. Vzhledem k tomu, že metody analýzy velkých dat se vyvíjejí až po růstu objemu dat, hraje velkou roli schopnost analytických platforem využívat nové metody přípravy a agregace dat. To naznačuje, že například data o potenciálních kupcích nebo masivní datový sklad s historií prokliků na stránkách online nakupování mohou být zajímavá pro řešení různých problémů.
Potíže neustávají
Přes všechny potíže se zaváděním Big Data hodlá firma zvýšit investice do této oblasti. Jak vyplývá z dat Gartneru, v roce 2013 již 64 % největších světových společností investovalo nebo má v plánu investovat do nasazení Big Data technologií pro svůj byznys, zatímco v roce 2012 to bylo 58 %. Podle výzkumu společnosti Gartner jsou lídry v odvětvích investujících do velkých dat mediální společnosti, telekomunikace, bankovnictví a společnosti poskytující služby. Úspěšných výsledků z implementace Big Data již dosáhlo mnoho významných hráčů v maloobchodě, pokud jde o využití dat získaných pomocí nástrojů radiofrekvenční identifikace, logistických a relokačních systémů. doplňování- akumulace, doplňování - R&T), jakož i z věrnostních programů. Úspěšné maloobchodní zkušenosti podněcují další tržní sektory k hledání nových efektivní způsoby monetizace velkých dat, aby se jejich analýza stala zdrojem, který funguje pro rozvoj podnikání. Díky tomu se podle odborníků v období do roku 2020 sníží investice do správy a úložiště na gigabajt dat z 2 USD na 0,2 USD, ale na studium a analýzu technologických vlastností Big Data vzrostou pouze o 40 %.
Náklady jsou uvedeny v různých investiční projekty v oblasti Big Data, mají jinou povahu. Nákladové položky závisí na typech produktů, které jsou vybírány na základě určitých rozhodnutí. Největší část nákladů v investičních akcích podle odborníků připadá na produkty související se sběrem, strukturováním dat, úklidem a správou informací.
Jak se to dělá
Existuje mnoho kombinací softwaru a Hardware, které umožňují vytvářet efektivní řešení Big Data pro různé obory podnikání: ze sociálních médií a mobilní aplikace, před prediktivní analýza a vizualizace obchodních dat. Důležitou výhodou Big Data je kompatibilita nových nástrojů s databázemi široce používanými v podnikání, což je zvláště důležité při práci s mezioborovými projekty, jako je organizace vícekanálového prodeje a zákaznická podpora.
Sekvence práce s velkými daty se skládá ze shromažďování dat, strukturování přijatých informací pomocí sestav a dashboardů, vytváření přehledů a kontextů a formulování doporučení pro akci. Vzhledem k tomu, že práce s velkými daty obnáší velké náklady na sběr dat, jejichž výsledek zpracování není předem znám, je hlavním úkolem jasně porozumět tomu, k čemu data slouží, a ne kolik jich je k dispozici. Sběr dat se v tomto případě mění v proces získávání informací výhradně nezbytných pro řešení konkrétních problémů.
Například poskytovatelé telekomunikačních služeb agregují obrovské množství dat, včetně geolokace, která se neustále aktualizuje. Tyto informace mohou být komerčně zajímavé pro reklamní agentury, které je mohou používat k poskytování cílené a místní reklamy, a také pro maloobchodníky a banky. Taková data mohou hrát důležitou roli při rozhodování o otevření maloobchodní prodejny v určité lokalitě na základě údajů o přítomnosti silného cíleného toku lidí. Existuje příklad měření efektivity reklamy na venkovních billboardech v Londýně. Nyní lze dosah takové reklamy měřit pouze umístěním lidí se speciálním zařízením v blízkosti reklamních staveb, které počítají kolemjdoucí. V porovnání s tímto typem měření účinnosti reklamy mobilního operátora mnohem více možností - zná přesně polohu svých odběratelů, zná jejich demografické charakteristiky, pohlaví, věk, rodinný stav atd.
Na základě těchto údajů je v budoucnu výhled na změnu obsahu reklamního sdělení s využitím preferencí konkrétní osoby procházející kolem billboardu. Pokud data ukazují, že kolemjdoucí člověk hodně cestuje, pak by se mu mohla zobrazit reklama na letovisko. Pořadatelé fotbalového utkání mohou počet fanoušků pouze odhadovat, když na zápas přijdou. Pokud by ale měli možnost si u operátora vyžádat mobilní komunikace informace o tom, kde byli návštěvníci hodinu, den nebo měsíc před zápasem, by pořadatelům umožnily naplánovat místa pro inzerci příštích zápasů.
Dalším příkladem je, jak mohou banky používat Big Data k zabránění podvodům. Pokud klient nahlásí ztrátu karty a při nákupu s ní banka vidí v reálném čase polohu klientova telefonu v nákupní oblasti, kde probíhá transakce, může si informace ověřit v klientské aplikaci aby zjistil, jestli se ho nesnaží oklamat. Nebo naopak, když klient nakoupí v obchodě, banka vidí, že karta použitá k transakci a telefon klienta jsou na stejném místě, může dojít k závěru, že ji používá majitel karty. Díky takovým výhodám Big Data se rozšiřují hranice tradičních datových skladů.
Aby se společnost úspěšně rozhodla implementovat řešení Big Data, musí spočítat investiční případ, což způsobuje velké potíže kvůli mnoha neznámým komponentům. Paradoxem analytiků je v takových případech předpovídání budoucnosti na základě minulosti, o které často chybí údaje. V tomto případě je důležitým faktorem jasné plánování vašich počátečních akcí:
- Nejprve je nutné určit jeden konkrétní obchodní problém, pro který budou Big Data technologie použity, tento úkol se stane jádrem určení správnosti zvoleného konceptu. Musíte se zaměřit na sběr dat souvisejících s tímto konkrétním úkolem a během proof of concept můžete využít různé nástroje, procesy a techniky řízení, které vám v budoucnu umožní dělat informovanější rozhodnutí.
