Liela apjoma datu analīze. Lielā datu mašīna. