Analysis of large volumes of data. Big Data Machine. Scaling and tiering
Based on materials from research&trends
Big Data has been the talk of the IT and marketing press for several years now. And it’s clear: digital technologies have permeated life modern man, “everything is written.” The volume of data on various aspects of life is growing, and at the same time the possibilities for storing information are growing.
Global technologies for storing information
Source: Hilbert and Lopez, `The world's technological capacity to store, communicate, and compute information,` Science, 2011 Global.
Most experts agree that accelerating data growth is an objective reality. Social networks, mobile devices, data from measuring devices, business information - these are just a few types of sources that can generate gigantic volumes of information. According to the study IDCDigital Universe, published in 2012, in the next 8 years the amount of data in the world will reach 40 ZB (zettabytes), which is equivalent to 5200 GB for every inhabitant of the planet.
Growth of digital information collection in the US

Source: IDC
A significant part of the information is created not by people, but by robots interacting both with each other and with other data networks - such as, for example, sensors and smart devices. At this rate of growth, the amount of data in the world, according to researchers, will double every year. Number of virtual and physical servers in the world will grow tenfold due to the expansion and creation of new data centers. As a result, there is a growing need to effectively use and monetize this data. Since using Big Data in business requires considerable investment, you need to clearly understand the situation. And it is, in essence, simple: you can increase business efficiency by reducing costs and/or increasing sales volume.
Why do we need Big Data?
The Big Data paradigm defines three main types of problems.
- Storing and managing hundreds of terabytes or petabytes of data that conventional relational databases cannot effectively utilize.
- Organize unstructured information consisting of texts, images, videos and other types of data.
- Big Data analysis, which raises the question of ways to work with unstructured information, generation of analytical reports, as well as the implementation of predictive models.
The Big Data project market intersects with the business analytics (BA) market, the global volume of which, according to experts, amounted to about $100 billion in 2012. It includes components of network technologies, servers, software and technical services.
Also, the use of Big Data technologies is relevant for income assurance (RA) class solutions designed to automate the activities of companies. Modern systems income guarantees include tools for detecting inconsistencies and in-depth data analysis, allowing timely detection of possible losses or distortion of information that could lead to a decrease in financial results. Against this background, Russian companies, confirming the presence of demand for Big Data technologies in the domestic market, note that the factors that stimulate the development of Big Data in Russia are data growth, acceleration of management decision-making and improvement of their quality.
What prevents you from working with Big Data
Today, only 0.5% of accumulated digital data is analyzed, despite the fact that there are objectively industry-wide problems that could be solved using analytical solutions Big Data class. Developed IT markets already have results that can be used to evaluate expectations associated with the accumulation and processing of big data.
One of the main factors that slows down the implementation of Big Data projects, in addition to high cost, is considered problem of selecting processed data: that is, determining which data needs to be retrieved, stored and analyzed, and which should be ignored.
Many business representatives note that difficulties in implementing Big Data projects are associated with a lack of specialists - marketers and analysts. The speed of return on investment in Big Data directly depends on the quality of work of employees engaged in in-depth and predictive analytics. The enormous potential of data already existing in an organization often cannot be effectively used by marketers themselves due to outdated business processes or internal regulations. Therefore, Big Data projects are often perceived by businesses as difficult not only to implement, but also to evaluate the results: the value of the collected data. The specific nature of working with data requires marketers and analysts to switch their attention from technology and creating reports to solving specific business problems.
Due to the large volume and high speed data flow, the process of collecting it involves ETL procedures in real time. For reference:ETL – fromEnglishExtract, Transform, Load- literally “extracting, transforming, loading”) - one of the main processes in management data warehouses, which includes: retrieving data from external sources, their transformation and cleaning to meet needs ETL should be viewed not only as a process of moving data from one application to another, but also as a tool for preparing data for analysis.
And then the issues of ensuring the security of data coming from external sources must have solutions that correspond to the volume of information collected. Since Big Data analysis methods are developing only following the growth in data volume, the ability of analytical platforms to use new methods of preparing and aggregating data plays a big role. This suggests that, for example, data about potential buyers or a massive data warehouse with the history of clicks on online shopping sites may be of interest for solving various problems.
Difficulties don't stop
Despite all the difficulties with the implementation of Big Data, the business intends to increase investments in this area. As follows from Gartner data, in 2013, 64% of the world's largest companies have already invested, or have plans to invest in deploying Big Data technologies for their business, while in 2012 there were 58%. According to Gartner research, the leaders in industries investing in Big Data are media companies, telecoms, banking and service companies. Successful results from the implementation of Big Data have already been achieved by many major players in the retail industry in terms of the use of data obtained using radio frequency identification tools, logistics and relocation systems. replenishment- accumulation, replenishment - R&T), as well as from loyalty programs. Successful retail experience encourages other market sectors to find new ones effective ways monetization of big data to turn its analysis into a resource that works for business development. Thanks to this, according to experts, in the period until 2020, investments in management and storage will decrease per gigabyte of data from $2 to $0.2, but for the study and analysis of the technological properties of Big Data will increase by only 40%.