- Za druhé, je nepravděpodobné, že společnost bez znalostí a zkušeností v oblasti analýzy dat bude schopna úspěšně implementovat projekt Big Data. Potřebné znalosti vždy vycházejí z předchozích analytických zkušeností, které jsou hlavním faktorem ovlivňujícím kvalitu práce s daty. Kultura používání dat hraje důležitou roli, protože analýza informací často odhalí krutá pravda o podnikání a k přijetí této pravdy a práci s ní jsou nezbytné vyvinuté metody práce s daty.
- Za třetí, hodnota Big Data technologií spočívá v poskytování náhledů. Dobrých analytiků je na trhu stále nedostatek. Obvykle se jim říká specialisté, kteří hluboce rozumí komerčnímu významu dat a vědí, jak je správně používat. Analýza dat je prostředkem k dosažení obchodních cílů a abyste pochopili hodnotu velkých dat, musíte se podle toho chovat a rozumět svým akcím. V tomto případě hodně poskytnou velká data užitečné informace o spotřebitelích, na jejichž základě lze činit rozhodnutí užitečná pro podnikání.
Přestože se ruský Big Data trh teprve začíná formovat, jednotlivé projekty v této oblasti se již poměrně úspěšně realizují. Některé z nich jsou úspěšné v oblasti sběru dat, jako jsou projekty pro Federální daňovou službu a Tinkoff Credit Systems Bank, jiné - z hlediska analýzy dat a praktické aplikace jejích výsledků: jde o projekt Synqera.
Tinkoff Credit Systems Bank realizovala projekt implementace platformy EMC2 Greenplum, což je nástroj pro masivně paralelní výpočty. Banka v posledních letech zvýšila požadavky na rychlost zpracování nashromážděných informací a analýzy dat v reálném čase, což je způsobeno vysokým tempem růstu počtu uživatelů. kreditní karty. Banka oznámila plány na rozšíření využití technologií Big Data, zejména pro zpracování nestrukturovaných dat a práci s nimi Informace o společnosti získané z různých zdrojů.
Federální daňová služba Ruska v současné době vytváří analytickou vrstvu pro federální datový sklad. Na jejím základě singl informační prostor a technologie pro přístup k daňovým údajům pro statistické a analytické zpracování. Během realizace projektu probíhají práce na centralizaci analytických informací z více než 1200 zdrojů na místní úrovni Federální daňové služby.
Ještě jeden zajímavý příklad analýzou velkých dat v reálném čase je ruský startup Synqera, který vyvinul platformu Simplate. Řešení je založeno na zpracování velkého množství dat, program analyzuje informace o zákaznících, historii jejich nákupů, věk, pohlaví a dokonce i náladu. U pokladen v řetězci kosmetických obchodů byly instalovány dotykové obrazovky se senzory, které rozpoznávají emoce zákazníků. Program zjišťuje náladu člověka, analyzuje informace o něm, určuje denní dobu a skenuje databázi slev obchodu, načež odešle kupujícímu cílené zprávy o akcích a speciální nabídky. Toto řešení zvyšuje loajalitu zákazníků a zvyšuje tržby maloobchodníků.
Pokud se budeme bavit o zahraničních úspěšných případech, pak jsou v tomto ohledu zajímavé zkušenosti s používáním Big Data technologií ve společnosti Dunkin`Donuts, která k prodeji produktů využívá data v reálném čase. Digitální displeje v obchodech zobrazují nabídky, které se mění každou minutu v závislosti na denní době a dostupnosti produktu. Pomocí pokladních dokladů společnost získává údaje o tom, které nabídky zaznamenaly největší odezvu u zákazníků. Tento přístup ke zpracování dat nám umožnil zvýšit zisky a obrat zboží ve skladu.
Jak ukazují zkušenosti s implementací Big Data projektů, tato oblast je navržena tak, aby úspěšně řešila moderní obchodní problémy. Důležitým faktorem při dosahování komerčních cílů při práci s velkými daty je přitom výběr správné strategie, která zahrnuje analýzy, které identifikují požadavky spotřebitelů, a také využití inovativní technologie v oblasti Big Data.
Podle celosvětového průzkumu, který od roku 2012 každoročně mezi firemními obchodníky provádí společnosti Econsultancy a Adobe, mohou „velká data“, která charakterizují jednání lidí na internetu, udělat hodně. Mohou optimalizovat offline obchodní procesy, pomoci pochopit, jak je majitelé mobilních zařízení používají k vyhledávání informací, nebo jednoduše „vylepšit marketing“, tzn. Efektivnější. Poslední jmenovaná funkce je navíc rok od roku stále populárnější, jak vyplývá z námi prezentovaného diagramu.
Hlavní oblasti práce internetových marketérů z hlediska vztahů se zákazníky

Zdroj: Econsultancy a Adobe, publikováno– emarketer.com
Všimněte si, že národnost respondentů velký význam nemá. Jak ukazuje průzkum společnosti KPMG v roce 2013, podíl „optimistů“, tzn. těch, kteří při vývoji obchodní strategie využívají velká data, je 56 % a rozdíly mezi regiony jsou malé: od 63 % v severoamerických zemích po 50 % v EMEA.
Použití velkých dat v různých oblastech světa

Zdroj: KPMG, publikováno– emarketer.com
Mezitím postoj marketérů k takovým „módním trendům“ poněkud připomíná známý vtip:
Řekni mi, Vano, máš rád rajčata?
- Rád jím, ale ne takhle.
Navzdory skutečnosti, že marketéři verbálně „milují“ Big Data a zdá se, že je i používají, ve skutečnosti je „všechno komplikované“, jak píší o své srdečné náklonnosti na sociálních sítích.
Podle průzkumu, který provedla společnost Circle Research v lednu 2014 mezi evropskými marketéry, 4 z 5 respondentů Big Data nepoužívají (i když je samozřejmě „milují“). Důvody jsou různé. Zarytých skeptiků je málo – 17 % a přesně stejný počet jako jejich antipodů, tzn. ti, kteří sebevědomě odpovídají: „Ano“. Zbytek váhá a pochybuje, „bažina“. Vyhýbají se přímé odpovědi pod věrohodnými záminkami jako „zatím ne, ale brzy“ nebo „počkáme, až začnou ostatní“.
