Utilisation combinée du régulateur PID et du filtre Kalman. Utilisation d'un filtre de Kalman pour traiter une séquence de coordonnées GPS. Matrice de covariance du bruit de mesure
Random Forest est l'un de mes algorithmes d'exploration de données préférés. Premièrement, il est incroyablement polyvalent ; il peut être utilisé pour résoudre à la fois des problèmes de régression et de classification. Recherchez des anomalies et sélectionnez des prédicteurs. Deuxièmement, il s’agit d’un algorithme très difficile à appliquer de manière incorrecte. Tout simplement parce que, contrairement à d’autres algorithmes, il possède peu de paramètres personnalisables. Et c’est aussi étonnamment simple dans son essence. Et en même temps, c’est incroyablement précis.
Quelle est l’idée derrière un algorithme aussi merveilleux ? L'idée est simple : disons que nous avons un algorithme très faible, disons . Si nous créons de nombreux modèles différents en utilisant cet algorithme faible et faisons la moyenne des résultats de leurs prédictions, le résultat final sera nettement meilleur. C’est ce qu’on appelle l’apprentissage d’ensemble en action. L’algorithme Random Forest est donc appelé « Random Forest » ; pour les données reçues, il crée de nombreux arbres de décision puis fait la moyenne du résultat de leurs prédictions. Le point important ici est la part de hasard dans la création de chaque arbre. Après tout, il est clair que si nous créons de nombreux arbres identiques, le résultat de leur moyenne aura la précision d'un arbre.
Comment travaille-t-il ? Supposons que nous ayons des données d'entrée. Chaque colonne correspond à un paramètre, chaque ligne correspond à un élément de données.
Nous pouvons sélectionner aléatoirement un certain nombre de colonnes et de lignes dans l’ensemble des données et construire un arbre de décision basé sur celles-ci.

jeudi 10 mai 2012
jeudi 12 janvier 2012

C'est tout. Le vol de 17 heures est terminé, la Russie reste à l'étranger. Et à travers la fenêtre d'un confortable appartement de 2 chambres, San Francisco, la célèbre Silicon Valley, Californie, USA, nous regarde. Oui, c’est justement la raison pour laquelle je n’ai pas beaucoup écrit ces derniers temps. Nous avons déménagé.
Tout a commencé en avril 2011, lorsque j'ai eu un entretien téléphonique avec Zynga. Ensuite, tout cela ressemblait à une sorte de jeu sans rapport avec la réalité et je ne pouvais même pas imaginer à quoi cela mènerait. En juin 2011, Zynga est venu à Moscou et a mené une série d'entretiens, environ 60 candidats ayant réussi un entretien téléphonique ont été examinés et environ 15 personnes ont été sélectionnées parmi eux (je ne connais pas le nombre exact, certains ont ensuite changé d'avis, d'autres immédiatement refusé). L’entretien s’est avéré étonnamment simple. Pas de problèmes de programmation, pas de questions délicates sur la forme des trappes, testant principalement votre capacité à discuter. Et les connaissances, à mon avis, n’ont été évaluées que superficiellement.
Et puis le vacarme a commencé. Nous avons d'abord attendu les résultats, puis l'offre, puis l'approbation de la LCA, puis l'approbation de la demande de visa, puis les documents des États-Unis, puis la file d'attente à l'ambassade, puis une vérification supplémentaire, puis le visa. Parfois, il me semblait que j'étais prêt à tout abandonner et à marquer. Parfois, je doutais que nous ayons besoin de cette Amérique, car la Russie n’est pas mauvaise non plus. L'ensemble du processus a duré environ six mois. Finalement, à la mi-décembre, nous avons reçu les visas et avons commencé à préparer le départ.
Lundi était mon premier jour de travail dans un nouvel endroit. Le bureau offre toutes les conditions non seulement pour travailler, mais aussi pour vivre. Petits déjeuners, déjeuners et dîners de nos propres chefs, beaucoup de plats variés remplis dans tous les coins, une salle de sport, des massages et même un coiffeur. Tout cela est entièrement gratuit pour les salariés. De nombreuses personnes se rendent au travail à vélo et plusieurs locaux sont équipés pour entreposer les véhicules. En général, je n'ai jamais rien vu de tel en Russie. Cependant, tout a son prix ; on nous a tout de suite prévenus qu'il nous faudrait beaucoup travailler. Ce que signifie « beaucoup », selon leurs normes, ne m'est pas très clair.
J'espère cependant que malgré la quantité de travail, dans un avenir proche, je pourrai reprendre mon blog et, peut-être, raconter quelque chose sur la vie américaine et le travail de programmeur en Amérique. Attend et regarde. En attendant, je souhaite à tous une bonne année et Noël et à bientôt !
Pour un exemple d'utilisation, imprimons le rendement du dividende Entreprises russes. Comme prix de base, nous prenons le cours de clôture de l'action le jour de la clôture du registre. Pour une raison quelconque, ces informations ne sont pas disponibles sur le site de la Troïka, mais elles sont bien plus intéressantes que les valeurs absolues des dividendes.
Attention! Le code prend beaucoup de temps à s'exécuter, car... Pour chaque promotion, vous devez faire une demande aux serveurs Finam et obtenir sa valeur.
Résultat<- NULL for(i in (1:length(divs[,1]))){ d <- divs if (d$Divs>0)( essayer(( guillemets<- getSymbols(d$Symbol, src="Finam", from="2010-01-01", auto.assign=FALSE) if (!is.nan(quotes)){ price <- Cl(quotes) if (length(price)>0)(jj<- d$Divs result <- rbind(result, data.frame(d$Symbol, d$Name, d$RegistryDate, as.numeric(dd)/as.numeric(price), stringsAsFactors=FALSE)) } } }, silent=TRUE) } } colnames(result) <- c("Symbol", "Name", "RegistryDate", "Divs") result

De même, vous pouvez créer des statistiques pour les années précédentes.
Transcription
1 # 09, septembre 2015 UDC Application du filtre de Kalman pour le traitement d'une séquence de coordonnées GPS Listerenko R.R., baccalauréat Russie, Moscou, MSTU. N.E. Bauman, département " Logiciel ordinateur et informatique» Directeur scientifique : Bekasov D.E., assistant Russie, Moscou, MSTU du nom. N.E. Bauman, Département des logiciels informatiques et des technologies de l'information La tâche de filtrer les coordonnées GPS Actuellement, les services de suivi GPS sont largement utilisés, dont la tâche est de suivre les itinéraires des objets observés afin de les sauvegarder, de les reproduire et de les analyser davantage. Cependant, en raison de l'erreur du capteur GPS due à un certain nombre de raisons, telles que la perte du signal du satellite, les changements dans la géométrie du satellite, la réflexion du signal, les erreurs de calcul et les erreurs d'arrondi, le résultat final ne correspond pas exactement à l'itinéraire. de l'objet. Il existe à la fois des écarts mineurs (jusqu'à 100 m), qui ne gênent pas la perception des informations visuelles sur l'itinéraire et son analyse, et des écarts très importants (jusqu'à 1 km, en cas de perte du signal satellite et d'utilisation de la base stations jusqu'à plusieurs dizaines de km). Pour démontrer le résultat de l'algorithme présenté dans l'article, un itinéraire contenant des écarts par rapport à l'emplacement réel dépassant plusieurs kilomètres est utilisé. Afin de corriger de telles erreurs, un algorithme est en cours de développement pour transformer une séquence de coordonnées. Les données d'entrée de l'algorithme sont une séquence de coordonnées GPS. Chaque coordonnée contient les informations suivantes reçues du capteur : Latitude Longitude Azimut en degrés Vitesse instantanée de l'objet en un point donné en m/s
2 Écart possible des coordonnées de l'objet par rapport à la valeur réelle en mètres Temps de réception des coordonnées par le capteur Le résultat de l'algorithme est une séquence de coordonnées avec latitude et longitude corrigées. Il a été décidé d'utiliser le filtre de Kalman comme base pour construire l'algorithme, car il nous permet de prendre en compte séparément les erreurs de mesure et les erreurs aléatoires de processus, ainsi que d'utiliser la vitesse de déplacement de l'objet obtenue à partir du capteur. Construction modèle mathématique utilisation du filtre de Kalman Pour utiliser le filtre de Kalman, il faut que le processus étudié soit décrit comme suit : = + + (1) = + (2) Dans la formule (1) - le vecteur d'état du processus, A - la matrice de dimension n n, décrivant la transition du processus observé de l'état à la condition. Le vecteur décrit les influences de contrôle sur le processus. La matrice B de dimension n l mappe le vecteur d'actions de contrôle u en un changement d'état s. est une variable aléatoire décrivant les erreurs du processus étudié, et ~0, où Q est la matrice de covariance des erreurs du processus. La formule (2) décrit les mesures d'un processus aléatoire. - vecteur de l'état mesuré du processus, la matrice H de dimension m n mappe l'état du processus dans la dimension du processus. - une variable aléatoire caractérisant les erreurs de mesure, et ~0, où P est la matrice de covariance des erreurs de mesure. Puisque le processus de mouvement d'un objet est étudié, l'équation d'état est compilée sur la base de l'équation du mouvement du corps = + +!" #$ % & ". De plus, il n'y a aucune information supplémentaire sur le processus de mouvement, on considère donc que l'action de contrôle est égale à 0. Le vecteur = + () *, - est pris comme état du processus. +, où x, y sont les coordonnées de l'objet et sont les projections de la vitesse de l'objet. Ainsi, pour le processus considéré, l'équation (1) prend la forme suivante : = + /!, (3) Bulletin Scientifique et Technique Jeunesse de la FS, ISSN