Costs presented in different investment projects in the field of Big Data, have a different nature. Cost items depend on the types of products that are selected based on certain decisions. The largest part of the costs in investment projects, according to experts, falls on products related to the collection, structuring of data, cleaning and information management.
How it's done
There are many combinations of software and hardware, which allow you to create effective solutions Big Data for various business disciplines: from social media and mobile applications, before predictive analysis and visualization of business data. An important advantage of Big Data is the compatibility of new tools with databases widely used in business, which is especially important when working with cross-disciplinary projects, such as organizing multi-channel sales and customer support.
The sequence of working with Big Data consists of collecting data, structuring the information received using reports and dashboards, creating insights and contexts, and formulating recommendations for action. Since working with Big Data involves large costs for collecting data, the result of processing of which is unknown in advance, the main task is to clearly understand what the data is for, and not how much of it is available. In this case, data collection turns into a process of obtaining information exclusively necessary for solving specific problems.
For example, telecommunications providers aggregate a huge amount of data, including geolocation, which is constantly updated. This information may be of commercial interest to advertising agencies, who may use it to deliver targeted and local advertising, as well as to retailers and banks. Such data can play an important role when deciding to open a retail outlet in a certain location based on data about the presence of a powerful targeted flow of people. There is an example of measuring the effectiveness of advertising on outdoor billboards in London. Now the reach of such advertising can only be measured by placing people near advertising structures with a special device that counts passers-by. Compared to this type of advertising effectiveness measurement, mobile operator much more possibilities - he knows exactly the location of his subscribers, he knows their demographic characteristics, gender, age, marital status, etc.
Based on such data, in the future there is the prospect of changing the content of the advertising message, using the preferences of a particular person passing by the billboard. If the data shows that a person passing by travels a lot, then he could be shown an advertisement for a resort. The organizers of a football match can only estimate the number of fans when they come to the match. But if they had the opportunity to request from the operator cellular communication information about where visitors were an hour, a day or a month before the match, this would give organizers the opportunity to plan places to advertise the next matches.
Another example is how banks can use Big Data to prevent fraud. If the client reports the loss of the card, and when making a purchase with it, the bank sees in real time the location of the client’s phone in the purchase area where the transaction takes place, the bank can check the information on the client’s application to see if he was trying to deceive him. Or the opposite situation, when a client makes a purchase in a store, the bank sees that the card used for the transaction and the client’s phone are in the same place, the bank can conclude that the card owner is using it. Thanks to such advantages of Big Data, the boundaries of traditional data warehouses are being expanded.
To successfully make a decision to implement Big Data solutions, a company needs to calculate an investment case, and this causes great difficulties due to many unknown components. The paradox of analytics in such cases is predicting the future based on the past, data about which is often missing. In this case, an important factor is clear planning of your initial actions:
- First, it is necessary to determine one specific business problem for which Big Data technologies will be used; this task will become the core of determining the correctness of the chosen concept. You need to focus on collecting data related to this specific task, and during the proof of concept, you can use various tools, processes and management techniques that will allow you to make more informed decisions in the future.
- Secondly, it is unlikely that a company without data analytics skills and experience will be able to successfully implement a Big Data project. The necessary knowledge always stems from previous analytics experience, which is the main factor influencing the quality of working with data. The culture of using data plays an important role, since often the analysis of information reveals the harsh truth about business, and to accept this truth and work with it, developed methods of working with data are necessary.
- Third, the value of Big Data technologies lies in providing insights. Good analysts remain in short supply in the market. They are usually called specialists who have a deep understanding of the commercial meaning of data and know how to use it correctly. Data analysis is a means to achieve business goals, and to understand the value of Big Data, you need to behave accordingly and understand your actions. In this case, big data will provide a lot useful information about consumers, on the basis of which decisions can be made that are useful for business.
Despite the fact that the Russian Big Data market is just beginning to take shape, individual projects in this area are already being implemented quite successfully. Some of them are successful in the field of data collection, such as projects for the Federal Tax Service and Tinkoff Credit Systems Bank, others - in terms of data analysis and practical application of its results: this is the Synqera project.
Tinkoff Credit Systems Bank implemented a project to implement the EMC2 Greenplum platform, which is a tool for massively parallel computing. In recent years, the bank has increased requirements for the speed of processing accumulated information and analyzing data in real time, caused by the high growth rate of the number of users credit cards. The Bank announced plans to expand the use of Big Data technologies, in particular for processing unstructured data and working with corporate information obtained from various sources.