Využití velkých dat obchodníky, Evropa, leden 2014

Zdroj:dnx, zveřejněno -emarketer.com
Co je mate? Čistý nesmysl. Někteří (přesně polovina z nich) těmto údajům prostě nevěří. Pro ostatní (také je jich poměrně dost – 55 %) je obtížné vzájemně korelovat soubory „dat“ a „uživatelů“. Někteří lidé prostě mají (politicky správně řečeno) vnitřní firemní nepořádek: data bez dozoru putují mezi marketingovými odděleními a IT strukturami. Pro ostatní se software nedokáže vyrovnat s přívalem práce. A tak dále. Vzhledem k tomu, že celkové podíly výrazně přesahují 100 %, je zřejmé, že situace „vícenásobných bariér“ není neobvyklá.
Bariéry využití Big Data v marketingu

Zdroj:dnx, zveřejněno -emarketer.com
Musíme tedy uznat, že „Big Data“ jsou prozatím velkým potenciálem, který je třeba ještě využít. To mimochodem může být důvodem, proč Big Data ztrácejí aureolu „módního trendu“, jak dokazuje průzkum společnosti Econsultancy, o kterém jsme se již zmiňovali.
Nejvýraznější trendy v digitálním marketingu 2013-2014

Zdroj: Ecosultancy a Adobe
Nahrazuje je jiný král – content marketing. Jak dlouho?
Nedá se říci, že by Big Data byla nějakým zásadně novým fenoménem. Velké zdroje dat existují již mnoho let: databáze o zákaznických nákupech, úvěrové historii, životním stylu. A po celá léta vědci tato data používali k tomu, aby pomáhali společnostem posuzovat rizika a předpovídat budoucí potřeby zákazníků. Dnes se však situace změnila ve dvou aspektech:
Objevily se sofistikovanější nástroje a techniky pro analýzu a kombinování různých souborů dat;
Tyto analytické nástroje jsou doplněny lavinou nových zdrojů dat poháněných digitalizací prakticky všech metod sběru dat a měření.
Rozsah dostupných informací je inspirativní a skličující pro výzkumníky vyrůstající ve strukturovaném výzkumném prostředí. Spotřebitelský sentiment zachycují webové stránky a všechny druhy sociálních médií. Skutečnost prohlížení reklamy je zaznamenána nejen set-top boxy, ale také pomocí digitálních značek a mobilní zařízení komunikaci s televizí.
Údaje o chování (jako je objem hovorů, nákupní zvyklosti a nákupy) jsou nyní k dispozici v reálném čase. Mnoho z toho, co bylo dříve možné získat výzkumem, se tedy nyní dá naučit pomocí zdrojů velkých dat. A všechna tato informační aktiva jsou generována neustále, bez ohledu na jakékoli výzkumné procesy. Tyto změny nás nutí přemýšlet, zda velká data mohou nahradit klasický průzkum trhu.
Nejde o data, ale o otázky a odpovědi.
Než zazní umíráček klasickému výzkumu, musíme si připomenout, že kritická není přítomnost určitých datových aktiv, ale něco jiného. Co přesně? Naše schopnost odpovídat na otázky, to je ono. Jedna legrační věc na novém světě velkých dat je, že výsledky získané z nových datových aktiv vedou k ještě větším otázkám a tyto otázky obvykle nejlépe zodpoví tradiční výzkum. Jak tedy velká data rostou, vidíme paralelní nárůst dostupnosti a potřeby „malých dat“, která mohou poskytnout odpovědi na otázky ze světa velkých dat.
Zvažte situaci: velký inzerent nepřetržitě monitoruje provoz obchodu a objem prodeje v reálném čase. Stávající metodiky výzkumu (ve kterých provádíme průzkumy panelistů ohledně jejich nákupní motivace a chování v místě prodeje) nám pomáhají lépe cílit na konkrétní segmenty kupujících. Tyto techniky lze rozšířit tak, aby zahrnovaly širší škálu velkých datových aktiv až do bodu, kdy se velká data stávají prostředkem pasivního pozorování a výzkum se stává metodou průběžného, úzce zaměřeného zkoumání změn nebo událostí, které vyžadují studium. Tak mohou velká data osvobodit výzkum od zbytečné rutiny. Primární výzkum se již nemusí zaměřovat na to, co se děje (k tomu poslouží velká data). Místo toho se primární výzkum může zaměřit na vysvětlení, proč pozorujeme konkrétní trendy nebo odchylky od trendů. Výzkumník bude moci méně přemýšlet o získávání dat a více o tom, jak je analyzovat a používat.
Zároveň vidíme, že velká data mohou vyřešit jeden z našich největších problémů: problém příliš dlouhých studií. Zkoumání samotných studií ukázalo, že přehnané výzkumné nástroje mají negativní dopad na kvalitu dat. Přestože mnozí odborníci tento problém již dlouho připouštěli, vždy odpověděli větou: „Ale potřebuji tyto informace pro vrcholové vedení,“ a dlouhé rozhovory pokračovaly.
Ve světě velkých dat, kde lze kvantitativní metriky získat pasivním pozorováním, se tento problém stává diskutabilním. Znovu se zamysleme nad všemi těmito studiemi ohledně spotřeby. Pokud nám velká data umožňují nahlédnout do spotřeby prostřednictvím pasivního pozorování, pak výzkum primárního průzkumu již nepotřebuje shromažďovat tento druh informací a můžeme konečně podpořit naši vizi krátkých průzkumů něčím víc než jen zbožným přáním.
Big Data potřebují vaši pomoc
Konečně, „velký“ je pouze jednou z charakteristik velkých dat. Znak „velký“ označuje velikost a měřítko dat. To je samozřejmě hlavní charakteristika, protože objem těchto dat přesahuje vše, s čím jsme dosud pracovali. Důležité jsou ale i další charakteristiky těchto nových datových toků: často jsou špatně formátované, nestrukturované (nebo v lepším případě částečně strukturované) a plné nejistoty. Vznikající oblast správy dat, příhodně nazvaná analytika entit, řeší problém odstranění šumu ve velkých datech. Jeho úkolem je analyzovat tyto datové soubory a zjistit, kolik pozorování se týká stejné osoby, která pozorování jsou aktuální a která jsou použitelná.