3 où = ! = 3 ! + 7 " 0 ; 6 2 : 6 " / = : 6 0 : 6 2 : 6 0 : , (4)!,4, (5) (6) Dans ce modèle, l'accélération d'un objet est considérée comme un phénomène aléatoire erreur du processus. Les hypothèses suivantes sont faites : a) Les accélérations le long de différents axes sont des variables aléatoires indépendantes.),* b)
4 = AB = C. C E. = C/!!. /. =/C!!. /. Puisque les composantes du vecteur ak (5) sont des variables aléatoires indépendantes, alors C!!. = " 0 " G. Par conséquent, la formule (7) prend la forme suivante : = / " (8) Le vecteur de mesure zk pour ce problème est représenté comme suit : H I = 0 + J, J (7) 2, (9) où H, I sont les coordonnées de l'objet reçu du capteur, J +, J, est la vitesse de l'objet reçu du capteur. La matrice H dans la formule (2) est considérée comme égale à la matrice d'identité de dimension. 4 4, puisque dans le cadre de ce problème, on suppose que la mesure est une combinaison linéaire d'un vecteur d'état et de quelques erreurs aléatoires. La matrice de covariance de l'erreur de mesure R est considérée comme donnée. options possibles ses calculs utilisent des données sur la précision de mesure attendue obtenues du capteur. Application du filtre de Kalman au modèle construit Pour appliquer le filtre, il est nécessaire d'introduire les notions suivantes : - estimation a posteriori de l'état de l'objet à l'instant k, obtenue à partir des résultats d'observations jusqu'à l'instant k inclus. L est l'estimation a posteriori non corrigée de l'état de l'objet au temps k. - une matrice de covariance a posteriori des erreurs, qui spécifie une estimation de l'exactitude de l'estimation obtenue du vecteur d'état et comprend une estimation des variances d'erreur de l'état calculé et des covariances, montrant les relations identifiées entre les paramètres de l'état du système. L est la matrice d’erreur de covariance a posteriori non ajustée. La matrice P0 est mise à zéro, puisqu'on suppose que la position initiale de l'objet est connue. Bulletin scientifique et technique jeunesse de la FS, ISSN
5 Une itération du filtre de Kalman comprend deux étapes : l'extrapolation et la correction. a) Au stade de l'extrapolation, l'estimation L est calculée à partir de l'estimation du vecteur d'état L et de la matrice de covariance des erreurs L selon les formules suivantes : L =, (10) L =. +, (11) où la matrice Ak est connue grâce à la formule (4), la matrice Qk est calculée à l'aide de la formule (8). b) A l'étape de correction, la matrice des facteurs de gain Kk est calculée selon la formule suivante : M = L. L. + (12) où R, H sont considérés comme connus. Kk est utilisé pour corriger l'estimation de l'état de l'objet L et la matrice de covariance d'erreur L comme suit : = L + M L, (13) = N M L, (14) où I est la matrice d'identité. Il convient de noter que pour utiliser les relations ci-dessus, il est nécessaire que les unités de mesure soient cohérentes pour les paramètres d'objet impliqués dans les calculs. Cependant, dans les données sources, la latitude et la longitude sont indiquées en coordonnées angulaires et la vitesse en coordonnées métriques. De plus, il est également plus pratique de spécifier l'accélération pour calculer l'erreur de processus en unités métriques. Les formules de Vincenti sont utilisées pour convertir la vitesse et l'accélération en unités angulaires. Résultat du filtre Sur la Fig. La figure 1 montre un exemple de parcours avant traitement. On peut noter que dans dans cet exemple Il existe plusieurs coordonnées avec un degré d'erreur élevé, qui se traduit par la présence de « pics » de coordonnées nettement éloignés de l'itinéraire principal. En figue. La figure 2 montre le résultat du filtre fonctionnant avec cette route.

6 Fig. 1. Itinéraire d'objet Fig. 2. Le parcours de l'objet après application du filtre De ce fait, il n'y a pratiquement pas de « pics », à l'exception du plus grand, qui a été sensiblement réduit, et le reste du parcours a été lissé. Ainsi, en utilisant l'algorithme ci-dessus, il a été possible de réduire le degré de distorsion de l'itinéraire et d'augmenter sa qualité visuelle. Conclusion Cet article a examiné une approche de correction des coordonnées GPS à l'aide d'un filtre de Kalman. En utilisant l'algorithme ci-dessus, il a été possible d'éliminer les distorsions les plus visibles de l'itinéraire, ce qui démontre l'applicabilité de cette méthode au problème du lissage de l'itinéraire et de l'élimination des pics. Cependant, pour améliorer encore la qualité de l'algorithme, un traitement supplémentaire de la séquence de coordonnées est nécessaire aux fins du Bulletin Scientifique et Technique Jeunesse de la FS, ISSN
7 élimination des points redondants qui apparaissent lorsqu'il n'y a pas de mouvement de l'objet observé. Références 1. Yadav J., Giri R., Meena L. Gestion des erreurs dans le traitement des données GPS // Mausam Vol. 62.Non. 1. P Kalman R. E. Une nouvelle approche des problèmes de filtrage linéaire et de prédiction // Transactions de l'ASME Journal of Basic Engineering Vol. 82.Non. Série D. P. P. Welch G., Bishop G. Une introduction au filtre de Kalman : Tech. représentant TR Disponible sur : consulté Vincenty T. Solutions directes et inverses de géodésiques sur l'ellipsoïde avec application d'équations imbriquées // Survey Review apr. Vol. 23. Pas de PP
UDC 519.711.2 Algorithme d'estimation des paramètres d'orientation des engins spatiaux à l'aide d'un filtre de Kalman D. I. Galkin 1 1 MSTU im. N.E. Bauman, Moscou, 155, Russie Une description de la construction du filtre de Kalman est donnée
AGENCE FÉDÉRALE DE RÉGLEMENTATION TECHNIQUE ET DE MÉTROLOGIE NORME NATIONALE DE LA FÉDÉRATION DE RUSSIE GOST R 53608-2009 Système mondial de navigation par satellite MÉTHODES ET TECHNOLOGIES DE MISE EN ŒUVRE
PRÉVISION BAYÉSIENNE DE SÉRIES CHRONOLOGIQUES BASÉES SUR DES MODÈLES SPATIAUX D'ÉTAT V I Université d'État de Biélorussie de Lobach Minsk Biélorussie E-mail : lobach@bsub Une méthode de prévision est envisagée
UDC 681.5(07) IDENTIFICATION D'OBJETS DYNAMIQUES NON LINÉAIRES DANS LE DOMAINE TEMPOREL D.N. Viatchennikov, V.V. Kosobutsky, A.A. Nosenko, N.V. Plotnikova Informations insuffisantes sur les objets lors de leur développement
Ser. 0. 200. Numéro. 4 BULLETIN DES PROCESSUS DE CONTRÔLE DE L'UNIVERSITÉ DE SAINT-PÉTERSBOURG UDC 539.3 V. V. Karelin FONCTIONS DE PÉNALITÉ DANS LE PROBLÈME DE GESTION DU PROCESSUS D'OBSERVATION. Introduction. L'article est consacré au problème
UDC 63.1/.7 ALGORITHMES POUR LE TRAITEMENT DE L'INFORMATION SECONDAIRE DANS UNE STATION RADAR AVEC DIFFÉRENTS TYPES DE MATRICE DE CONVERSATION DYNAMIQUE LORS DE LA DÉTERMINATION DE LA COORDONNÉE DE L'ANGLE D'ÉLÉVATION Yanitskiy A.A. conseiller scientifique
UDC 5979 + 5933 G A Omarova 630090, Russie E-mail : gulzira@ravccru mouvement
Introduction à la robotique Cours 12. Partie 2. Navigation et cartographie. SLAM SLAM Localisation et cartographie simultanées (localisation et cartographie simultanées) La tâche SLAM est l'une des
Notes de cours « Systèmes dynamiques linéaires. Filtre de Kalman." pour le cours spécial « Méthodes structurelles d'analyse d'images et de signaux » 211 Programme pédagogique : quelques propriétés de la distribution normale. Soit x R d distribué
Système de localisation de robot basé sur une caméra hémisphérique Alexander Ovchinnikov, Hoa Phan Department of Radio Electronics Tula State University, Tula, Russie [email protégé], [email protégé]
Actes du MAI numéro 84 UDC 57:5198 wwwmairu/science/trudy/ Détermination des erreurs d'un système de navigation inertielle sans cardan dans les modes de roulage et d'accélération Vavilova NB* Golovan AA Kalchenko AO** Moscou