The Federal Tax Service of Russia is currently creating an analytical layer for the federal data warehouse. On its basis a single information space and technology for accessing tax data for statistical and analytical processing. During the implementation of the project, work is being carried out to centralize analytical information from more than 1,200 sources at the local level of the Federal Tax Service.
One more interesting example big data analysis in real time is the Russian startup Synqera, which developed the Simplate platform. The solution is based on processing large amounts of data; the program analyzes information about customers, their purchase history, age, gender and even mood. At the checkout counters in a chain of cosmetic stores were installed touch screens with sensors that recognize customer emotions. The program determines a person’s mood, analyzes information about him, determines the time of day and scans the store’s discount database, after which it sends targeted messages to the buyer about promotions and special offers. This solution increases customer loyalty and increases retailers' sales.
If we talk about foreign successful cases, then the experience of using Big Data technologies in the Dunkin`Donuts company, which uses real-time data to sell products, is interesting in this regard. Digital displays in stores display offers that change every minute, depending on the time of day and product availability. Using cash receipts, the company receives data on which offers received the greatest response from customers. This data processing approach allowed us to increase profits and turnover of goods in the warehouse.
As the experience of implementing Big Data projects shows, this area is designed to successfully solve modern business problems. At the same time, an important factor in achieving commercial goals when working with big data is choosing the right strategy, which includes analytics that identify consumer requests, as well as the use innovative technologies in the field of Big Data.
According to a global survey conducted annually by Econsultancy and Adobe since 2012 among corporate marketers, “big data” that characterizes people’s actions on the Internet can do a lot. They can optimize offline business processes, help understand how owners of mobile devices use them to search for information, or simply “make marketing better,” i.e. more efficient. Moreover, the latter function is becoming more and more popular from year to year, as follows from the diagram we presented.
The main areas of work of Internet marketers in terms of customer relations

Source: Econsultancy and Adobe, published– emarketer.com
Note that the nationality of the respondents of great importance does not have. As a survey conducted by KPMG in 2013 shows, the share of “optimists”, i.e. those who use Big Data when developing a business strategy is 56%, and the variations from region to region are small: from 63% in North American countries to 50% in EMEA.
Using Big Data in different regions of the world

Source: KPMG, published– emarketer.com
Meanwhile, the attitude of marketers to such “fashion trends” is somewhat reminiscent of a well-known joke:
Tell me, Vano, do you like tomatoes?
- I like to eat, but not like this.
Despite the fact that marketers verbally “love” Big Data and seem to even use it, in reality, “everything is complicated,” as they write about their heartfelt affections on social networks.
According to a survey conducted by Circle Research in January 2014 among European marketers, 4 out of 5 respondents do not use Big Data (even though they, of course, “love it”). The reasons are different. There are few inveterate skeptics - 17% and exactly the same number as their antipodes, i.e. those who confidently answer: “Yes.” The rest are hesitating and doubting, the “swamp”. They avoid a direct answer under plausible pretexts such as “not yet, but soon” or “we’ll wait until the others start.”
Use of Big Data by marketers, Europe, January 2014

Source:dnx, published –emarketer.com
What confuses them? Pure nonsense. Some (exactly half of them) simply do not believe this data. Others (there are also quite a few of them - 55%) find it difficult to correlate sets of “data” and “users” with each other. Some people simply have (to put it politically correctly) an internal corporate mess: data is wandering unattended between marketing departments and IT structures. For others, the software cannot cope with the influx of work. And so on. Since the total shares significantly exceed 100%, it is clear that the situation of “multiple barriers” is not uncommon.
Barriers to the use of Big Data in marketing

Source:dnx, published –emarketer.com
Thus, we have to admit that for now “Big Data” is a great potential that still needs to be taken advantage of. By the way, this may be the reason that Big Data is losing its halo of a “fashionable trend,” as evidenced by a survey conducted by the company Econsultancy, which we have already mentioned.
The most significant trends in digital marketing 2013-2014

Source: Econsultancy and Adobe
They are being replaced by another king - content marketing. How long?
It cannot be said that Big Data is some kind of fundamentally new phenomenon. Large sources of data have existed for many years: databases on customer purchases, credit histories, lifestyle. And for years, scientists have used this data to help companies assess risk and predict future customer needs. However, today the situation has changed in two aspects:
More sophisticated tools and techniques have emerged to analyze and combine different data sets;
These analytical tools are complemented by an avalanche of new data sources driven by the digitalization of virtually all data collection and measurement methods.
The range of information available is both inspiring and daunting for researchers raised in structured research environments. Consumer sentiment is captured by websites and all sorts of social media. The fact of viewing an advertisement is recorded not only set-top boxes, but also using digital tags and mobile devices communicating with the TV.