Tento typ čištění dat je nezbytný pro odstranění šumu nebo chybných dat při práci s velkými nebo malými datovými aktivy, ale není dostačující. Musíme také vytvořit kontext kolem aktiv velkých dat na základě našich předchozích zkušeností, analýz a znalostí kategorií. Ve skutečnosti mnoho analytiků poukazuje na schopnost zvládat nejistotu vlastní velkým datům jako na zdroj konkurenční výhody, protože umožňuje přijímat lepší rozhodnutí.
Zde se primární výzkum nejen osvobozuje od velkých dat, ale také přispívá k vytváření obsahu a analýze v rámci velkých dat.
Skvělým příkladem toho je aplikace našeho nového zásadně odlišného rámce hodnoty značky na sociální média (hovoříme o rozvinutém vMillward Hnědýnový přístup k měření hodnoty značkyThe Smysluplně Odlišný Rámec– „Paradigma smysluplných rozdílů“ -R & T ). Model je behaviorálně testován na konkrétních trzích, implementován na standardní bázi a lze jej snadno aplikovat na další marketingové vertikály a informační systémy pro podporu rozhodování. Jinými slovy, náš model hodnoty značky, založený na průzkumu (i když ne výlučně na základě), má všechny funkce potřebné k překonání nestrukturované, nesouvislé a nejisté povahy velkých dat.
Zvažte údaje o sentimentu spotřebitelů poskytované sociálními médii. V hrubé podobě jsou vrcholy a nejnižší hodnoty spotřebitelského sentimentu velmi často minimálně korelovány s offline měřítky hodnoty značky a chování: v datech je prostě příliš mnoho šumu. Tento hluk však můžeme snížit aplikací našich modelů spotřebitelského významu, diferenciace značek, dynamiky a odlišnosti na nezpracovaná data spotřebitelského sentimentu – způsob zpracování a agregace dat sociálních médií v těchto dimenzích.
Jakmile jsou data uspořádána podle našeho rámce, identifikované trendy se obvykle shodují s offline hodnotou značky a behaviorálními měřítky. Data sociálních médií v podstatě nemohou mluvit sama za sebe. Jejich použití pro tento účel vyžaduje naše zkušenosti a modely postavené na značkách. Když nám sociální média poskytují jedinečné informace vyjádřené jazykem, který spotřebitelé používají k popisu značek, musíme tento jazyk použít při vytváření našeho výzkumu, aby byl primární výzkum mnohem efektivnější.
Výhody osvobozeného výzkumu
To nás přivádí zpět k tomu, že velká data ani tak nenahrazují výzkum, jako spíše jej osvobozují. Výzkumníci budou osvobozeni od potřeby vytvářet novou studii pro každý nový případ. Stále rostoucí objem velkých dat lze použít pro různá výzkumná témata, což umožňuje následnému primárnímu výzkumu ponořit se hlouběji do tématu a vyplnit existující mezery. Výzkumníci se nebudou muset spoléhat na přehnané průzkumy. Místo toho mohou využít krátké průzkumy a zaměřit se na nejdůležitější parametry, což zlepšuje kvalitu dat.
Díky tomuto osvobození budou vědci schopni využít své zavedené principy a nápady k přidání přesnosti a smyslu k velkým datovým aktivům, což povede k novým oblastem průzkumu. Tento cyklus by měl vést k většímu porozumění v řadě strategických otázek a v konečném důsledku k posunu směrem k tomu, co by mělo být vždy naším primárním cílem – informovat a zlepšovat kvalitu rozhodování o značce a komunikaci.
Obvykle, když mluví o seriózním analytickém zpracování, zejména pokud používají termín Data Mining, mají na mysli, že existuje obrovské množství dat. Obecně tomu tak není, protože poměrně často musíte zpracovávat malé soubory dat a najít v nich vzory není o nic jednodušší než ve stovkách milionů záznamů. I když není pochyb o tom, že nutnost hledat vzory ve velkých databázích komplikuje již tak netriviální úkol analýzy.
Tato situace je typická zejména pro podniky spojené s maloobchod, telekomunikace, banky, internet. Jejich databáze shromažďují obrovské množství informací souvisejících s transakcemi: šeky, platby, hovory, protokoly atd.
Neexistují žádné univerzální metody analýzy nebo algoritmy vhodné pro všechny případy a jakékoli množství informací. Metody analýzy dat se výrazně liší výkonem, kvalitou výsledků, snadností použití a požadavky na data. Optimalizaci lze provádět na různých úrovních: vybavení, databáze, analytická platforma, příprava počátečních dat, specializované algoritmy. Analýza velkého objemu dat vyžaduje speciální přístup, protože... je technicky obtížné je zpracovat pouze pomocí „ hrubou silou“, tedy použití výkonnějšího zařízení.
Samozřejmě je možné zvýšit rychlost zpracování dat díky efektivnějšímu hardwaru, zejména proto, že moderní servery a pracovní stanice používají vícejádrové procesory, RAM značná velikost a výkon disková pole. Existuje však mnoho dalších způsobů zpracování velkého množství dat, které umožňují zvýšenou škálovatelnost a nevyžadují nekonečné obnovování zařízení.
Schopnosti DBMS
Moderní databáze obsahují různé mechanismy, jejichž použití výrazně zvýší rychlost analytického zpracování:
- Předběžný výpočet dat. Informace, které se nejčastěji používají k analýze, lze předem vypočítat (například v noci) a uložit ve formě připravené ke zpracování na databázovém serveru ve formě vícerozměrných krychlí, materializovaných pohledů a speciálních tabulek.
- Ukládání tabulek do paměti RAM. Data, která zabírají málo místa, ale jsou často přístupná během procesu analýzy, například adresáře, lze uložit do paměti RAM pomocí databázových nástrojů. Tím se mnohonásobně sníží volání pomalejšího diskového subsystému.