# 08, août 2016 UDC 004.93 "1 Normalisation des données de caméra 3D en utilisant la méthode des composants principaux pour résoudre le problème de reconnaissance des poses et du comportement des utilisateurs de Smart Home Malykh D.A., étudiant Russie,
Université technique nationale d'Ukraine « Institut polytechnique de Kiev » Département des instruments et des systèmes d'orientation et de navigation Lignes directrices pour travail de laboratoire dans la discipline "Navigation
UDC 629.78.018:621.397.13 PROCÉDÉ DE DISTANCES APPARIÉES DANS LE PROBLÈME DE RÉGLAGE DE VOL DES CAPTEURS ASTRO D'UN SYSTÈME DE VOITURE SPATIALE B.M. Sukhovilov À mesure que l'exactitude et la fiabilité des données astronomiques s'améliorent,
UDC 629.05 Résoudre le problème de navigation à l'aide d'un système de navigation inertielle à sangles et d'un système de signalisation aérienne Mkrtchyan V.I., étudiant, département « Instruments et systèmes d'orientation, de stabilisation et de navigation »
MODÈLE DU SYSTÈME VISUEL DE L'OPÉRATEUR HUMAIN EN RECONNAISSANCE D'IMAGES D'OBJETS Yu.S. Gulina, V.Ya. Université technique d'État Kolyuchkin de Moscou. N.E. Bauman, explique les mathématiques
INGÉNIERIE DES FUSÉES ET INSTRUMENTS SPATIAUX ET SYSTÈMES D'INFORMATION 2015, volume 2, numéro 3, p. 79 83 UDC 681.3.06 ANALYSE DE SYSTÈME, CONTRÔLE DE VÉHICULE SPATIAL, SYSTÈMES DE TRAITEMENT DE L'INFORMATION ET DE TÉLÉMÉTRIE
Systèmes dynamiques linéaires. Filtre de Kalman. Programme éducatif : quelques propriétés de la distribution normale Densité de distribution.4.3.. -4 x b.5 x b =.7 5 p(x a x b =.7) - x p(x a,x b) p(x a) 4 3 - - -3 x.5
UDC 621.396.671 O. S. Litvinov, A. A. Gilyazova ÉVALUATION À L'AIDE DE LA MÉTHODE DE PROPRES DIAGRAMMES DE L'INFLUENCE DES GROUPES D'INTERFÉRENCES SUR LA RÉCEPTION D'UN SIGNAL UTILE PAR UNE ANTENNE ADAPTATIVE LINÉAIRE ÉQUIDISTANTE
UDC 681.5.15.44 PRONOSE DES PROCESSUS PIECELE-STATIONNAIRES E.Yu. Alekseeva Des processus aléatoires discrets contenant des paramètres changeant brusquement à des moments aléatoires sont considérés. Pour
UDC 63966 FILTRAGE OPTIMAL LINÉAIRE POUR LE BRUIT NON BLANC G F Savinov Dans ce travail, un algorithme de filtre optimal est obtenu pour le cas où les influences et les bruits d'entrée sont gaussiens aléatoires
Détermination des mouvements oscillatoires d'éléments satellites non rigides par traitement d'images vidéo D.O. Institut de physique et de technologie Lazarev de Moscou Directeur scientifique, Ph.D. : D.S. Ivanov, Institut
UDC 004 SUR LES MÉTHODES DE SUIVI ET DE SUIVI D'UN OBJET SUR UN FLUX VIDÉO EN APPLICATION À UN SYSTÈME D'ANALYSE VIDÉO POUR LA COLLECTE ET L'ANALYSE DE DONNÉES MARKETING Chezganov D.A., Serikov O.N. État de la Russie du Sud
Journal électronique"Actes de l'AMI". Numéro 66 www.ma.u/scence/tud/ UDC 69.78 Algorithme de navigation modifié pour déterminer la position d'un satellite artificiel à l'aide des signaux GS/GLONASS Kurshin A. V. Moscow Aviation
UDC 621.396.96 Etude de l'algorithme d'établissement et de confirmation de trajectoires selon le critère M de N Chernova T.S., étudiante du département « Systèmes et dispositifs radioélectroniques », Russie, 105005, Moscou, MSTU. N.E.
THÉORIE ET PRATIQUE DES DISPOSITIFS ET SYSTÈMES DE NAVIGATION UDC 531.383 INFLUENCE DE L'ERREUR DE ROTATION DU SUPPORT SUR LA PRÉCISION DE L'ÉTALONNAGE DU BLOC DE GYROSCOPES ET D'ACCÉLÉROMÈTRES Avrutov V. V., Mazepa T. Yu.
Cours 6 Caractéristiques des portefeuilles Dans les cours précédents, le terme « portefeuille » a été utilisé à plusieurs reprises Pour la formulation mathématique du problème du choix d'un portefeuille optimal, une définition stricte de celui-ci est nécessaire.
IDENTIFICATION DE SÉRIES CHRONOLOGIQUES AVEC DES LACUNES BASÉES SUR DES MODÈLES SPATIAUX D'ÉTAT R. I. Merkulov V. I. Lobach Université d'État de Biélorussie Minsk Biélorussie e-mail : [email protégé] [email protégé]
DISPOSITIFS ET SYSTÈMES DE COMMANDE AUTOMATIQUE UDC 51971 V N ARSENYEV, A G KOKHANOVSKY, A S FADEYEV MODÈLE MATHÉMATIQUE DE CONNEXION DES VARIATIONS ISOCHRONIQUES DES VARIABLES D'ÉTAT DU SYSTÈME DE COMMANDE AVEC PARAMÈTRES PERTURBATIONS
Actes de l'AMI. Numéro 89 UDC 629.051 www.mai.ru/science/trudy/ Calibrage d'un système de navigation inertielle à sangle lors d'un demi-tour axe vertical Matasov A.I.*, Tikhomirov V.V.** Moscou
Géométrie analytique Module 1 Algèbre matricielle Algèbre vectorielle Texte 4 ( auto-apprentissage) Résumé Dépendance linéaire des vecteurs Critères de dépendance linéaire de deux, trois et quatre vecteurs
UDC 62.396.26 L.A. Podkolzina, K.. Drugov ALGORITHES DE TRAITEMENT DE L'INFORMATION DANS LES SYSTÈMES DE NAVIGATION D'OBJETS TERRESTRE EN MOUVEMENT POUR LE CANAL DE DÉTERMINATION DES COORDONNEES DE POSITION Pour déterminer les coordonnées et les paramètres
ANALYSE STATISTIQUE DE SÉRIES CHRONOLOGIQUES PARAMÉTRIQUES AVEC LACUNES BASÉES SUR DES MODÈLES SPATIAUX D'ÉTAT S. V. Lobach Université d'État de Biélorussie Minsk, Biélorussie e-mail : [email protégé]
Méthodes mathématiques de traitement des données UDC 6.39 S. Ya Zhuk.. Kozheshkurt.. Université technique nationale Yuzefovich d'Ukraine « KP » ave. Pobeda 37 356 Kiev Ukraine Institut des problèmes d'enregistrement de l'information NAS
Construction de la statique MM des objets technologiques Lors de l'étude de la statique des objets technologiques, on rencontre le plus souvent des objets des types suivants diagrammes fonctionnels(fig : O avec une entrée x et une
Estimation des paramètres d'orientation des engins spatiaux à l'aide du filtre de Kalman Étudiant, Département des Systèmes de Contrôle Automatique : D.I. Galkin Superviseur scientifique : A.A. Karpunine, Ph.D., professeur agrégé
5. Meleshko V.V. Systèmes de navigation inertielle Strapdown : Manuel. allocation / V.V. Meleshko, O.I. Nesterenko. Kirovograd : Service POLYMED, 211. 172 p. Reçu devant l'éditeur 17ème trimestre 212 roku ÓKostyuk
UDC 004.896 Application de transformations géométriques pour l'anamorphisation d'images Kanev A.I., spécialiste Russie, 105005, Moscou, MSTU. N.E. Bauman, Département de traitement de l'information et des systèmes de gestion
4. Méthodes de Monte Carlo 1 4. Méthodes de Monte Carlo Pour simuler divers effets physiques, économiques et autres, des méthodes appelées méthodes de Monte Carlo sont largement utilisées. Ils doivent leur nom
Filtrage passe-bande 1 Filtrage passe-bande Dans les sections précédentes, le filtrage des variations rapides du signal (lissage) et de ses variations lentes (détendance) a été abordé. Parfois, il faut souligner
[REMARQUES] Expliquer les bases du filtre de Kalman à l'aide d'une dérivation simple et intuitive L'article de Ramsey Faraher fournit une dérivation de filtre de Kalman simple et intuitive à des fins d'enseignement.
UDC 004.932 Algorithme de classification d'empreintes digitales Lomov D.S., étudiant Russie, 105005, Moscou, MSTU. N.E. Bauman, Département des logiciels informatiques et des technologies de l'information Superviseur scientifique :
Cours CARACTÉRISTIQUES NUMÉRIQUES D'UN SYSTÈME DE DEUX VARIABLES ALÉATOIRES - VECTEUR ALÉATOIRE DIMENSIONNEL OBJECTIF DE LA CONFÉRENCE : déterminer les caractéristiques numériques d'un système de deux variables aléatoires : covariance des moments initiaux et centraux
La dynamique du taux de natalité dans la République de Tchouvachie Table des matières Introduction 1. La tendance générale du taux de natalité de la population de la République de Tchouvachie 2. La principale tendance du taux de natalité 3. La dynamique du taux de natalité dans les zones urbaines et rurales
EN 1990-5548 Electronique et systèmes de contrôle. 2011. 4(30) 73 UDC656.7.052.002.5:681.32(045) V. M. Sineglazov, docteur en ingénierie. Sciences, Prof., Sh. I. Askerov TRAITEMENT COMPLET OPTIMAL DES DONNÉES EN NAVIGATION
UDC 004.896 Caractéristiques de la mise en œuvre de l'algorithme d'affichage des résultats anamorphiques Kanev A.I., spécialiste Russie, 105005, Moscou, MSTU. N.E. Bauman, Département des systèmes de traitement de l'information et
177 UDC 658.310.8 : 519.876.2 UTILISATION DE LA PRÉCISION DE L'ESTIMATION DANS LA RÉSERVATION DES CAPTEURS L.I. Luzina L'article discute d'une approche possible pour obtenir un nouveau schéma de redondance des capteurs. Traditionnel
COLLECTION D'OEUVRES SCIENTIFIQUES DU NSTU. 28.4(54). 37 44 UDC 59.24 À PROPOS D'UN COMPLEXE DE PROGRAMMES POUR RÉSOUDRE LE PROBLÈME D'IDENTIFICATION D'OBJETS STATIONNAIRES DISCRETS DYNAMIQUES LINÉAIRES G.V. TROSHINA Un ensemble de programmes a été envisagé
UDC 625.1:519.222:528.4 SI. Dolganyuk S.I. Dolganyuk, 2010 AUGMENTER LA PRÉCISION D'UNE SOLUTION DE NAVIGATION LORS DU POSITIONNEMENT DE LOCOMOTIVES DE MANŒUVRE GRÂCE À L'UTILISATION DE MODÈLES NUMÉRIQUES DE DÉVELOPPEMENT DE VOIE
UDC 531.1 ADAPTATION DU FILTRE KALMAN POUR UTILISATION AVEC LES SYSTÈMES DE NAVIGATION LOCAUX ET GLOBAUX A.N. Zabegaev ( [email protégé]) V.E. Pavlovski ( [email protégé]) Institut de mathématiques appliquées du nom.