Behavioral data (such as call volume, shopping habits and purchases) is now available in real time. Thus, much of what could previously be obtained through research can now be learned using big data sources. And all these information assets are generated constantly, regardless of any research processes. These changes make us wonder whether big data can replace classic market research.
It's not about the data, it's about the questions and answers.
Before we sound the death knell for classic research, we must remind ourselves that it is not the presence of certain data assets that is critical, but something else. What exactly? Our ability to answer questions, that's what. One funny thing about the new world of big data is that the results obtained from new data assets lead to even more questions, and these questions are usually best answered by traditional research. Thus, as big data grows, we see a parallel increase in the availability and need for “small data” that can provide answers to questions from the world of big data.
Consider the situation: a large advertiser continuously monitors store traffic and sales volumes in real time. Existing research methodologies (in which we survey panelists about their purchasing motivations and point-of-sale behavior) help us better target specific buyer segments. These techniques can be expanded to include a wider range of big data assets, to the point where big data becomes a means of passive observation, and research becomes a method of ongoing, narrowly focused investigation of changes or events that require study. This is how big data can free research from unnecessary routine. Primary research no longer has to focus on what is happening (big data will do that). Instead, primary research can focus on explaining why we observe particular trends or deviations from trends. The researcher will be able to think less about obtaining data and more about how to analyze and use it.
At the same time, we see that big data can solve one of our biggest problems: the problem of overly long studies. Examination of the studies themselves has shown that over-inflated research instruments have a negative impact on data quality. Although many experts had long acknowledged this problem, they invariably responded with the phrase, “But I need this information for senior management,” and the long interviews continued.
In the world of big data, where quantitative metrics can be obtained through passive observation, this issue becomes moot. Again, let's think about all these studies regarding consumption. If big data gives us insight into consumption through passive observation, then primary survey research no longer needs to collect this kind of information, and we can finally back up our vision of short surveys with something more than wishful thinking.
Big Data needs your help
Finally, “big” is just one characteristic of big data. The characteristic “large” refers to the size and scale of the data. Of course, this is the main characteristic, since the volume of this data is beyond anything we have worked with before. But other characteristics of these new data streams are also important: they are often poorly formatted, unstructured (or, at best, partially structured), and full of uncertainty. An emerging field of data management, aptly named entity analytics, addresses the problem of cutting through the noise in big data. Its job is to analyze these data sets and figure out how many observations refer to the same person, which observations are current, and which ones are usable.
This type of data cleaning is necessary to remove noise or erroneous data when working with large or small data assets, but it is not sufficient. We must also create context around big data assets based on our previous experience, analytics, and category knowledge. In fact, many analysts point to the ability to manage the uncertainty inherent in big data as a source of competitive advantage, as it enables better decisions to be made.
This is where primary research not only finds itself liberated by big data, but also contributes to content creation and analysis within big data.
A prime example of this is the application of our new fundamentally different brand equity framework to social media (we are talking about developed inMillward Browna new approach to measuring brand equityThe Meaningfully Different Framework– “The Meaningful Difference Paradigm” -R & T ). The model is behaviorally tested within specific markets, implemented on a standard basis, and can be easily applied to other marketing verticals and decision support information systems. In other words, our brand equity model, informed by (though not exclusively based on) survey research, has all the features needed to overcome the unstructured, disjointed, and uncertain nature of big data.
Consider consumer sentiment data provided by social media. In raw form, peaks and troughs in consumer sentiment are very often minimally correlated with offline measures of brand equity and behavior: there is simply too much noise in the data. But we can reduce this noise by applying our models of consumer meaning, brand differentiation, dynamics, and distinctiveness to raw consumer sentiment data—a way of processing and aggregating social media data along these dimensions.
Once the data is organized according to our framework, the trends identified typically align with offline brand equity and behavioral measures. Essentially, social media data cannot speak for itself. To use them for this purpose requires our experience and models built around brands. When social media gives us unique information expressed in the language consumers use to describe brands, we must use that language when creating our research to make primary research much more effective.
Benefits of Exempt Research
This brings us back to how big data is not so much replacing research as liberating it. Researchers will be freed from the need to create a new study for each new case. The ever-growing big data assets can be used for different research topics, allowing subsequent primary research to delve deeper into the topic and fill existing gaps. Researchers will be freed from having to rely on over-inflated surveys. Instead, they can use short surveys and focus on the most important parameters, which improves data quality.
With this liberation, researchers will be able to use their established principles and ideas to add precision and meaning to big data assets, leading to new areas for survey research. This cycle should lead to greater understanding on a range of strategic issues and, ultimately, movement towards what should always be our primary goal - to inform and improve the quality of brand and communications decisions.