- Rozdělení tabulek na oddíly a tabulkové prostory. Data, indexy a pomocné tabulky můžete umístit na samostatné disky. To umožní DBMS číst a zapisovat informace na disky paralelně. Tabulky lze navíc rozdělit do oddílů, takže při přístupu k datům dochází k minimálnímu počtu diskových operací. Pokud například nejčastěji analyzujeme data za poslední měsíc, pak můžeme logicky použít jednu tabulku s historickými daty, ale fyzicky ji rozdělit na více oddílů, takže při přístupu k měsíčním datům se načte malý oddíl a neexistují žádné přístupy na všechna historická data.
Toto je pouze část schopností, které moderní DBMS poskytují. Rychlost získávání informací z databáze můžete zvýšit tuctem dalších způsobů: racionální indexování, vytváření plánů dotazů, paralelní zpracování SQL dotazů, používání clusterů, příprava analyzovaných dat pomocí uložených procedur a triggerů na straně databázového serveru atd. . Navíc mnohé z těchto mechanismů lze použít nejen pomocí „těžkých“ DBMS, ale také bezplatné databáze data.
Kombinace modelů
Možnosti zvýšení rychlosti se neomezují pouze na optimalizaci výkonu databáze, mnohé lze udělat kombinací různých modelů. Je známo, že rychlost zpracování významně souvisí se složitostí použitého matematického aparátu. Čím jednodušší jsou analytické mechanismy, tím rychleji jsou data analyzována.
Scénář zpracování dat je možné sestavit tak, že data „projdou“ sítem modelů. Zde platí jednoduchá myšlenka: neztrácejte čas zpracováním toho, co nepotřebujete analyzovat.
Nejprve se používají nejjednodušší algoritmy. Část dat, která lze zpracovat pomocí takových algoritmů a která nemá smysl zpracovávat více komplexní metody, je analyzován a vyloučen z dalšího zpracování. Zbývající data jsou přenesena do další fáze zpracování, kde se používají složitější algoritmy a tak dále v řetězci. V posledním uzlu procesního skriptu jsou použity nejsložitější algoritmy, ale objem analyzovaných dat je mnohonásobně menší než počáteční vzorek. V důsledku toho se řádově zkracuje celkový čas potřebný ke zpracování všech dat.
Pojďme dát praktický příklad pomocí tohoto přístupu. Při řešení problému prognózování poptávky se zpočátku doporučuje provést analýzu XYZ, která vám umožní určit, jak stabilní je poptávka po různém zboží. Produkty skupiny X se prodávají poměrně konzistentně, takže použití prognostických algoritmů na ně umožňuje získat vysoce kvalitní předpověď. Produkty skupiny Y se prodávají méně konzistentně, možná pro ně stojí za to stavět modely ne pro každý článek, ale pro skupinu, což vám umožní vyhladit časové řady a zajistit fungování prognostického algoritmu. Produkty skupiny Z se prodávají chaoticky, není tedy potřeba pro ně vůbec stavět prediktivní modely, jejich potřeba by se měla spočítat na základě jednoduchých vzorců, například průměrné měsíční tržby.
Podle statistik tvoří asi 70 % sortimentu výrobky skupiny Z. Dalších asi 25 % tvoří výrobky skupiny Y a jen asi 5 % tvoří výrobky skupiny X. Konstrukce a aplikace komplexních modelů je tedy relevantní pro maximálně 30 % produktů. Použití výše popsaného přístupu tedy zkrátí čas na analýzu a prognózování 5-10krát.
Paralelní zpracování
Další efektivní strategií pro zpracování velkého množství dat je rozdělit data do segmentů a sestavit modely pro každý segment zvlášť a poté výsledky zkombinovat. Nejčastěji lze ve velkých objemech dat identifikovat několik podmnožin, které se od sebe liší. Mohou to být například skupiny zákazníků, produkty, které se chovají podobně a pro které je vhodné postavit jeden model.
V tomto případě můžete namísto vytváření jednoho složitého modelu pro každého vytvořit několik jednoduchých modelů pro každý segment. Tento přístup umožňuje zvýšit rychlost analýzy a snížit požadavky na paměť zpracováním menšího množství dat v jednom průchodu. Navíc lze v tomto případě paralelizovat analytické zpracování, což má také pozitivní vliv na strávený čas. Kromě toho mohou různí analytici vytvářet modely pro každý segment.
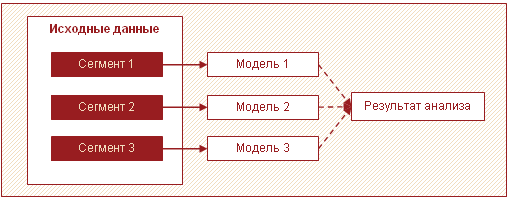
Kromě zvýšení rychlosti má tento přístup ještě jednu důležitou výhodu – několik relativně jednoduchých modelů jednotlivě se snadněji vytváří a udržuje než jeden velký. Modely můžete provozovat po etapách, čímž získáte první výsledky v co nejkratším čase.
Reprezentativní vzorky
Pokud jsou k dispozici velké objemy dat, nelze k sestavení modelu použít všechny informace, ale určitou podmnožinu – reprezentativní vzorek. Správně připravený reprezentativní vzorek obsahuje informace nezbytné pro sestavení vysoce kvalitního modelu.
Proces analytického zpracování je rozdělen do 2 částí: vytvoření modelu a aplikace vytvořeného modelu na nová data. Vytvoření komplexního modelu je proces náročný na zdroje. V závislosti na použitém algoritmu jsou data ukládána do mezipaměti, skenována tisíckrát, vypočítává se mnoho pomocných parametrů atd. Aplikace již vytvořeného modelu na nová data vyžaduje desítky a stovkykrát méně zdrojů. Velmi často jde o výpočet několika jednoduchých funkcí.
Pokud je tedy model postaven na relativně malých souborech a následně aplikován na celý soubor dat, pak se čas na získání výsledku řádově zkrátí ve srovnání s pokusem o kompletní zpracování celého existujícího souboru dat.

Pro získání reprezentativních vzorků existují speciální metody, například odběr vzorků. Jejich použití umožňuje zvýšit rychlost analytického zpracování bez obětování kvality analýzy.
souhrn
Popsané přístupy jsou pouze malou částí metod, které umožňují analyzovat obrovské množství dat. Existují další metody, například použití speciálních škálovatelných algoritmů, hierarchických modelů, učení oken atd.