AUTOMATISATION ET CONTRÔLE UDC 68.58.3 A. G. Shpektorov, V. T. Fam Université électrotechnique d'État de Saint-Pétersbourg « LETI » du nom. V. I. Ulyanova (Lenina) Analyse de l'utilisation de la micromécanique
BASES DE L'ANALYSE DE RÉGRESSION CONCEPT DE CORRÉLATION ET ANALYSE DE RÉGRESSION Pour résoudre les problèmes d'analyse et de prévision économiques, des données statistiques, de reporting ou observées sont souvent utilisées
Cours 4. Résolution de systèmes d'équations linéaires par la méthode des itérations simples. Si le système a une grande dimension (6 équations) ou si la matrice du système est clairsemée, les méthodes itératives indirectes sont plus efficaces pour résoudre
58ème Conférence scientifique MIPT Section de dynamique et de contrôle de mouvement des engins spatiaux Système permettant de déterminer le mouvement de modèles de systèmes de contrôle sur une table aérodynamique à l'aide d'une caméra vidéo
Cours 3 5. MÉTHODES D'APPROXIMATION DES FONCTIONS ÉNONCÉ DU PROBLÈME Nous considérons les fonctions tabulaires de grille [ a b] y 5. définies aux nœuds de la grille Ω. Chaque grille est caractérisée par des pas h inégaux ou h
1. Méthodes numériques de résolution d'équations 1. Systèmes d'équations linéaires. 1.1. Méthodes directes. 1.2. Méthodes itératives. 2. Équations non linéaires. 2.1. Équations à une inconnue. 2.2. Systèmes d'équations. 1.
UDC 621.396 RECHERCHE D'ALGORITHMES POUR LE TRAITEMENT DE L'INFORMATION SECONDAIRE DU SYSTÈME RADAR MULTI-POSITIONS POUR CANAL D'ANGLE D'ÉLISATION Borisov A.N., Glinchenko V.A., Nazarov A.A., Islamov R.V., Suchkov P.V. Scientifique
Sujet Méthodes numériques d'algèbre linéaire - - Sujet Méthodes numériques d'algèbre linéaire Classification Il existe quatre sections principales de l'algèbre linéaire : Résolution de systèmes d'équations algébriques linéaires (SLAE)
UDC 004.352.242 Restauration d'images floues par résolution d'une équation intégrale de type convolution Ivannikova I.A., étudiante Russie, 105005, Moscou, MSTU. N.E. Bauman, Département d'automatisation
LEVÉES AÉROGRAVIMÉTRIQUES AVEC MODE DE FONCTIONNEMENT GPS STANDARD Mogilevsky V.E. Entreprise d'État de recherche et de production JSC Aerogeofizika L'élément le plus important déterminant le succès de la recherche géophysique aéroportée est une navigation de haute qualité
ANALYSE DES SIGNAUX ACOUSTIQUES BASÉE SUR LA MÉTHODE DE FILTRATION KALMAN I.P. Gurov, P.G. Zhiganov, A.M. Ozersky Les caractéristiques du traitement dynamique des signaux stochastiques utilisant des signaux discrets
UDC AA Minko IDENTIFICATION D'UN OBJET LINÉAIRE PAR RÉPONSE À UN SIGNAL HARMONIQUE Un algorithme d'identification généralisé est proposé basé sur les transformations gaussiennes intégrales à deux paramètres d'un stationnaire linéaire
CONFÉRENCE. Estimation de l'amplitude d'un signal complexe. Estimation du temps de retard du signal. Estimation fréquentielle d'un signal à phase aléatoire. Estimation conjointe du temps de retard et de la fréquence d'un signal à phase aléatoire.
Computational Technologies Volume 18, 1, 2013 Identification des paramètres du processus de diffusion anormale sur la base d'équations aux différences A. S. Ovsienko Université technique d'État de Samara, Russie e-mail :
1 PRÉVISION DES CONDITIONS DU MARCHÉ DES ENTREPRISES PÉTROCHIMIQUES Kordunov D.Yu., Bityutsky S.Ya. Introduction. Dans les conditions économiques modernes, caractérisées par le développement rapide de l'intégration mondiale
Problème de localisation et de cartographie simultanées (SLAM) Roboschool-2014 Andrey Antonov robotosha.ru 10 octobre 2014 Plan 1 Bases du SLAM 2 RGB-D SLAM 3 Robot Andrey Antonov (robotosha.ru) Problème SLAM
UDC 004.021 T. N. Romanova, A. V. Sidorin, V. N. Solyakov, K. V. Kozlov SYNTHÈSE D'IMAGE MONOCHROME À PARTIR D'UNE CONSTRUCTION DE PALETTE MULTI-GAMME UTILISANT LA RÉSOLUTION DE L'ÉQUATION DE POISSON
Université technique nationale d'Ukraine "Institut polytechnique de Kiev" Département des instruments et des systèmes d'orientation et de navigation Lignes directrices pour les travaux de laboratoire dans la discipline "Navigation
Traitement du signal numérique /9 UDC 69.78 MÉTHODE ANALYTIQUE POUR LE CALCUL DES ERREURS DANS LA DÉTERMINATION DE L'ORIENTATION ANGULAIRE PAR LES SIGNAUX DES SYSTÈMES DE RADIONAVIGATION PAR SATELLITE Aleshechkin A.M. Mode de détection
CARACTÉRISTIQUES DE FORMATION D'UN MODÈLE INFORMATIQUE D'UN SYSTÈME OPTIQUE-ÉLECTRONIQUE DYNAMIQUE Pozdnyakova N.S., Torshina I.P. Université d'État de géodésie et de cartographie de Moscou Faculté d'information optique
Actes de l'ISA RAS 009. T. 46 III. PROBLEMES APPLIQUÉS AU CALCUL DISTRIBUÉ États stationnaires dans le modèle non linéaire de transfert de charge dans l'ADN * États stationnaires dans le modèle non linéaire de transfert de charge dans
Ce filtre est utilisé dans divers domaines - de l'ingénierie radio à l'économie. Ici, nous discuterons de l'idée principale, de la signification et de l'essence de ce filtre. Il sera présenté dans le langage le plus simple possible.
Supposons que nous devions mesurer certaines quantités d'un certain objet. En ingénierie radio, il s'agit le plus souvent de mesurer des tensions à la sortie d'un certain appareil (capteur, antenne, etc.). Dans l'exemple avec un électrocardiographe (voir), il s'agit de mesures de biopotentiels sur le corps humain. En économie, par exemple, la valeur mesurée peut être le taux de change. Chaque jour, le taux de change est différent, c'est-à-dire chaque jour « ses mesures » nous donnent une valeur différente. Et si l'on généralise, on peut dire que l'essentiel de l'activité humaine (sinon la totalité) se résume à des mesures constantes et à des comparaisons de certaines quantités (voir livre).
Supposons donc que nous mesurons constamment quelque chose. Supposons également que nos mesures comportent toujours une certaine erreur - cela est compréhensible, car il n'existe pas d'instruments de mesure idéaux et chacun produit des résultats avec une erreur. Dans le cas le plus simple, ce qui est décrit peut se réduire à l'expression suivante : z=x+y, où x est la vraie valeur que l'on veut mesurer et qui serait mesurée si l'on avait un appareil de mesure idéal, y est la valeur de mesure erreur introduite instrument de mesure, et z est la valeur que nous avons mesurée. Ainsi, la tâche du filtre de Kalman est de deviner (déterminer) à partir du z que nous avons mesuré, quelle était la vraie valeur de x lorsque nous avons reçu notre z (qui contient la vraie valeur et l'erreur de mesure). Il est nécessaire de filtrer (éliminer) la vraie valeur de x de z – pour supprimer le bruit de distorsion y de z. Autrement dit, n'ayant qu'une somme en main, nous devons deviner quels termes ont donné cette somme.