Usually, when they talk about serious analytical processing, especially if they use the term Data Mining, they mean that there is a huge amount of data. In general, this is not the case, since quite often you have to process small data sets, and finding patterns in them is no easier than in hundreds of millions of records. Although there is no doubt that the need to search for patterns in large databases complicates the already non-trivial task of analysis.
This situation is especially typical for businesses associated with retail trade, telecommunications, banks, Internet. Their databases accumulate a huge amount of information related to transactions: checks, payments, calls, logs, etc.
There are no universal methods of analysis or algorithms suitable for all cases and any amount of information. Data analysis methods vary significantly in performance, quality of results, ease of use, and data requirements. Optimization can be carried out at various levels: equipment, databases, analytical platform, preparation of initial data, specialized algorithms. Analysis of a large volume of data requires a special approach, because... it is technically difficult to process them using only " brute force", i.e. using more powerful equipment.
Of course, it is possible to increase data processing speed due to more efficient hardware, especially since modern servers and workstations use multi-core processors, RAM significant size and powerful disk arrays. However, there are many other ways to process large amounts of data that allow for increased scalability and do not require endless renewal equipment.
DBMS capabilities
Modern databases include various mechanisms, the use of which will significantly increase the speed of analytical processing:
- Preliminary data calculation. Information that is most often used for analysis can be calculated in advance (for example, at night) and stored in a form prepared for processing on the database server in the form of multidimensional cubes, materialized views, and special tables.
- Caching tables into RAM. Data that takes up little space but is often accessed during the analysis process, for example, directories, can be cached into RAM using database tools. This reduces calls to the slower disk subsystem many times over.
- Partitioning tables into partitions and tablespaces. You can place data, indexes, and auxiliary tables on separate disks. This will allow the DBMS to read and write information to disks in parallel. In addition, tables can be divided into partitions so that when accessing data there is a minimum number of disk operations. For example, if we most often analyze data for the last month, then we can logically use one table with historical data, but physically split it into several partitions, so that when accessing monthly data, a small partition is read and there are no accesses to all historical data.
This is only part of the capabilities that modern DBMSs provide. You can increase the speed of retrieving information from a database in a dozen other ways: rational indexing, building query plans, parallel processing of SQL queries, using clusters, preparing analyzed data using stored procedures and triggers on the side of the database server, etc. Moreover, many of these mechanisms can be used using not only “heavy” DBMSs, but also free databases data.
Combining models
The possibilities for increasing speed are not limited to optimizing the performance of the database; a lot can be done by combining different models. It is known that processing speed is significantly related to the complexity of the mathematical apparatus used. The simpler the analysis mechanisms are used, the faster the data is analyzed.
It is possible to construct a data processing scenario in such a way that the data is “run” through a sieve of models. A simple idea applies here: don't waste time processing what you don't need to analyze.
The simplest algorithms are used first. Part of the data that can be processed using such algorithms and which is pointless to process using more complex methods, is analyzed and excluded from further processing. The remaining data is transferred to the next processing stage, where more complex algorithms are used, and so on down the chain. At the last node of the processing script, the most complex algorithms are used, but the volume of analyzed data is many times smaller than the initial sample. As a result, the total time required to process all data is reduced by orders of magnitude.
Let's give practical example using this approach. When solving the problem of demand forecasting, it is initially recommended to conduct an XYZ analysis, which allows you to determine how stable the demand for various goods is. Products of group X are sold quite consistently, so applying forecasting algorithms to them allows us to obtain a high-quality forecast. Products of group Y are sold less consistently, perhaps it is worth building models for them not for each article, but for the group, this allows you to smooth out the time series and ensure the operation of the forecasting algorithm. Products of group Z are sold chaotically, so there is no need to build predictive models for them at all; the need for them should be calculated based on simple formulas, for example, average monthly sales.
According to statistics, about 70% of the assortment consists of products from group Z. Another about 25% are products from group Y, and only about 5% are products from group X. Thus, the construction and application of complex models is relevant for a maximum of 30% of products. Therefore, using the approach described above will reduce the time for analysis and forecasting by 5-10 times.
Parallel Processing
Another effective strategy for processing large amounts of data is to split the data into segments and build models for each segment separately, then combining the results. Most often, in large volumes of data, several subsets that differ from each other can be identified. These could be, for example, groups of customers, products that behave in a similar way and for which it is advisable to build one model.
In this case, instead of building one complex model for everyone, you can build several simple ones for each segment. This approach allows you to increase the speed of analysis and reduce memory requirements by processing smaller amounts of data in a single pass. In addition, in this case, analytical processing can be parallelized, which also has a positive effect on the time spent. In addition, different analysts can build models for each segment.
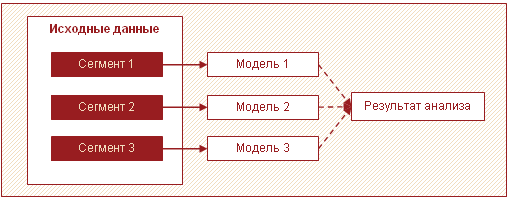
In addition to increasing speed, this approach has another important advantage - several relatively simple models individually are easier to create and maintain than one large one. You can run models in stages, thus obtaining the first results in the shortest possible time.
Representative samples
If large volumes of data are available, not all information can be used to build a model, but a certain subset - a representative sample. A correctly prepared representative sample contains the information necessary to build a high-quality model.
The analytical processing process is divided into 2 parts: building a model and applying the constructed model to new data. Building a complex model is a resource-intensive process. Depending on the algorithm used, the data is cached, scanned thousands of times, many auxiliary parameters are calculated, etc. Applying an already built model to new data requires tens and hundreds of times less resources. Very often this comes down to calculating a few simple functions.
Thus, if the model is built on relatively small sets and subsequently applied to the entire data set, then the time to obtain the result will be reduced by orders of magnitude compared to an attempt to completely process the entire existing data set.

To obtain representative samples, there are special methods, for example, sampling. Their use makes it possible to increase the speed of analytical processing without sacrificing the quality of the analysis.
Summary
The described approaches are only a small part of the methods that allow you to analyze huge amounts of data. There are other methods, for example, the use of special scalable algorithms, hierarchical models, window learning, etc.
Analysis huge bases Data management is a non-trivial task that in most cases cannot be solved head-on, but modern databases and analytical platforms offer many methods for solving this problem. When used wisely, systems are capable of processing terabytes of data at an acceptable speed.
Column by HSE teachers about myths and cases of working with big data
To bookmarks
Teachers at the School of New Media at the National Research University Higher School of Economics Konstantin Romanov and Alexander Pyatigorsky, who is also the director of digital transformation at Beeline, wrote a column for the site about the main misconceptions about big data - examples of using the technology and tools. The authors suggest that the publication will help company managers understand this concept.
Myths and misconceptions about Big Data
Big Data is not marketing
The term Big Data has become very fashionable - it is used in millions of situations and with hundreds of different interpretations, often not related to what it is. Concepts are often substituted in people’s heads, and Big Data is confused with a marketing product. Moreover, in some companies Big Data is part of the marketing department. The result of big data analysis can indeed be a source for marketing activity, but nothing more. Let's see how it works.
If we identified a list of those who bought goods worth more than three thousand rubles in our store two months ago, and then sent these users some kind of offer, then this is typical marketing. We derive a clear pattern from the structural data and use it to increase sales.
However, if we combine CRM data with streaming information from, for example, Instagram, and analyze it, we find a pattern: a person who has reduced his activity on Wednesday evening and whose latest photo shows kittens should make a certain offer. This will already be Big Data. We found a trigger, passed it on to marketers, and they used it for their own purposes.
It follows from this that technology usually works with unstructured data, and even if the data is structured, the system still continues to look for hidden patterns in it, which marketing does not do.
Big Data is not IT
The second extreme of this story: Big Data is often confused with IT. This is due to the fact that in Russian companies As a rule, IT specialists are the drivers of all technologies, including big data. Therefore, if everything happens in this department, the company as a whole gets the impression that this is some kind of IT activity.
In fact, there is a fundamental difference here: Big Data is an activity aimed at obtaining a specific product, which is not at all related to IT, although technology cannot exist without it.
Big Data is not always the collection and analysis of information
There is another misconception about Big Data. Everyone understands that this technology involves large amounts of data, but what kind of data is meant is not always clear. Anyone can collect and use information; now this is possible not only in films about, but also in any, even a very small company. The only question is what exactly to collect and how to use it to your advantage.
But it should be understood that Big technology Data will not be the collection and analysis of absolutely any information. For example, if you collect data about a specific person on social networks, it will not be Big Data.
What is Big Data really?
Big Data consists of three elements:
- data;
- analytics;
- technologies.
Big Data is not just one of these components, but a combination of all three elements. People often substitute concepts: some believe that Big Data is just data, others believe that it is technology. But in fact, no matter how much data you collect, you can't do anything with it without necessary technologies and analysts. If there is good analytics, but no data, it’s even worse.
If we talk about data, this is not only texts, but also all the photos posted on Instagram, and in general everything that can be analyzed and used for different purposes and tasks. In other words, Data refers to huge volumes of internal and external data of various structures.
Analytics is also needed, because the task of Big Data is to build some patterns. That is, analytics is the identification of hidden dependencies and the search for new questions and answers based on the analysis of the entire volume of heterogeneous data. Moreover, Big Data poses questions that cannot be directly derived from this data.
When it comes to images, the fact that you post a photo of yourself wearing a blue T-shirt doesn't mean anything. But if you use photography for Big Data modeling, it may turn out that right now you should offer a loan, because in your social group such behavior indicates a certain phenomenon in action. Therefore, “bare” data without analytics, without identifying hidden and non-obvious dependencies is not Big Data.
So we have big data. Their array is huge. We also have an analyst. But how can we make sure that from this raw data we come up with a specific solution? To do this, we need technologies that allow us not only to store them (and this was impossible before), but also to analyze them.
Simply put, if you have a lot of data, you will need technologies, for example, Hadoop, which make it possible to store all the information in its original form for later analysis. This kind of technology arose in Internet giants, since they were the first to face the problem of storing a large amount of data and analyzing it for subsequent monetization.
In addition to tools for optimized and cheap data storage, you need analytical tools, as well as add-ons to the platform used. For example, a whole ecosystem of related projects and technologies has already formed around Hadoop. Here are some of them:
- Pig is a declarative data analysis language.
- Hive - data analysis using a language similar to SQL.
- Oozie - Hadoop workflow.
- Hbase is a database (non-relational), similar to Google Big Table.
- Mahout - machine learning.
- Sqoop - transferring data from RSDB to Hadoop and vice versa.
- Flume - transferring logs to HDFS.
- Zookeeper, MRUnit, Avro, Giraph, Ambari, Cassandra, HCatalog, Fuse-DFS and so on.
All of these tools are available to everyone for free, but there are also a number of paid add-ons.
In addition, specialists are needed: a developer and an analyst (the so-called Data Scientist). A manager is also needed who can understand how to apply this analytics to solve a specific problem, because in itself it is completely meaningless if it is not integrated into business processes.
All three employees must work as a team. A manager who gives a Data Science specialist the task of finding a certain pattern must understand that he will not always find exactly what he needs. In this case, the manager should listen carefully to what the Data Scientist found, since often his findings turn out to be more interesting and useful for the business. Your job is to apply this to a business and make a product out of it.
Despite the fact that now there are many different kinds of machines and technologies, the final decision always remains with the person. To do this, the information needs to be visualized somehow. There are quite a lot of tools for this.
The most telling example is geoanalytical reports. The Beeline company works a lot with the governments of different cities and regions. Very often, these organizations order reports like “Traffic congestion in a certain location.”
It is clear that such a report should reach government agencies in a simple and understandable form. If we provide them with a huge and completely incomprehensible table (that is, information in the form in which we receive it), they are unlikely to buy such a report - it will be completely useless, they will not get from it the knowledge that they wanted to receive.
Therefore, no matter how good the data scientists are and no matter what patterns they find, you will not be able to work with this data without good visualization tools.
Data sources
The array of data obtained is very large, so it can be divided into several groups.
Internal company data
Although 80% of the data collected belongs to this group, this source is not always used. Often this is data that seemingly no one needs at all, for example, logs. But if you look at them from a different angle, you can sometimes find unexpected patterns in them.
Shareware sources
This includes data social networks, the Internet and everything where you can get into it for free. Why is it shareware free? On the one hand, this data is available to everyone, but if you are a large company, then obtaining it in the size of a subscriber base of tens of thousands, hundreds or millions of customers is no longer an easy task. Therefore, there are paid services to provide this data.
Paid sources
This includes companies that sell data for money. These may be telecoms, DMPs, Internet companies, credit bureaus and aggregators. In Russia, telecoms do not sell data. Firstly, it is economically unprofitable, and secondly, it is prohibited by law. Therefore, they sell the results of their processing, for example, geoanalytical reports.
Open data
The state is accommodating to businesses and gives them the opportunity to use the data they collect. This is developed to a greater extent in the West, but Russia in this regard also keeps up with the times. For example, there is an Open Data Portal of the Moscow Government, where information on various urban infrastructure facilities is published.
For residents and guests of Moscow, the data is presented in tabular and cartographic form, and for developers - in special machine-readable formats. While the project is working in a limited mode, it is developing, which means it is also a source of data that you can use for your business tasks.
Research
As already noted, the task of Big Data is to find a pattern. Often, research conducted around the world can become a fulcrum for finding a particular pattern - you can get a specific result and try to apply similar logic for your own purposes.
Big Data is an area in which not all the laws of mathematics apply. For example, “1” + “1” is not “2”, but much more, because by mixing data sources the effect can be significantly enhanced.
Product examples
Many people are familiar with the music selection service Spotify. It’s great because it doesn’t ask users what their mood is today, but rather calculates it based on the sources available to it. He always knows what you need now - jazz or hard rock. This is the key difference that provides it with fans and distinguishes it from other services.

Such products are usually called sense products - those that feel their customers.
Big Data technology is also used in the automotive industry. For example, Tesla does this - in their latest model there is an autopilot. The company strives to create a car that itself will take the passenger where he needs to go. Without Big Data, this is impossible, because if we use only the data that we receive directly, as a person does, then the car will not be able to improve.

When we drive a car ourselves, we use our neurons to make decisions based on many factors that we don’t even notice. For example, we may not realize why we decided not to immediately accelerate at a green light, but then it turns out that the decision was correct - a car rushed past you at breakneck speed, and you avoided an accident.
You can also give an example of using Big Data in sports. In 2002, the general manager of the Oakland Athletics baseball team, Billy Beane, decided to break the paradigm of how to recruit athletes - he selected and trained players “by the numbers.”
Usually managers look at the success of players, but in this case everything was different - in order to get results, the manager studied what combinations of athletes he needed, paying attention to individual characteristics. Moreover, he chose athletes who in themselves did not have much potential, but the team as a whole turned out to be so successful that they won twenty matches in a row.

Director Bennett Miller subsequently made a film dedicated to this story - “The Man Who Changed Everything” starring Brad Pitt.
Big Data technology is also useful in the financial sector. Not a single person in the world can independently and accurately determine whether it is worth giving someone a loan. In order to make a decision, scoring is performed, that is, a probabilistic model is built, from which one can understand whether this person will return the money or not. Further, scoring is applied at all stages: you can, for example, calculate that at a certain moment a person will stop paying.
Big data allows you not only to make money, but also to save it. In particular, this technology helped the German Ministry of Labor to reduce the cost of unemployment benefits by 10 billion euros, since after analyzing the information it became clear that 20% of benefits were paid undeservedly.
Technologies are also used in medicine (this is especially typical for Israel). With the help of Big Data, you can perform a much more accurate analysis than a doctor with thirty years of experience can do.
Any doctor, when making a diagnosis, relies only on his own own experience. When the machine does this, it comes from the experience of thousands of such doctors and all the existing case histories. It takes into account what material the patient’s house is made of, what area the victim lives in, what kind of smoke there is, and so on. That is, it takes into account a lot of factors that doctors do not take into account.
An example of the use of Big Data in healthcare is the Project Artemis project, which was implemented by the Toronto Children's Hospital. This Information system, which collects and analyzes data on babies in real time. The machine allows you to analyze 1260 health indicators of each child every second. This project is aimed at predicting the unstable condition of a child and preventing diseases in children.
Big data is also starting to be used in Russia: for example, Yandex has a big data division. The company, together with AstraZeneca and the Russian Society of Clinical Oncology RUSSCO, launched the RAY platform, intended for geneticists and molecular biologists. The project allows us to improve methods for diagnosing cancer and identifying predisposition to cancer. The platform will launch in December 2016.
The term Big Data usually refers to any amount of structured, semi-structured and unstructured data. However, the second and third ones can and should be ordered for subsequent information analysis. Big data does not equate to any actual volume, but when talking about Big Data in most cases we mean terabytes, petabytes and even extrabytes of information. Any business can accumulate this amount of data over time, or, in cases where a company needs to receive a lot of information, in real time.
Big Data Analysis
When talking about Big Data analysis, we primarily mean the collection and storage of information from various sources. For example, data about customers who made purchases, their characteristics, information about launched advertising companies and evaluation of its effectiveness, data contact center. Yes, all this information can be compared and analyzed. It is possible and necessary. But to do this, you need to set up a system that allows you to collect and transform information without distorting it, store it and, finally, visualize it. Agree, with big data, tables printed on several thousand pages are of little help for making business decisions.
1. Arrival of big data
Most services that collect information about user actions have the ability to export. To ensure that they arrive at the company in a structured form, various systems are used, for example, Alteryx. This software allows you to receive automatic mode information, process it, but most importantly - convert it into the right type and the format without distorting.
2. Storage and processing of big data
Almost always, when collecting large amounts of information, the problem of storing it arises. Of all the platforms that we studied, our company prefers Vertica. Unlike other products, Vertica is able to quickly “give back” the information stored in it. The disadvantages include long recording, but when analyzing big data, the speed of return comes to the fore. For example, if we are talking about compilation using a petabyte of information, the upload speed is one of the most important characteristics.
3. Big Data Visualization
And finally, the third stage of analyzing large volumes of data is . To do this, you need a platform that can visually reflect all received information in a convenient form. In our opinion, only one software product can cope with the task - Tableau. Certainly one of the best on today a solution that can visually show any information, turning the company’s work into a three-dimensional model, collecting the actions of all departments into a single interdependent chain (you can read more about Tableau’s capabilities).
Instead, let’s note that almost any company can now create its own Big Data. Big data analysis is no longer a complex and expensive process. Company management is now required to correctly formulate questions to collected information, while there are virtually no invisible gray areas left.
Download Tableau