Analýza obrovské základny Správa dat je netriviální úkol, který ve většině případů nelze vyřešit přímo, ale moderní databáze a analytické platformy nabízejí mnoho metod pro řešení tohoto problému. Při rozumném použití jsou systémy schopny zpracovat terabajty dat přijatelnou rychlostí.
Sloupek učitelů HSE o mýtech a případech práce s velkými daty
Do záložek
Učitelé na School of New Media na National Research University Higher School of Economics Konstantin Romanov a Alexander Pyatigorsky, který je také ředitelem digitální transformace ve společnosti Beeline, napsali pro web sloupek o hlavních mylných představách o velkých datech – příklady použití technologie a nástroje. Autoři předpokládají, že publikace pomůže manažerům firem porozumět tomuto pojmu.
Mýty a mylné představy o velkých datech
Big Data nejsou marketing
Výraz Big Data se stal velmi módním – používá se v milionech situací a se stovkami různých interpretací, často nesouvisejících s tím, co to je. V hlavách lidí se často nahrazují pojmy a velká data jsou zaměňována s marketingovým produktem. Navíc v některých společnostech jsou Big Data součástí marketingového oddělení. Výsledek analýzy velkých dat může být skutečně zdrojem pro marketingové aktivity, ale nic víc. Pojďme se podívat, jak to funguje.
Pokud jsme před dvěma měsíci identifikovali seznam těch, kteří si v našem obchodě koupili zboží za více než tři tisíce rublů, a pak těmto uživatelům zaslali nějakou nabídku, pak jde o typický marketing. Ze strukturálních dat odvozujeme jasný vzor a používáme ho ke zvýšení prodeje.
Pokud však zkombinujeme data CRM s informacemi ze streamingu například z Instagramu a analyzujeme je, najdeme vzorec: člověk, který ve středu večer omezil aktivitu a na jehož poslední fotografii jsou koťata, by měl učinit určitou nabídku. To již budou velká data. Našli jsme spoušť, předali ji obchodníkům a ti ji použili pro své účely.
Z toho plyne, že technologie většinou pracuje s nestrukturovanými daty, a i když jsou data strukturovaná, systém v nich stále hledá skryté vzorce, což marketing nedělá.
Big Data nejsou IT
Druhý extrém tohoto příběhu: Big Data jsou často zaměňována s IT. To je způsobeno tím, že v ruské společnosti IT specialisté jsou zpravidla tahouny všech technologií, včetně velkých dat. Pokud se tedy vše odehrává v tomto oddělení, společnost jako celek nabývá dojmu, že jde o nějakou IT činnost.
Ve skutečnosti je zde zásadní rozdíl: Big Data je činnost zaměřená na získání konkrétního produktu, která s IT vůbec nesouvisí, ačkoli technologie bez něj nemůže existovat.
Velká data nejsou vždy sběrem a analýzou informací
Existuje další mylná představa o velkých datech. Každý chápe, že tato technologie zahrnuje velké množství dat, ale není vždy jasné, o jaký druh dat se jedná. Sbírat a využívat informace může kdokoli, nyní je to možné nejen ve filmech o, ale i v každé, i velmi malé společnosti. Jedinou otázkou je, co přesně sbírat a jak to využít ve svůj prospěch.
Ale to by se mělo chápat Velká technologie Data nebudou shromažďováním a analýzou absolutně žádných informací. Pokud například sbíráte data o konkrétní osobě na sociálních sítích, nepůjde o Big Data.
Co jsou to vlastně velká data?
Velká data se skládají ze tří prvků:
- data;
- analytika;
- technologií.
Big Data nejsou jen jednou z těchto složek, ale kombinací všech tří prvků. Lidé často nahrazují pojmy: někteří věří, že velká data jsou jen data, jiní věří, že jde o technologii. Ale ve skutečnosti bez ohledu na to, kolik dat nasbíráte, s nimi nic neuděláte potřebné technologie a analytici. Pokud existuje dobrá analytika, ale žádná data, je to ještě horší.
Pokud mluvíme o datech, nejsou to jen texty, ale také všechny fotografie zveřejněné na Instagramu a obecně vše, co lze analyzovat a použít pro různé účely a úkoly. Jinými slovy, Data označují obrovské objemy interních a externích dat různých struktur.
Analytika je také potřeba, protože úkolem Big Data je vytvořit nějaké vzory. To znamená, že analytika je identifikace skrytých závislostí a hledání nových otázek a odpovědí na základě analýzy celého objemu heterogenních dat. Navíc Big Data kladou otázky, které z těchto dat nelze přímo odvodit.
Pokud jde o obrázky, to, že zveřejníte svou fotku v modrém tričku, nic neznamená. Pokud ale používáte fotografii pro Big Data modelování, může se ukázat, že právě teď byste měli nabídnout půjčku, protože ve vaší sociální skupině takové chování naznačuje určitý jev v akci. Proto „holá“ data bez analýzy, bez identifikace skrytých a nezřejmých závislostí nejsou Big Data.
Máme tedy velká data. Jejich pole je obrovské. Máme také analytika. Jak ale můžeme zajistit, že z těchto nezpracovaných dat dojdeme ke konkrétnímu řešení? K tomu potřebujeme technologie, které nám je umožní nejen ukládat (a to dříve nebylo možné), ale také je analyzovat.
Jednoduše řečeno, pokud máte hodně dat, budete potřebovat technologie, například Hadoop, které umožňují uložit všechny informace v původní podobě pro pozdější analýzu. Tento druh technologie vznikl u internetových gigantů, protože jako první čelili problému ukládání velkého množství dat a jejich analýze pro následné zpeněžení.
Kromě nástrojů pro optimalizované a levné ukládání dat potřebujete analytické nástroje a také doplňky k používané platformě. Například kolem Hadoopu se již vytvořil celý ekosystém souvisejících projektů a technologií. Tady jsou některé z nich:
- Pig je deklarativní jazyk pro analýzu dat.
- Hive - analýza dat pomocí jazyka podobného SQL.