À la lumière de ce qui précède, formulons maintenant le tout comme suit. Qu'il n'y ait que deux nombres aléatoires. On nous donne uniquement leur somme et nous devons utiliser cette somme pour déterminer quels sont les termes. Par exemple, on nous a donné le nombre 12 et ils disent : 12 est la somme des nombres x et y, la question est de savoir à quoi x et y sont égaux. Pour répondre à cette question, nous créons une équation : x+y=12. Nous avons reçu une équation à deux inconnues, donc à proprement parler, il n'est pas possible de trouver deux nombres donnant cette somme. Mais nous pouvons encore dire quelque chose sur ces chiffres. On peut dire qu'il s'agissait soit des nombres 1 et 11, soit de 2 et 10, soit de 3 et 9, soit de 4 et 8, etc., soit de 13 et -1, soit de 14 et -2, soit de 15 et - 3, etc Autrement dit, nous pouvons utiliser la somme (dans notre exemple 12) pour déterminer les nombreuses options possibles qui totalisent exactement 12. L'une de ces options est la paire que nous recherchons, qui donne en fait 12 en ce moment. notant que toutes les variantes de paires de nombres donnant un total de 12 forment une ligne droite, représentée sur la figure 1, qui est donnée par l'équation x+y=12 (y=-x+12).
Fig. 1
Ainsi, la paire que nous recherchons se situe quelque part sur cette ligne droite. Je le répète, il est impossible de choisir parmi toutes ces options le couple qui a réellement existé - qui a donné le numéro 12, sans connaître d'indices supplémentaires. Cependant, dans la situation pour laquelle le filtre de Kalman a été inventé, de tels indices existent. Il y a quelque chose de connu à l’avance sur les nombres aléatoires. En particulier, l'histogramme dit de distribution pour chaque paire de nombres y est connu. Il est généralement obtenu après une observation suffisamment longue de l'occurrence de ces mêmes nombres aléatoires. Autrement dit, on sait par expérience que dans 5% des cas apparaît généralement le couple x=1, y=8 (on note ce couple comme suit : (1,8)), dans 2% des cas le couple x=2, y=3 ( 2,3), dans 1% des cas une paire (3,1), dans 0,024% des cas une paire (11,1), etc. Je le répète, cet histogramme est donné pour tous les couples nombres, y compris ceux qui totalisent 12. Ainsi, pour chaque paire qui totalise 12, on peut dire que, par exemple, la paire (1, 11) apparaît 0,8% du temps, la paire (2, 10) – dans 1% des cas, paire (3, 9) – dans 1,5% des cas, etc. Ainsi, on peut utiliser l'histogramme pour déterminer dans quel pourcentage de cas la somme des termes d'une paire est égale à 12. Soit par exemple dans 30% des cas la somme donne 12. Et dans les 70% restants, le les paires restantes tombent - ce sont (1,8), (2, 3), (3,1), etc. – ceux qui totalisent des nombres autres que 12. De plus, que par exemple le couple (7,5) apparaisse dans 27% des cas, tandis que tous les autres couples qui totalisent 12 apparaissent dans 0,024%+0,8% +1 %+1,5%+…=3% des cas. Ainsi, à partir de l’histogramme, nous avons découvert que les nombres dont la somme donne 12 apparaissent dans 30 % des cas. De plus, nous savons que si un 12 est obtenu, la raison en est le plus souvent (27% sur 30%) la paire (7,5). Autrement dit, si déjà Si on obtient un 12, on peut dire que dans 90% des cas (27% de 30% - ou, ce qui revient au même, 27 fois sur 30) la raison pour laquelle on obtient un 12 est la paire (7,5) . Sachant que le plus souvent la raison pour laquelle on reçoit une somme égale à 12 est la paire (7,5), il est logique de supposer que, très probablement, elle a baissé maintenant. Bien sûr, ce n'est toujours pas un fait qu'en fait maintenant le nombre 12 est formé par cette paire particulière, cependant, la prochaine fois, si nous rencontrons 12, et nous supposons à nouveau la paire (7,5), alors dans environ 90% des cas sur 100% nous aurons raison. Mais si nous devinons la paire (2, 10), nous n'aurons raison que dans 1% de 30% des cas, ce qui équivaut à 3,33% de réponses correctes contre 90% en devinant la paire (7,5). C'est tout - c'est le but de l'algorithme du filtre de Kalman. C'est-à-dire que le filtre de Kalman ne garantit pas qu'il ne fera pas d'erreur en déterminant la somme par la somme, mais il garantit qu'il se trompera un minimum de fois (la probabilité d'une erreur sera minime), puisque il utilise des statistiques - un histogramme de l'occurrence de paires de nombres. Il convient également de souligner que l'algorithme de filtrage de Kalman utilise souvent ce que l'on appelle la densité de distribution de probabilité (PDD). Cependant, il faut comprendre que la signification y est la même que celle d’un histogramme. De plus, un histogramme est une fonction construite à partir de PDF et constitue son approximation (voir, par exemple,).
En principe, nous pouvons représenter cet histogramme en fonction de deux variables, c'est-à-dire sous la forme d'une certaine surface au-dessus du plan xy. Là où la surface est plus élevée, la probabilité d’obtenir la paire correspondante est plus élevée. La figure 2 montre une telle surface.

Figure 2
Comme vous pouvez le voir au-dessus de la droite x+y=12 (qui a des variantes de paires de donnant au total 12), les points de surface sont situés à différentes hauteurs et la hauteur la plus élevée est pour la variante avec les coordonnées (7,5). Et lorsque l'on rencontre une somme égale à 12, dans 90% des cas la raison de l'apparition de cette somme est précisément la paire (7,5). Ceux. C'est cette paire, dont la somme fait 12, qui a la probabilité d'apparition la plus élevée, à condition que la somme soit de 12.
Ainsi, l’idée derrière le filtre de Kalman est décrite ici. C'est sur cette base que sont construites toutes sortes de modifications - récurrentes en une étape, en plusieurs étapes, etc. Pour une étude plus approfondie du filtre de Kalman, je recommande le livre : Van Trees G. Theory of détection, estimation and modulation.
p.s. Pour ceux qui sont intéressés par des explications des concepts mathématiques, comme on dit « sur les doigts », nous pouvons recommander ce livre et en particulier les chapitres de sa section « Mathématiques » (vous pouvez acheter le livre lui-même ou des chapitres individuels de celui-ci. ).
Les filtres Wiener sont les mieux adaptés au traitement de processus ou de sections de processus dans leur ensemble (traitement par blocs). Le traitement séquentiel nécessite une évaluation actuelle du signal à chaque cycle d'horloge, en tenant compte des informations reçues à l'entrée du filtre pendant le processus d'observation.
Avec le filtrage Wiener, chaque nouvel échantillon de signal nécessiterait un recalcul de tous les coefficients de poids du filtre. Actuellement, les filtres adaptatifs dans lesquels le signal entrant nouvelle information utilisé pour l'ajustement continu d'une évaluation de signal préalablement effectuée (poursuite de cible dans le radar, systèmes de contrôle automatique en contrôle, etc.). Les filtres récursifs adaptatifs connus sous le nom de filtre de Kalman sont particulièrement intéressants.
Ces filtres sont largement utilisés dans les boucles de contrôle des systèmes de régulation et de contrôle automatiques. C’est de là qu’ils viennent, comme en témoigne la terminologie spécifique utilisée pour décrire leur travail comme espace d’état.
L’un des principaux problèmes à résoudre dans la pratique de l’informatique neuronale est d’obtenir des algorithmes rapides et fiables pour entraîner les réseaux neuronaux. À cet égard, il peut être utile d’utiliser un algorithme d’apprentissage de filtres linéaires dans la boucle de rétroaction. Puisque les algorithmes d’apprentissage sont de nature itérative, un tel filtre doit être un estimateur récursif séquentiel.
Problème d'estimation des paramètres
L'un des problèmes de la théorie des solutions statistiques qui revêt une grande importance pratique est le problème de l'estimation des vecteurs d'état et des paramètres des systèmes, qui est formulé comme suit. Supposons qu'il soit nécessaire d'estimer la valeur d'un paramètre vectoriel $X$ qui n'est pas directement mesurable. Au lieu de cela, un autre paramètre $Z$ est mesuré, en fonction de $X$. La tâche d'estimation consiste à répondre à la question : que peut-on dire de $X$, connaissant $Z$. En général, la procédure d'estimation optimale du vecteur $X$ dépend du critère adopté pour la qualité de l'estimation.
Par exemple, l’approche bayésienne du problème de l’estimation des paramètres nécessite des informations a priori complètes sur les propriétés probabilistes du paramètre estimé, ce qui est souvent impossible. Dans ces cas-là, ils recourent à la méthode des moindres carrés (LSM), qui nécessite nettement moins d’informations a priori.
Considérons l'application des moindres carrés pour le cas où le vecteur d'observation $Z$ est lié au vecteur d'estimation de paramètre $X$ par un modèle linéaire, et l'observation contient du bruit $V$, non corrélé au paramètre estimé :
$Z = HX + V$, (1)
où $H$ est la matrice de transformation décrivant la relation entre les quantités observées et les paramètres estimés.
L'estimation $X$ qui minimise l'erreur quadratique s'écrit comme suit :
$X_(ots)=(H^TR_V^(-1)H)^(-1)H^TR_V^(-1)Z$, (2)
Soit le bruit $V$ non corrélé, auquel cas la matrice $R_V$ est simplement la matrice identité, et l'équation d'estimation devient plus simple :
$X_(ots)=(H^TH)^(-1)H^TZ$, (3)
Écrire sous forme matricielle permet d'économiser beaucoup de papier, mais peut s'avérer inhabituel pour certains. L’exemple suivant, tiré de la monographie de Yu. M. Korshunov « Fondements mathématiques de la cybernétique », illustre tout cela.
