Introduction to XML-RPC. Programming competitions What can be seen in the diagram
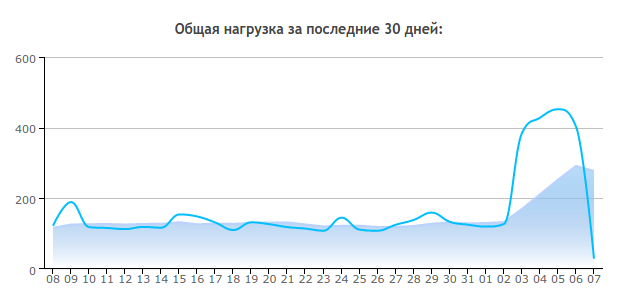
A few days ago, I noticed that the load on my sites on hosting has increased significantly. If usually it was around 100-120 “parrots” (CP), then over the past few days it has increased to 400-500 CP. There is nothing good about this, because the hoster can switch to a more expensive tariff, or even completely close access to the sites, so I started to look into it.
But I chose a method that will preserve the XML-RPC functionality: installing the Disable XML-RPC Pingback plugin. It removes only the "dangerous" methods pingback.ping and pingback.extensions.getPingbacks, leaving the XML-RPC functionality. Once installed, the plugin only needs to be activated - no further configuration is required.
Along the way, I entered all the attackers’ IPs into the .htaccess file of my sites to block their access. I just added to the end of the file:
Order Allow,Deny Allow from all Deny from 5.196.5.116 37.59.120.214 92.222.35.159
That's all, now we have reliably protected the blog from further attacks using xmlrpc.php. Our sites stopped loading the hosting with requests, as well as DDoS attacks on third-party sites.
Starting at noon on Saturday, my server, where about 25 Wordpress sites are hosted, started experiencing severe slowdowns. Since I managed to survive the previous attacks ( , ) without being noticed, I did not immediately understand what was happening.
When I figured it out, it turned out that passwords were being brute-forced + many requests to XMLRPC.
As a result, we managed to cut it all off, although not immediately. Here are three simple tricks on how to avoid this.
These techniques are most likely known to everyone, but I stepped on a couple of mistakes that I didn’t find in the descriptions - maybe this will save someone time.
1. Stop the search, install the Limit Login Attempts plugin - install it, since other protections greatly slow down the server, for example, when using the Login Security Solution plugin, the server died after half an hour, the plugin heavily loads the database.
In the settings, be sure to turn on the “For proxy” checkbox - otherwise it will determine the IP of your server for everyone and automatically block everyone.
UPDATE, thank you, details are below in the comments - enable the “For proxy” checkbox only if the definition does not work when “Direct connection” is enabled
2. Disable XML-RPC - the Disable XML-RPC plugin (it’s easy to activate and that’s it).
3. Close wp-login.php - if you access the site via IP, the plugin does not work and the pickers continue to crash the site. To avoid this, add to .htaccess:
We copy the wp-login file, rename it to any strange name, for example poletnormalny.php, and inside the file, use autocorrect to change all the wp-login.php inscriptions to poletnormalny.php.
That's it, now you can access the admin panel only using your file.
After these 3 simple steps, the sites began to fly again and peace came.
Well, suddenly it’s interesting
One of the options is to see if you are being attacked. This can be seen in the nginx logs (for example, here is the path for Debian /var/log/nginx access.log file).XML-RPC technology is used in the WordPress system for various nice features such as pingbacks, trackbacks, remote site management without logging into the admin panel, etc. Unfortunately, attackers can use it to perform DDoS attacks on websites. That is, you create beautiful, interesting WP projects for yourself or to order, and at the same time, without suspecting anything, you can be part of a DDoS botnet. By connecting tens and hundreds of thousands of sites together, bad people create a powerful attack on their victim. Although at the same time your site also suffers, because... the load goes to the hosting where it is located.
Evidence of such bad activity can be in the server logs (access.log in nginx), containing the following lines:
103.238.80.27 - - "POST /wp-login.php HTTP/1.0" 200 5791 "-" "-"
But let's return to the XML-RPC vulnerability. Visually, it manifests itself in the slow opening of sites on your server or the inability to load them at all (502 Bad Gateway error). The technical support of my FASTVPS host confirmed my guesses and advised:
- Update WordPress to the latest version along with plugins. In general, if you follow, you might have read about the need to install the latest 4.2.3. due to security criticisms (just like previous versions). In short, it's good to update.
- Install the Disable XML-RPC Pingback plugin.
Disabling XML-RPC in WordPress
Previously, it seems to me that the option to enable/disable XML-RPC was somewhere in the system settings, but now I can’t find it there. Therefore, the easiest way to get rid of it is to use the appropriate plugin.

Find and download Disable XML-RPC Pingback or install it directly from the system admin panel. You do not need to configure anything additional, the module starts working immediately. It removes the pingback.ping and pingback.extensions.getPingbacks methods from the XML-RPC interface. Additionally, it removes X-Pingback from HTTP headers.
In one of the blogs I found a couple more options for removing the XML-RPC disabling.
1. Disable XML-RPC in the template.
To do this, add the following line to the theme's functions.php file:
I personally did not use the last two methods, because... I connected the Disable XML-RPC Pingback plugin - I think it will be enough. Just for those who don’t like unnecessary installations, I suggested alternative options.
Organization of thread processing with efficient use of memory
Elliott Rusty Harold
Published 10/11/2007
PHP 5 introduced XMLReader, a new class for reading Extensible Markup Language (XML). Unlike plain XML or the Document Object Model (DOM), XMLReader works in streaming mode. That is, it reads the document from beginning to end. You can start working with the document's content at the beginning of the document, before you see the end. This makes it very fast, efficient and very memory efficient. The larger the size of the documents that need to be processed, the more important this is.
libxml
The XMLReader API described is based on the Gnome Project's libxml library for C and C++. In reality, XMLReader is just a thin PHP layer on top of the libxml XmlTextReader API. XmlTextReader is also modeled after (though does not share the same code as) the .NET classes XmlTextReader and XmlReader.
Unlike the simple XML API (SAX), XMLReader is more of a pull parser than a push parser. This means that the program is under control. Instead of the parser telling you what it sees when it sees it; you tell the parser when to move on to the next portion of the document. You are asking for content instead of reacting to it. In other words, you can think of it this way: XMLReader is an implementation of the Iterator construct, not the Observer construct.
Sample task
Let's start with a simple example. Imagine that you are writing a PHP script that receives XML-RPC requests and generates responses. More specifically, imagine the queries looking like Listing 1. The root document element is methodCall , which contains the methodName and params elements. The name of the method is sqrt. The params element contains one param element, which includes a double - the number whose square root you want to extract. Namespaces are not used.
Listing 1. XML-RPC request
This is what the PHP script should do:
- Check the name of the method and generate a fault response if it is not sqrt (the only method that can be handled by this script).
- Find the argument and, if it is missing or of the wrong type, generate a failure signal.
- Otherwise, calculate the square root.
- Return the result in the form shown in Listing 2.
Listing 2. XML-RPC response
Let's take it step by step.
Initializing the parser and loading the document
The first step is to create a new parser object. It's easy to do:
$reader = new XMLReader();Adding information to the original data being sent
If you find that $HTTP_RAW_POST_DATA is empty, add the following line to your php.ini file:
always_populate_raw_post_data = On
$request = $HTTP_RAW_POST_DATA; $reader->XML($request);You can parse any string, no matter where you get it from. For example, this could be a string literal constant in a program or the contents of a file. You can also load data from an external URL using the open() function. For example, the following instruction prepares one of the Atom channels for parsing:
$reader->XML("http://www.cafeaulait.org/today.atom");Wherever you took your source data from, the reader is now installed and ready to perform analysis.
Reading a document
The read() function moves the parser to the next token. The simplest approach is to iterate a while loop throughout the document:
while ($reader->read()) ( // processing code... )When finished, close the parser to free up the resources it is taking up and reconfigure it for the following document:
$reader->close();Inside the loop, the parser is placed at a specific node: at the beginning of an element, at the end of an element, in a text node, in a comment, and so on. The following properties let you know what the parser is currently looking at:
- localName is the local, non-predefined host name.
- name - a possible predefined node name. For nodes that do not have names, such as comments, these are #comment , #text , #document , etc., as in the DOM (Document Object Model).
- namespaceURI is the Uniform Resource Identifier (URI) for the host namespace.
- nodeType is an integer representing the type of the node - for example, 2 for an attribute node and 7 for a processing statement.
- prefix is the node's namespace prefix.
- value is the text content of the node.
- hasValue - true if the node has a text value and false otherwise.
Of course, not all node types have all of these properties. For example, text nodes, CDATA sections, comments, processing statements, attributes, the space character, document types, and XML descriptions have meanings. Other types of nodes (especially elements and documents) do not. Typically a program uses the nodeType property to determine what is being viewed and respond accordingly. Listing 3 shows a simple while loop that uses these functions to output what it's looking at. Listing 4 shows the output of this program when given Listing 1 as input.
Listing 3. What the parser sees
while ($reader->read()) ( echo $reader->name; if ($reader->hasValue) ( echo ": " . $reader->value; ) echo "\n"; )Listing 4. Output from Listing 3
methodCall #text: methodName #text: sqrt methodName #text: params #text: param #text: value double #text: 10 double value #text: param #text: params #text: methodCallMost programs are not so universal. They accept input data in a specific form and process it in a specific way. In the XML-RPC example, only one parameter needs to be read from the input: the double element, of which there should only be one. To do this, find the beginning of the element named double:
if ($reader->name == "double" && $reader->nodeelementType == XMLReader::element) ( // ... )This element also has a single text child node, which can be read by moving the parser to the next node:
if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) ( $reader->read(); respond($reader->value); )Here, the respond() function creates an XML-RPC response and sends it to the client. However, before I show this, there is one more thing that needs to be said. There is no guarantee that the double element in the request document contains only one text node. It can contain multiple nodes, as well as comments and statements. For example, it might look like this:
Nested Elements
There is one possible defect in this circuit. Nested double elements, for example,
A sustainable solution to the problem would be to get all the children of the text node double , chain them together, and only then convert the result to double . Any comments or other possible non-text nodes should be avoided. It's a little more complicated, but as Listing 5 shows, not too much.
Listing 5. Summarize all text content of an element
while ($reader->read()) ( if ($reader->nodeType == XMLReader::TEXT || $reader->nodeType == XMLReader::CDATA || $reader->nodeType == XMLReader::WHITESPACE || $reader->nodeType == XMLReader::SIGNIFICANT_WHITESPACE) ( $input .= $reader->value; ) else if ($reader->nodeType == XMLReader::END_ELEMENT && $reader->name == "double ") ( break; ) )For now, the rest of the document's content can be ignored. (I'll go on to describe error handling later.)
Creating a response
As the name suggests, XMLReader is read-only. The corresponding XMLWriter class is currently in development, but not yet ready. Fortunately, writing XML is much easier than reading it. First, you must set the media type of the response using the header() function. For XML-RPC this is application/xml . For example:
header("Content-type: application/xml");Listing 6. XML mapping
function respond($input) ( echo "You can even insert the letter parts of the answer directly into the PHP page, just as you would do it in HTML. This technology is shown in Listing 7.
Listing 7. Literal XML
function respond($input) ( ?>Error processing
Until now, it was assumed that the input document was formatted correctly. However, no one can guarantee this. Like any XML parser, XMLReader must stop processing as soon as it encounters a formatting error. If this happens, the read() function returns false.
In theory, the parser can process data until the first error it encounters. In my experiments with small documents, however, it encounters an error almost immediately. The underlying parser pre-parses a large portion of the document, caches it, and then outputs it piece by piece. Thus, it usually identifies errors at a preliminary stage. For security reasons, it is better not to take responsibility for the fact that you can perform content analysis before the first design error. Moreover, don't assume that you won't see any content before the parser fails. If you only need to accept complete, correctly formatted documents, then make sure that the script does not do anything irreversible until the very end of the document.
If the parser encounters a formatting error, the read() function displays an error message similar to this one (if detailed error reporting is configured, as it should be on a development server):
Warning: XMLReader::read() [function.read]:< value>
You may not want to copy the report into the HTML page presented to the user. It's better to capture the error message in the $php_errormsg environment variable. To do this, you need to enable the track_errors configuration option in the php.ini file:
track_errors = OnBy default, the track_errors option is disabled, which is explicitly stated in php.ini, so be sure to change this line. If you add the line shown above to the beginning of php.ini, then the line track_errors = Off below will replace it.
This program should only send responses to complete, correctly formatted input. (Also reliable, but more on that later.) Thus, you need to wait for the document analysis to complete (exiting the while loop). Now check if the value of $php_errormsg has changed. If not, then the document is formatted correctly and an XML-RPC response message will be sent. If the variable is set, it means that the document is not formatted correctly and an XML-RPC failure signal will be sent. A failure signal is also sent if the square root of a negative number is requested. See Listing 8.
Listing 8. Checking for correct formatting
// sending a request $request = $HTTP_RAW_POST_DATA;< 0) fault(20, "Cannot take square root of negative number"); else respond($input);error_reporting(E_ERROR | E_WARNING | E_PARSE);
if (isset($php_errormsg)) unset(($php_errormsg); // creating a reader program (reader) $reader = new XMLReader(); // $reader->setRelaxNGschema("request.rng"); $reader-> XML($request); $input = ""; while ($reader->read()) ( if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) ( while ($reader->read()) ( if ($reader->nodeType == XMLReader::TEXT || $reader->nodeType == XMLReader::CDATA || $reader->nodeType == XMLReader::WHITESPACE | | $reader->nodeType == XMLReader::SIGNIFICANT_WHITESPACE) ( $input .= $reader->value; ) else if ($reader->nodeType == XMLReader::END_ELEMENT && $reader->name == "double" ) ( break; ) ) break; ) ) // checking the correct format of the input information if (isset($php_errormsg)) fault(21, $php_errormsg);
Here's a simplified version of the general XML stream processing pattern. The parser populates a data structure according to which actions are performed when the document ends. Usually the data structure is simpler than the document itself. Here the data structure is especially simple: a single row.
Validation
libxml version
Early versions of libxml, the library on which XMLReader depends, had serious RELAX NG flaws. Make sure you are using at least version 2.06.26. Many systems, including Mac OS X Tiger, contain an earlier release with flaws.
Until now, I haven't put much emphasis on checking whether the data is actually where I think it is. The easiest way to perform this check is to compare the document with the diagram. XMLReader supports the RELAX NG schema description language; Listing 9 shows a simple RELAX NG schema for this particular form of XML-RPC request.
Listing 9. XML-RPC requestThe schema can be added directly to a PHP script as a string literal using setRelaxNGSchemaSource() or read from an external file or URL using setRelaxNGSchema() . For example, assuming the contents of Listing 9 are written in the sqrt.rng file, the schema would load like this: reader->setRelaxNGSchema("sqrt.rng") than you begin to analyze the document. The parser compares the document with the schema while reading. To check whether a document is valid, call the isValid() function, which returns true if the document is valid (at this point) and false otherwise. Listing 10 shows the complete program, containing all error handling. The program must accept any valid input and return correct values and reject all incorrect requests. I've also added a fault() method that sends an XML-RPC fault if something goes wrong.
Listing 10. Complete XML-RPC square root backend
Attributes
The attributes are not visible during normal analysis. To read attributes, you need to stop at the beginning of the element and query for a specific attribute either by name or number.
Pass the name of the attribute whose value you want to find in the current element to the getAttribute() function. For example, the following construct requests the id attribute of the current element:
$id = $reader->getAttribute("id");If the attribute is in a namespace, for example xlink:href , then call getAttributeNS() and pass the local name and namespace URI as the first and second arguments respectively (the prefix does not matter). For example, this statement queries the value of the xlink:href attribute in the http://www.w3.org/1999/xlink/ namespace:
$href = $reader->getAttributeNS("href", "http://www.w3.org/1999/xlink/");If the attribute does not exist, then both methods will return an empty string. (This is incorrect because they should return null. This implementation makes it difficult to distinguish between attributes whose value is the empty string and those that have no value at all.)
Attribute order
In XML documents, the order of the attributes does not matter and is not preserved by the parser. It uses numbers to index attributes just for the sake of convenience. There is no guarantee that the first attribute in the opening tag will be attribute 1, the second will be attribute 2, etc. Don't write code that depends on the order of attributes.
If you need to know all the attributes of an element, but their names are not known in advance, then call moveToNextAttribute() when the read part is set on the element. If the parser is on an attribute node, then you can read its name, namespace, and value using the same properties that were used for elements. For example, the following code snippet prints all attributes of the current element:
if ($reader->hasAttributes and $reader->nodeType == XMLReader::ELEMENT) ( while ($reader->moveToNextAttribute()) ( echo $reader->name . "="" . $reader->value . ""\n"; ) echo "\n"; )Very unusual for an XML API, XMLReader allows you to read attributes either from the beginning, either from the end element. To avoid double counting, it is important to ensure that the node type is XMLReader::ELEMENT and not XMLReader::END_ELEMENT , which can also have attributes.
Conclusion
XMLReader is a useful addition to the PHP programmer's toolkit. Unlike SimpleXML, it is a full XML parser that processes all documents, not just some of them. Unlike the DOM, it can handle documents larger than the available memory. Unlike SAX, it establishes control over the program. If PHP programs need to accept XML input, then you should seriously consider using XMLReader.
Introduction to XML-RPC
There are many different resources on the Internet that provide users with certain information. This does not mean ordinary static pages, but, for example, data retrieved from a database or archives. This could be an archive of financial data (exchange rates, securities quotes data), weather data, or more voluminous information - news, articles, messages from forums. Such information can be presented to the page visitor, for example, through a form, as a response to a request, or it can be generated dynamically each time. But the difficulty is that often such information is needed not so much by the end user - a person, but by other systems and programs that will use this data for their calculations or other needs.
Real example: a page of a banking website that displays currency quotes. If you access the page as a regular user, through a browser, you see all the page design, banners, menus and other information that “frames” the true purpose of the search - currency quotes. If you need to enter these quotes into your online store, then there is nothing else left to do but manually select the necessary data and transfer it to your website via the clipboard. And you will have to do this every day. Is there really no way out?
If you solve the problem head-on, then a solution immediately arises: a program (script on a website) that needs data receives a page from the server as a “regular user”, parses (parses) the resulting html code and extracts the necessary information from it. This can be done either with a regular regular expression, or using any html parser. The difficulty of the approach lies in its ineffectiveness. Firstly, to receive a small portion of data (data on currencies is literally a dozen or two characters), you need to receive the entire page, which is at least several tens of kilobytes. Secondly, with any change in the page code, for example, the design has changed or something else, our parsing algorithm will have to be redone. And this will take a fair amount of resources.
Therefore, the developers came to a decision - it is necessary to develop some kind of universal mechanism that would allow transparent (at the protocol and transmission medium level) and easy exchange of data between programs that can be located anywhere, be written in any language and run under any operating system. systems and on any hardware platform. Such a mechanism is now called the loud terms “Web services”, “SOAP”, “service-oriented architecture”. For data exchange, open and time-tested standards are used - the HTTP protocol is used for transmitting messages (although other protocols can be used - SMTP, for example). The data itself (in our example, exchange rates) is transmitted packaged in a cross-platform format - in the form of XML documents. For this purpose, a special standard was invented - SOAP.
Yes, now web services, SOAP and XML are on everyone’s lips, they are beginning to be actively implemented, and large corporations like IBM and Microsoft are releasing new products designed to help the total implementation of web services.
But! For our example with exchange rates that must be transmitted from the bank’s website to the online store engine, such a solution will be very difficult. After all, the description of the SOAP standard alone takes up an obscene one and a half thousand pages, and that’s not all. For practical use, you will also have to learn how to work with third-party libraries and extensions (only starting from PHP 5.0 it includes a library for working with SOAP), and write hundreds and thousands of lines of your own code. And all this to get a few letters and numbers is obviously very cumbersome and irrational.
Therefore, there is another, one might say, alternative standard for information exchange - XML-RPC. It was developed with the participation of Microsoft by UserLand Software Inc and is designed for unified data transfer between applications over the Internet. It can replace SOAP when building simple services where all the “enterprise” capabilities of real web services are not needed.
What does the abbreviation XML-RPC mean? RPC stands for Remote Procedure Call. This means that an application (whether a script on the server or a regular application on the client computer) can transparently use a method that is physically implemented and executed on another computer. XML is used here to provide a universal format for describing the transmitted data. As a transport, the HTTP protocol is used to transmit messages, which allows you to seamlessly exchange data through any network devices - routers, firewalls, proxy servers.
And so, to use you need to have: an XML-RPC server that provides one or more methods, an XML-RPC client that can generate a correct request and process the server response, and also know the server parameters necessary for successful operation - address, method name and passed parameters.
All work with XML-RPC occurs in the “request-response” mode, this is one of the differences between the technology and the SOAP standard, where there are both the concepts of transactions and the ability to make delayed calls (when the server saves the request and responds to it at a certain time in future). These additional features are more useful for powerful corporate services; they significantly complicate the development and support of servers, and place additional requirements on developers of client solutions.
The procedure for working with XML-RPC begins with forming a request. A typical request looks like this:
POST /RPC2 HTTP/1.0
User-Agent: eshop-test/1.1.1 (FreeBSD)
Host: server.localnet.com
Content-Type: text/xml
Content-length: 172
The first lines form the standard HTTP POST request header. Required parameters include host, data type (MIME type), which must be text/xml, and message length. The standard also specifies that the User-Agent field must be filled in, but can contain an arbitrary value.
Next comes the usual header of the XML document. The root element of the request is
Line
Next, the transmitted parameters are set. This section is used for this.
The description of all parameters is followed by closing tags. The request and response in XML-RPC are regular XML documents, so all tags must be closed. But there are no single tags in XML-RPC, although they are present in the XML standard.
Now let's look at the server's response. The HTTP response header is normal; if the request is successfully processed, the server returns an HTTP/1.1 200 OK response. Just as in the request, you must correctly specify the MIME type, message length and response generation date.
The response body itself is as follows:
Now instead of the root tag
If an error occurred while processing your request, instead of The response will contain the element
Now let's take a brief look at data types in XML-RPC. There are 9 data types in total - seven simple types and 2 complex ones. Each type is described by its own tag or set of tags (for complex types).
Simple types:
Whole numbers- tag
Boolean type- tag
ASCII string- described by tag
Floating point numbers- tag
date and time- described by tag
The last simple type is base64 encoded string, which is described by the tag
Complex types are represented by structures and arrays. The structure is determined by the root element
Arrays have no names and are described by the tag
Of course, someone will say that such a list of data types is very poor and “does not allow you to expand.” Yes, if you need to transfer complex objects or large amounts of data, then it is better to use SOAP. And for small, undemanding applications, XML-RPC is quite suitable; moreover, very often even its capabilities turn out to be too many! Considering the ease of deployment, a very large number of libraries for almost any language and platform, and wide support in PHP, then XML-RPC often simply has no competitors. Although it cannot be immediately recommended as a universal solution - in each specific case it must be decided according to the circumstances.