- Oozie - pracovní postup Hadoop.
- Hbase je databáze (nerelační), podobná Google Big Table.
- Mahout – strojové učení.
- Sqoop - přenos dat z RSDB do Hadoop a naopak.
- Flume - přenos protokolů do HDFS.
- Zookeeper, MRUnit, Avro, Giraph, Ambari, Cassandra, HCatalog, Fuse-DFS a tak dále.
Všechny tyto nástroje jsou k dispozici všem zdarma, ale existuje i řada placených doplňků.
Kromě toho jsou zapotřebí specialisté: vývojář a analytik (tzv. Data Scientist). Je také potřeba manažera, který dokáže pochopit, jak tuto analytiku použít k řešení konkrétního problému, protože sama o sobě je zcela bezvýznamná, pokud není integrována do podnikových procesů.
Všichni tři zaměstnanci musí pracovat jako tým. Manažer, který dá specialistovi na Data Science za úkol najít určitý vzorec, musí pochopit, že ne vždy najde přesně to, co potřebuje. V tomto případě by měl manažer pozorně naslouchat tomu, co Data Scientist zjistil, protože jeho zjištění se často ukáží jako zajímavější a užitečnější pro podnik. Vaším úkolem je aplikovat to na podnikání a vytvořit z toho produkt.
Navzdory skutečnosti, že nyní existuje mnoho různých druhů strojů a technologií, konečné rozhodnutí vždy zůstává na člověku. K tomu je potřeba informace nějak vizualizovat. Existuje na to poměrně hodně nástrojů.
Nejvýmluvnějším příkladem jsou geoanalytické zprávy. Společnost Beeline hodně spolupracuje s vládami různých měst a regionů. Tyto organizace si velmi často objednávají zprávy jako „Dopravní zácpa v určité lokalitě“.
Je jasné, že taková zpráva by se měla dostat k vládním úřadům v jednoduché a srozumitelné formě. Pokud jim poskytneme obrovskou a zcela nesrozumitelnou tabulku (tedy informace v podobě, v jaké je dostáváme), je nepravděpodobné, že by si takovou zprávu koupili - bude to zcela zbytečné, nezískají z ní vědomí, že chtěli obdržet.
Proto bez ohledu na to, jak dobří jsou datoví vědci a bez ohledu na to, jaké vzory najdou, nebudete moci s těmito daty pracovat bez dobrých vizualizačních nástrojů.
Zdroje dat
Pole získaných dat je velmi rozsáhlé, lze je tedy rozdělit do několika skupin.
Interní firemní údaje
Přestože 80 % shromážděných dat patří do této skupiny, tento zdroj není vždy využíván. Často se jedná o data, která zdánlivě nikdo nepotřebuje, například protokoly. Když se na ně ale podíváte z jiného úhlu, můžete v nich občas najít nečekané vzory.
Sharewarové zdroje
To zahrnuje data sociální sítě, internet a vše, kde se k němu dostanete zdarma. Proč je shareware zdarma? Na jednu stranu jsou tato data dostupná všem, ale pokud jste velká firma, tak získat je ve velikosti předplatitelské základny desítek tisíc, stovek či milionů zákazníků už není snadný úkol. Proto existují placené služby poskytnout tyto údaje.
Placené zdroje
Patří sem společnosti, které prodávají data za peníze. Mohou to být telekomunikace, DMP, internetové společnosti, úvěrové kanceláře a agregátory. V Rusku telekomunikace data neprodávají. Za prvé je to ekonomicky nerentabilní a za druhé je to zákonem zakázáno. Proto prodávají výsledky svého zpracování, například geoanalytické zprávy.
Otevřená data
Stát vychází podnikům vstříc a dává jim možnost využívat shromážděná data. To je ve větší míře rozvinuto na Západě, ale Rusko v tomto ohledu také drží krok s dobou. Existuje například portál otevřených dat moskevské vlády, kde jsou zveřejňovány informace o různých zařízeních městské infrastruktury.
Pro obyvatele a hosty Moskvy jsou data prezentována v tabulkové a kartografické podobě a pro vývojáře - ve speciálních strojově čitelných formátech. Zatímco projekt pracuje v omezeném režimu, vyvíjí se, což znamená, že je také zdrojem dat, která můžete využít pro své obchodní úkoly.
Výzkum
Jak již bylo řečeno, úkolem Big Data je najít vzorec. Často se výzkum prováděný po celém světě může stát opěrným bodem pro nalezení konkrétního vzoru - můžete získat konkrétní výsledek a pokusit se použít podobnou logiku pro své vlastní účely.
Velká data jsou oblastí, ve které neplatí všechny matematické zákony. Například „1“ + „1“ není „2“, ale mnohem více, protože smícháním zdrojů dat lze efekt výrazně zvýšit.
Příklady produktů
Mnoho lidí zná službu výběru hudby Spotify. Je to skvělé, protože se neptá uživatelů, jakou mají dnes náladu, ale spíše ji vypočítává na základě zdrojů, které má k dispozici. Vždy ví, co teď potřebujete – jazz nebo hard rock. To je klíčový rozdíl, který mu poskytuje fanoušky a odlišuje jej od ostatních služeb.

Takové produkty se obvykle nazývají sense produkty – ty, které cítí své zákazníky.
Technologie Big Data se využívá i v automobilovém průmyslu. Například Tesla to dělá - v jejich poslední model existuje autopilot. Společnost se snaží vytvořit vůz, který sám doveze cestujícího tam, kam potřebuje. Bez Big Data je to nemožné, protože pokud budeme používat pouze data, která dostáváme přímo, jako to dělá člověk, pak se auto nebude moci zlepšit.

Když sami řídíme auto, používáme naše neurony k rozhodování na základě mnoha faktorů, kterých si ani nevšimneme. Možná si neuvědomujeme, proč jsme se rozhodli hned nezrychlit na zelenou, ale pak se ukáže, že rozhodnutí bylo správné – kolem vás projelo závratnou rychlostí auto a vy jste se vyhnuli nehodě.