On a le circuit électrique suivant :
Les grandeurs observées dans ce cas sont les lectures de l'instrument $A_1 = 1 A, A_2 = 2 A, V = 20 B$.
De plus, la résistance connue est $R = 5$ Ohm. Il est nécessaire d'estimer de la meilleure façon possible, du point de vue du critère d'erreur quadratique moyenne minimale, les valeurs des courants $I_1$ et $I_2$. La chose la plus importante ici est qu'il existe une certaine relation entre les quantités observées (lecture des instruments) et les paramètres estimés. Et cette information vient de l’extérieur.
Dans ce cas, ce sont les lois de Kirchhoff, dans le cas du filtrage (qui sera discuté plus tard) - un modèle autorégressif d'une série temporelle, qui suppose la dépendance de la valeur actuelle par rapport aux précédentes.
Ainsi, la connaissance des lois de Kirchhoff, qui n'a rien à voir avec la théorie des solutions statistiques, permet d'établir un lien entre les valeurs observées et les paramètres estimés (ceux qui ont étudié l'électrotechnique peuvent vérifier, le reste aura pour les croire sur parole) :
$$z_1 = A_1 = I_1 + \xi_1 = 1$$
$$z_2 = A_2 = I_1 + I_2 + \xi_2 = 2$$
$$z_2 = V/R = I_1 + 2 * I_2 + \xi_3 = 4$$
C'est sous forme vectorielle :
$$\begin(vmatrix) z_1\\ z_2\\ z_3 \end(vmatrix) = \begin(vmatrix) 1 & 0\\ 1 & 1\\ 1 & 2 \end(vmatrix) \begin(vmatrix) I_1\ \ I_2 \end(vmatrix) + \begin(vmatrix) \xi_1\\ \xi_2\\ \xi_3 \end(vmatrix)$$
Ou $Z = HX + V$, où
$$Z= \begin(vmatrix) z_1\\ z_2\\ z_3 \end(vmatrix) = \begin(vmatrix) 1\\ 2\\ 4 \end(vmatrix) ; H= \begin(vmatrix) 1 & 0\\ 1 & 1\\ 1 & 2 \end(vmatrix) ; X= \begin(vmatrix) I_1\\ I_2 \end(vmatrix) ; V= \begin(vmatrix) \xi_1\\ \xi_2\\ \xi_3 \end(vmatrix)$$
Considérant les valeurs de bruit décorrélées entre elles, on trouvera l'estimation de I 1 et I 2 par la méthode des moindres carrés conformément à la formule 3 :
$H^TH= \begin(vmatrix) 1 & 1& 1\\ 0 & 1& 2 \end(vmatrix) \begin(vmatrix) 1 & 0\\ 1 & 1\\ 1 & 2 \end(vmatrix) = \ commencer(vmatrix) 3 & 3\\ 3 & 5 \end(vmatrix) ; (H^TH)^(-1)= \frac(1)(6) \begin(vmatrix) 5 & -3\\ -3 & 3 \end(vmatrix) $;
$H^TZ= \begin(vmatrix) 1 & 1& 1\\ 0 & 1& 2 \end(vmatrix) \begin(vmatrix) 1 \\ 2\\ 4 \end(vmatrix) = \begin(vmatrix) 7\ \ 10 \end(vmatrix) ; X(ots)= \frac(1)(6) \begin(vmatrix) 5 & -3\\ -3 & 3 \end(vmatrix) \begin(vmatrix) 7\\ 10 \end(vmatrix) = \frac (1)(6) \begin(vmatrix) 5\\ 9 \end(vmatrix)$;
Donc $I_1 = 5/6 = 0,833 A$ ; $I_2 = 9/6 = 1,5 AU$.
Tâche de filtrage
Contrairement au problème de l'estimation de paramètres ayant des valeurs fixes, le problème de filtrage nécessite des processus d'estimation, c'est-à-dire la recherche d'estimations actuelles d'un signal variable dans le temps qui est déformé par le bruit et, par conséquent, inaccessible à une mesure directe. En général, le type d'algorithmes de filtrage dépend des propriétés statistiques du signal et du bruit.
Nous supposerons que le signal utile varie lentement en fonction du temps et que l’interférence est un bruit non corrélé. Nous utiliserons la méthode des moindres carrés, là encore en raison du manque d'informations a priori sur les caractéristiques probabilistes du signal et du bruit.
Tout d'abord, nous obtenons une estimation de la valeur actuelle $x_n$ sur la base des dernières valeurs $k$ disponibles de la série chronologique $z_n, z_(n-1),z_(n-2)\dots z_(n- (k-1))$. Le modèle d'observation est le même que dans le problème d'estimation des paramètres :
Il est clair que $Z$ est un vecteur colonne constitué des valeurs observées de la série temporelle $z_n, z_(n-1),z_(n-2)\dots z_(n-(k-1))$ , $V $ est le vecteur de colonne de bruit $\xi _n, \xi _(n-1),\xi_(n-2)\dots \xi _(n-(k-1))$, déformant le vrai signal . Que signifient les symboles $H$ et $X$ ? De quoi, par exemple, pouvons-nous parler du vecteur colonne $X$ s'il suffit d'estimer la valeur actuelle de la série chronologique ? Et ce que l'on entend par matrice de transformation $H$ n'est généralement pas clair.
Toutes ces questions ne peuvent trouver de réponse que si le concept de modèle de génération de signaux est pris en compte. Autrement dit, un modèle du signal original est nécessaire. Ceci est compréhensible ; en l’absence d’informations a priori sur les caractéristiques probabilistes du signal et des interférences, on ne peut que formuler des hypothèses. Vous pouvez appeler cela la divination sur le marc de café, mais les experts préfèrent une terminologie différente. Sur leur sèche-cheveux, cela s'appelle un modèle paramétrique.
Dans ce cas, les paramètres de ce modèle particulier sont estimés. Lorsque vous choisissez un modèle de génération de signal approprié, n'oubliez pas que toute fonction analytique peut être étendue en une série de Taylor. Une propriété frappante de la série de Taylor est que la forme d'une fonction à toute distance finie $t$ d'un certain point $x=a$ est uniquement déterminée par le comportement de la fonction dans un voisinage infinitésimal du point $x=a $ (nous parlons de ses dérivés du premier ordre et des ordres supérieurs).
Ainsi, l’existence de séries de Taylor signifie que la fonction analytique possède une structure interne à couplage très fort. Si, par exemple, nous nous limitons à trois termes de la série de Taylor, alors le modèle de génération de signal ressemblera à ceci :
$x_(ni) = F_(-i)x_n$, (4)
$$X_n= \begin(vmatrix) x_n\\ x"_n\\ x""_n \end(vmatrix) ; F_(-i)= \begin(vmatrix) 1 & -i & i^2/2\\ 0 & 1 & -i\\ 0 & 0 & 1 \end(vmatrix) $$
C'est-à-dire que la formule 4, pour un ordre donné du polynôme (dans l'exemple il est égal à 2), établit une connexion entre la $n$-ème valeur du signal dans la séquence temporelle et le $(n-i)$- ème. Ainsi, le vecteur d'état estimé comprend dans ce cas, en plus de la valeur estimée elle-même, les dérivées première et seconde du signal.
Dans la théorie du contrôle automatique, un tel filtre serait appelé filtre à astatisme du 2ème ordre. La matrice de transformation $H$ pour ce cas (estimée à l'aide des échantillons actuels et $k-1$ précédents) ressemble à ceci :
$$H= \begin(vmatrix) 1 & -k & k^2/2\\ - & - & -\\ 1 & -2 & 2\\ 1 & -1 & 0.5\\ 1 & 0 & 0 \ fin (vmatrice)$$
Tous ces nombres sont obtenus à partir de la série de Taylor en supposant que l'intervalle de temps entre les valeurs observées adjacentes est constant et égal à 1.
Ainsi, sous les hypothèses que nous avons faites, le problème du filtrage a été réduit au problème de l’estimation des paramètres ; dans ce cas, les paramètres du modèle de génération de signal que nous avons adopté sont estimés. Et l'évaluation des valeurs du vecteur d'état $X$ s'effectue selon la même formule 3 :
$$X_(ots)=(H^TH)^(-1)H^TZ$$
Essentiellement, nous avons mis en œuvre un processus d'estimation paramétrique basé sur un modèle autorégressif du processus de génération de signal.
La formule 3 peut être facilement implémentée dans un logiciel ; pour ce faire, vous devez remplir la matrice $H$ et le vecteur colonne d'observation $Z$. De tels filtres sont appelés filtres à mémoire limitée, puisqu'ils utilisent les dernières $k$ observations pour obtenir l'estimation actuelle $X_(noc)$. À chaque nouvelle étape d’observation, une nouvelle est ajoutée à l’ensemble actuel d’observations et l’ancienne est supprimée. Ce processus d'obtention d'estimations est appelé fenêtre coulissante.
Filtres avec une mémoire croissante
Les filtres à mémoire finie présentent le principal inconvénient qu'après chaque nouvelle observation, il est nécessaire de recalculer toutes les données stockées en mémoire. De plus, le calcul des estimations ne peut commencer qu’après avoir accumulé les résultats des premières observations $k$. Autrement dit, ces filtres ont une longue durée de processus transitoire.
Pour remédier à cet inconvénient, il faut passer d'un filtre à mémoire permanente à un filtre à mémoire croissante. Dans un tel filtre, le nombre de valeurs observées par lesquelles l'évaluation est effectuée doit correspondre au nombre n de l'observation actuelle. Cela permet d'obtenir des estimations à partir d'un nombre d'observations égal au nombre de composantes du vecteur estimé $X$. Et cela est déterminé par l'ordre du modèle adopté, c'est-à-dire le nombre de termes de la série de Taylor utilisés dans le modèle.
Dans ce cas, à mesure que n augmente, les propriétés de lissage du filtre s'améliorent, c'est-à-dire que la précision des estimations augmente. Cependant, la mise en œuvre directe de cette approche est associée à une augmentation des coûts de calcul. Par conséquent, des filtres avec une mémoire croissante sont implémentés comme récurrent.
Le fait est qu'au temps n, nous avons déjà une estimation $X_((n-1)ots)$, qui contient des informations sur toutes les observations précédentes $z_n, z_(n-1), z_(n-2) \dots z_ (n-(k-1))$. L'estimation $X_(nots)$ est obtenue à partir de l'observation suivante $z_n$ en utilisant les informations stockées dans l'estimation $X_((n-1))(\mbox (ots))$. Cette procédure est appelée filtrage récurrent et comprend les éléments suivants :
- d'après l'estimation $X_((n-1))(\mbox (ots))$, prédire l'estimation $X_n$ en utilisant la formule 4 pour $i = 1$ : $X_(\mbox (notspriori)) = F_1X_( (n-1 )ots)$. Il s'agit d'une estimation a priori ;
- selon les résultats de l'observation actuelle $z_n$, cette estimation a priori se transforme en une estimation vraie, c'est-à-dire a posteriori ;
- cette procédure est répétée à chaque étape, à partir de $r+1$, où $r$ est l'ordre du filtre.
La formule finale de filtrage récurrent ressemble à ceci :
$X_((n-1)oc) = X_(\mbox (nocapriori)) + (H^T_nH_n)^(-1)h^T_0(z_n - h_0 X_(\mbox (nocapriori)))$, (6 )
où pour notre filtre de deuxième ordre :
Un filtre à mémoire croissante fonctionnant conformément à la formule 6 est un cas particulier de l'algorithme de filtrage connu sous le nom de filtre de Kalman.
Lors de la mise en pratique de cette formule, il faut se rappeler que l'estimation a priori qui y est incluse est déterminée par la formule 4, et la valeur $h_0 X_(\mbox (nocapriori))$ représente la première composante du vecteur $X_( \mbox (nocapriori))$.
Le filtre de mémoire croissant a une fonctionnalité importante. Si vous regardez la formule 6, l'estimation finale est la somme du vecteur d'estimation prédit et du terme de correction. Cette correction est importante pour les petits $n$ et diminue à mesure que $n$ augmente, tendant vers zéro à $n \rightarrow \infty$. Autrement dit, à mesure que n augmente, les propriétés de lissage du filtre augmentent et le modèle qui y est intégré commence à dominer. Mais le signal réel ne peut correspondre au modèle que dans une certaine mesure. zones séparées, donc la précision des prévisions se détériore.
Pour lutter contre cela, à partir d'un certain $n$, il est interdit de diminuer davantage le terme de correction. Cela équivaut à changer la bande du filtre, c'est-à-dire que pour un petit n, le filtre a une bande passante plus large (moins inertielle), pour un grand n, il devient plus inertiel.
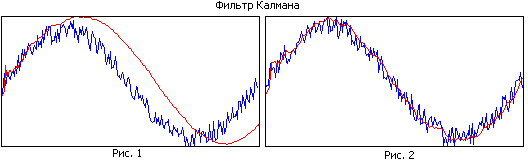
Comparez la figure 1 et la figure 2. Dans la première figure, le filtre a une grande mémoire et il lisse bien, mais en raison de la bande étroite, la trajectoire estimée est en retard sur la trajectoire réelle. Dans la deuxième figure, la mémoire du filtre est plus petite, elle lisse moins bien, mais suit mieux la trajectoire réelle.
Littérature
- Yu.M. Korshunov "Fondements mathématiques de la cybernétique"
- A.V. Balakrishnan "Théorie de la filtration de Kalman"
- V.N.Fomin "Estimation récurrente et filtrage adaptatif"
- C.F.N.Cowan, P.M. Accorder "Filtres adaptatifs"
Une étude de l'utilisation du filtre de Kalman dans les développements modernes de systèmes intégrés systèmes de navigation. Un exemple de construction d'un modèle mathématique utilisant un filtre de Kalman étendu pour améliorer la précision de la détermination des coordonnées de véhicules aériens sans pilote est donné et analysé. Un filtre partiel est envisagé. Fait brève revue travaux scientifiques, en utilisant ce filtre pour améliorer la fiabilité et la tolérance aux pannes des systèmes de navigation. Cet article nous permet de conclure que l'utilisation du filtre de Kalman dans les systèmes de localisation de drones est pratiquée dans de nombreux développements modernes. Il existe un grand nombre de variantes et d'aspects de cette utilisation, qui fournissent également des résultats tangibles en termes d'augmentation de la précision, notamment en cas de panne des systèmes de navigation par satellite standards. C'est le principal facteur d'influence de cette technologie sur divers domaines scientifiques liés au développement de systèmes de navigation précis et insensibles aux pannes pour divers avions.
Filtre de Kalman
la navigation
véhicule aérien sans pilote (UAV)
1. Makarenko G.K., Aleshechkin A.M. Etude d'un algorithme de filtrage lors de la détermination des coordonnées d'un objet à l'aide des signaux des systèmes de radionavigation par satellite // TUSUR Reports. – 2012. – N° 2 (26). – p. 15-18.
2. Bar-Shalom Y., Li X. R., Kirubarajan T. Estimation avec applications
au suivi et à la navigation // Théorie des algorithmes et des logiciels. – 2001. – Vol. 3. – P. 10-20.
3. Bassem I.S. Navigation basée sur la vision (VBN) des véhicules aériens sans pilote (UAV) // UNIVERSITÉ DE CALGARY. – 2012. – Vol. 1. – P. 100-127.
4. Conte G., Doherty P. Un système de navigation intégré pour drones basé sur la correspondance d'images aériennes // Conférence aérospatiale. – 2008. –Vol. 1. – P. 3142-3151.
5. Guoqiang M., Drake S., Anderson B. Conception d'un filtre de Kalman étendu pour la localisation de drones // Dans Information, Décision et Contrôle. – 2007. – Vol. 7. – P. 224-229.
6. Optimisation de la trajectoire Ponda S.S pour la localisation de cibles à l'aide de petits véhicules aériens sans pilote // Massachusetts Institute of Technology. – 2008. – Vol. 1. – P. 64-70.
7. Wang J., Garrat M., Lambert A. Intégration de capteurs gps/ins/vision pour naviguer dans les véhicules aériens sans pilote // IAPRS&SIS. – 2008. – Vol. 37. – P. 963-969.
L'une des tâches urgentes de la navigation moderne des véhicules aériens sans pilote (UAV) est d'augmenter la précision de la détermination des coordonnées. Ce problème est résolu en utilisant diverses options intégration des systèmes de navigation. Un des options modernes L'intégration est une combinaison de navigation GPS/Glonass avec un filtre de Kalman étendu, qui évalue de manière récursive la précision à l'aide de mesures incomplètes et bruyantes. DANS ce moment Diverses variantes du filtre de Kalman étendu existent et sont en cours de développement, comprenant un nombre varié de variables d'état. Dans ce travail, nous montrerons à quel point son utilisation peut être efficace dans les développements modernes. Considérons l'une des représentations caractéristiques d'un tel filtre.
Construire un modèle mathématique
Dans cet exemple, nous ne parlerons que du mouvement du drone dans le plan horizontal, sinon nous considérerons le problème dit de localisation 2D. Dans notre cas, cela se justifie par le fait que dans de nombreuses situations rencontrées en pratique, le drone peut rester approximativement à la même altitude. Cette hypothèse est largement utilisée pour simplifier les simulations dynamiques des avions. Le modèle dynamique du drone est spécifié par le système d’équations suivant :
où () sont les coordonnées du drone dans le plan horizontal en fonction du temps, la direction du drone, la vitesse angulaire du drone et la vitesse sol du drone, fonctionnent et seront considérées comme constantes. Ils sont mutuellement indépendants, avec des covariances connues ![]() et , égaux à et respectivement, et sont utilisés pour modéliser les changements dans l'accélération du drone provoqués par le vent, les manœuvres du pilote, etc. Les valeurs et sont dérivées de la vitesse angulaire maximale du drone et des valeurs expérimentales des modifications de la vitesse linéaire du drone, - symbole de Kronecker.
et , égaux à et respectivement, et sont utilisés pour modéliser les changements dans l'accélération du drone provoqués par le vent, les manœuvres du pilote, etc. Les valeurs et sont dérivées de la vitesse angulaire maximale du drone et des valeurs expérimentales des modifications de la vitesse linéaire du drone, - symbole de Kronecker.
Ce système d'équations sera approximatif en raison de la non-linéarité du modèle et de la présence de bruit. La méthode d’approximation la plus simple dans ce cas est la méthode d’approximation d’Euler. Un modèle discret du système de propulsion dynamique du drone est présenté ci-dessous.
![]()
un vecteur d'état de filtre de Kalman discret qui permet de se rapprocher de la valeur d'un vecteur d'état continu. ∆ - intervalle de temps entre k et k+1 mesures. () et () sont des séquences de valeurs de bruit blanc gaussien de moyenne nulle. Matrice de covariance pour la première séquence :
De même, pour la deuxième séquence :
Après avoir effectué les substitutions appropriées dans les équations du système (2), on obtient :
Les séquences et sont mutuellement indépendantes. Ce sont également des séquences de bruit gaussien blanc de moyenne nulle avec matrices de covariance et respectivement. L'avantage de ce formulaire est qu'il montre l'évolution du bruit discret entre chaque mesure. En conséquence, nous obtenons le modèle dynamique discret suivant :
 (3)
(3)
Équation pour :
= ![]() + , (4)
+ , (4)
où x et y sont les coordonnées de l'UAV à l'instant k et une séquence gaussienne de paramètres aléatoires avec une valeur moyenne nulle, qui est utilisée pour définir l'erreur. Cette séquence est supposée indépendante de () et ().
Les expressions (3) et (4) servent de base pour estimer l'emplacement du drone, où coordonnées k-e obtenu en utilisant le filtre de Kalman étendu. Modélisation des défaillances des systèmes de navigation par rapport à ce type Le filtre montre son efficacité significative.
Pour plus de clarté, donnons un petit exemple simple. Laissez certains drones voler avec une accélération uniforme, avec une accélération constante a.
Où x est la coordonnée du drone à l'instant t et δ est une variable aléatoire.
Supposons que nous disposions d'un capteur GPS qui reçoit des données sur la localisation d'un avion. Présentons le résultat de la modélisation de ce processus dans le progiciel MATLAB.

Riz. 1. Filtrage des lectures du capteur à l'aide d'un filtre de Kalman
En figue. 1 montre à quel point l’utilisation du filtrage de Kalman peut être efficace.
Cependant, dans des situations réelles, les signaux présentent souvent une dynamique non linéaire et un bruit anormal. C'est dans de tels cas que le filtre de Kalman étendu est utilisé. Si les variances de bruit ne sont pas trop grandes (c'est-à-dire que l'approximation linéaire est adéquate), l'utilisation d'un filtre de Kalman étendu fournit une solution au problème avec une grande précision. Cependant, dans le cas où le bruit n'est pas gaussien, le filtre de Kalman étendu ne peut pas être utilisé. Dans ce cas, un filtre partiel est généralement utilisé, qui utilise des méthodes intégrales numériques basées sur les méthodes de Monte Carlo avec des chaînes de Markov.
Filtre partiel
Imaginons l'un des algorithmes qui développent les idées du filtre de Kalman étendu - un filtre partiel. Le filtrage partiel est une technique de filtrage sous-optimale qui fonctionne en effectuant un regroupement de Monte Carlo sur un ensemble de particules qui représentent la distribution de probabilité du processus. Ici, une particule est un élément issu de la distribution a priori du paramètre estimé. L'idée de base d'un filtre partiel est que un grand nombre de les particules peuvent être utilisées pour représenter une estimation de la distribution. Plus le nombre de particules utilisé est grand, plus l’ensemble de particules représentera avec précision la distribution antérieure. Le filtre à particules est initialisé en y plaçant N particules issues d'une distribution préalable des paramètres que l'on souhaite estimer. L'algorithme de filtrage consiste à faire passer ces particules système spécial, puis peser à l'aide des informations obtenues en mesurant ces particules. Les particules résultantes et leurs masses associées représentent la distribution a posteriori du processus d'estimation. Le cycle est répété pour chaque nouvelle mesure et les poids des particules sont mis à jour pour représenter la distribution ultérieure. L’un des principaux problèmes de l’approche traditionnelle de filtration des particules est qu’elle aboutit généralement à ce que quelques particules aient un poids très élevé, alors que la plupart des autres ont un poids très faible. Cela conduit à une instabilité de filtration. Ce problème peut être résolu en introduisant un taux d’échantillonnage où N nouvelles particules sont extraites d’une distribution composée d’anciennes particules. Le résultat de l'estimation est obtenu en prenant un échantillon de la valeur moyenne d'un ensemble de particules. Si nous disposons de plusieurs échantillons indépendants, la moyenne de l’échantillon sera une estimation précise de la moyenne, donnant la variance finale.
Même si le filtre à particules est sous-optimal, alors que le nombre de particules tend vers l’infini, l’efficacité de l’algorithme se rapproche de la règle d’estimation bayésienne. Il est donc souhaitable d’avoir autant de particules que possible pour obtenir meilleur résultat. Malheureusement, cela conduit à une forte augmentation de la complexité des calculs, et, par conséquent, impose un compromis entre précision et vitesse de calcul. Ainsi, le nombre de particules doit être sélectionné en fonction des exigences de la tâche d'évaluation de la précision. Un autre facteur important pour le fonctionnement d’un filtre à particules est la limitation du taux d’échantillonnage. Comme mentionné précédemment, le taux d’échantillonnage est un paramètre important pour le filtrage des particules et sans lui, l’algorithme finira par dégénérer. L’idée est que si les poids sont répartis de manière trop inégale et que le seuil d’échantillonnage est sur le point d’être atteint, alors les particules de faible poids sont rejetées et l’ensemble restant forme une nouvelle densité de probabilité à partir de laquelle de nouveaux échantillons peuvent être prélevés. Choisir un seuil de fréquence d'échantillonnage est une tâche assez difficile, car aussi haute fréquence rend le filtre trop sensible au bruit et trop faible provoque une erreur importante. Un autre facteur important est la densité de probabilité.
Dans l’ensemble, l’algorithme de filtrage de particules présente de bonnes performances de calcul de position pour les cibles stationnaires et dans le cas de cibles se déplaçant relativement lentement avec une dynamique d’accélération inconnue. En général, l'algorithme de filtrage des particules est plus stable que le filtre de Kalman étendu et moins sujet à la dégénérescence et aux pannes graves. En cas de distribution non linéaire et non gaussienne cet algorithme le filtrage montre une très bonne précision dans la détermination de l'emplacement de la cible, tandis que l'algorithme de filtrage de Kalman étendu ne peut pas être utilisé dans de telles conditions. Les inconvénients de cette approche incluent sa plus grande complexité par rapport au filtre de Kalman étendu, ainsi que le fait qu'il n'est pas toujours évident de savoir comment choisir les bons paramètres pour cet algorithme.
Des recherches prometteuses dans ce domaine
L'utilisation d'un modèle de filtre de Kalman, similaire à celui que nous avons présenté, est visible dans, où il est utilisé pour améliorer les performances d'un système intégré (GPS + modèle de vision par ordinateur pour l'appariement avec une base géographique), et la situation de la panne des équipements de navigation par satellite est également simulée. Grâce au filtre de Kalman, les résultats du système en cas de panne ont été considérablement améliorés (par exemple, l'erreur de détermination de la hauteur a été réduite d'environ deux fois et les erreurs de détermination des coordonnées le long de différents axes ont été réduites de près de 9 fois) . Une utilisation similaire du filtre de Kalman est également proposée.
Un problème intéressant du point de vue d'un ensemble de méthodes est résolu dans . Il utilise également un filtre de Kalman à 5 états, avec quelques différences dans la construction du modèle. Le résultat obtenu dépasse le résultat du modèle que nous avons présenté grâce à l'utilisation de moyens d'intégration supplémentaires (des photos et des images thermiques sont utilisées). L'utilisation du filtre de Kalman dans ce cas permet de réduire l'erreur de détermination des coordonnées spatiales d'un point donné à une valeur de 5,5 m.
Conclusion
En conclusion, nous notons que l'utilisation du filtre de Kalman dans les systèmes de localisation de drones est pratiquée dans de nombreux développements modernes. Il existe un grand nombre de variantes et d'aspects de cette utilisation, jusqu'à l'utilisation simultanée de plusieurs filtres similaires avec des facteurs d'état différents. L'une des directions les plus prometteuses pour le développement des filtres de Kalman semble être la création d'un filtre modifié dont les erreurs seront représentées par un bruit coloré, ce qui le rendra encore plus précieux pour résoudre des problèmes réels. Un autre grand intérêt dans ce domaine est un filtre partiel capable de filtrer le bruit non gaussien. Cette diversité et ces résultats tangibles dans l'amélioration de la précision, notamment en cas de panne des systèmes de navigation par satellite standards, sont les principaux facteurs de l'impact de cette technologie sur divers domaines scientifiques liés au développement de systèmes de navigation précis et tolérants aux pannes pour divers aéronefs. .
Réviseurs :
Labunets V.G., Docteur en Sciences Techniques, Professeur, Professeur du Département fondements théoriques ingénierie radio de l'Université fédérale de l'Oural du nom du premier président de la Russie B.N. Eltsine, Ekaterinbourg ;
Ivanov V.E., docteur en sciences techniques, professeur, chef. Département de technologie et de communication de l'Université fédérale de l'Oural, du nom du premier président de la Russie B.N. Eltsine, Ekaterinbourg.
Lien bibliographique
Gavrilov A.V. UTILISER LE FILTRE KALMAN POUR RÉSOUDRE LES PROBLÈMES DE RAFFINAGE DES COORDONNÉES DES UAV // Enjeux contemporains sciences et éducation. – 2015. – N° 1-1.;URL : http://science-education.ru/ru/article/view?id=19453 (date d'accès : 02/01/2020). Nous portons à votre connaissance les magazines édités par la maison d'édition "Académie des Sciences Naturelles"