Můžete také uvést příklad využití Big Data ve sportu. V roce 2002 se generální manažer baseballového týmu Oakland Athletics Billy Beane rozhodl prolomit paradigma, jak nabírat sportovce – vybíral a trénoval hráče „do počtu“.
Manažeři se obvykle dívají na úspěch hráčů, ale v tomto případě bylo všechno jinak - aby dosáhl výsledků, manažer studoval, jaké kombinace sportovců potřeboval, přičemž věnoval pozornost individuálním charakteristikám. Navíc si vybral sportovce, kteří sami o sobě neměli velký potenciál, ale tým jako celek se ukázal být natolik úspěšný, že vyhrál dvacet zápasů v řadě.

Režisér Bennett Miller následně natočil film věnovaný tomuto příběhu – „Muž, který změnil všechno“ s Bradem Pittem v hlavní roli.
Technologie Big Data je užitečná i ve finančním sektoru. Ani jeden člověk na světě nedokáže samostatně a přesně určit, zda se vyplatí někomu půjčit. Aby bylo možné rozhodnout, provádí se bodování, to znamená, že je sestaven pravděpodobnostní model, ze kterého lze pochopit, zda tato osoba vrátí peníze nebo ne. Bodování se dále uplatňuje ve všech fázích: můžete například spočítat, že v určitém okamžiku člověk přestane platit.
Velká data umožňují nejen vydělávat peníze, ale také je šetřit. Zejména tato technologie pomohla německému ministerstvu práce snížit náklady na dávky v nezaměstnanosti o 10 miliard eur, protože po analýze informací vyšlo najevo, že 20 % dávek bylo vyplaceno nezaslouženě.
Technologie se využívají i v medicíně (to je typické zejména pro Izrael). S pomocí Big Data můžete provést mnohem přesnější analýzu, než dokáže udělat lékař s třicetiletou praxí.
Každý lékař se při stanovení diagnózy spoléhá pouze na sebe vlastní zkušenost. Když to stroj dělá, vychází to ze zkušeností tisíců takových lékařů a všech existujících kazuistik. Bere v úvahu, z jakého materiálu je dům pacienta vyroben, v jaké oblasti oběť žije, jaký je tam kouř a tak dále. To znamená, že bere v úvahu spoustu faktorů, které lékaři neberou v úvahu.
Příkladem využití Big Data ve zdravotnictví je projekt Project Artemis, který realizovala Torontská dětská nemocnice. Tento Informační systém, která shromažďuje a analyzuje data o miminkách v reálném čase. Stroj umožňuje každou sekundu analyzovat 1260 zdravotních ukazatelů každého dítěte. Tento projekt je zaměřen na predikci nestabilního stavu dítěte a prevenci nemocí u dětí.
Big data se začínají používat i v Rusku: například Yandex má divizi big data. Společnost společně s AstraZeneca a Ruskou společností klinické onkologie RUSSCO spustila platformu RAY, určenou genetikům a molekulárním biologům. Projekt nám umožňuje zlepšit metody diagnostiky rakoviny a identifikace predispozice k rakovině. Platforma bude spuštěna v prosinci 2016.
Pojem velká data obvykle označuje jakékoli množství strukturovaných, polostrukturovaných a nestrukturovaných dat. Druhý a třetí však mohou a měly by být objednány pro následnou analýzu informací. Velká data se nerovnají žádnému skutečnému objemu, ale když mluvíme o velkých datech, ve většině případů máme na mysli terabajty, petabajty a dokonce extrabajty informací. Každý podnik může toto množství dat nashromáždit v průběhu času, nebo v případech, kdy společnost potřebuje přijímat velké množství informací, v reálném čase.
Analýza velkých dat
Když mluvíme o analýze velkých dat, máme na mysli především sběr a ukládání informací z různých zdrojů. Například údaje o zákaznících, kteří nakupovali, jejich charakteristika, informace o zahájených reklamní společnosti a hodnocení jeho účinnosti, dat kontaktní centrum. Ano, všechny tyto informace lze porovnávat a analyzovat. Je to možné a nutné. K tomu je ale potřeba nastavit systém, který vám umožní shromažďovat a transformovat informace, aniž byste je zkreslili, ukládat a nakonec vizualizovat. Souhlasíte s tím, že u velkých dat jsou tabulky vytištěné na několika tisících stranách jen malou pomocí pro obchodní rozhodnutí.
1. Příchod velkých dat
Většina služeb, které shromažďují informace o akcích uživatelů, má možnost exportu. Aby se zajistilo, že se do společnosti dostanou ve strukturované podobě, používají se různé systémy, například Alteryx. Tento software vám umožňuje přijímat automatický režim informace, zpracovat je, ale hlavně - převést na správný typ a formát bez zkreslení.
2. Ukládání a zpracování velkých dat
Téměř vždy při shromažďování velkého množství informací nastává problém s jejich ukládáním. Ze všech platforem, které jsme studovali, naše společnost preferuje Verticu. Na rozdíl od jiných produktů je Vertica schopna rychle „vrátit“ informace v ní uložené. Mezi nevýhody patří dlouhé nahrávání, ale při analýze velkých dat vystupuje do popředí rychlost návratu. Například, pokud mluvíme o kompilaci pomocí petabajtu informací, rychlost nahrávání je jednou z nejdůležitějších charakteristik.
3. Vizualizace velkých dat
A konečně třetí fází analýzy velkých objemů dat je . K tomu potřebujete platformu, která dokáže vizuálně odrážet všechny přijaté informace ve vhodné formě. Podle našeho názoru se s tímto úkolem vyrovná pouze jeden softwarový produkt - Tableau. Určitě jeden z nejlepších na dnesřešení, které dokáže vizuálně zobrazit jakékoli informace, přemění práci společnosti na trojrozměrný model, shromažďuje akce všech oddělení do jediného vzájemně závislého řetězce (můžete si přečíst více o možnostech Tableau).
Místo toho si všimněme, že téměř každá společnost nyní může vytvářet svá vlastní velká data. Analýza velkých dat již není složitým a nákladným procesem. Vedení společnosti je nyní povinno správně formulovat otázky shromážděné informace, přičemž nezůstávají prakticky žádné neviditelné šedé oblasti.
Stáhnout Tableau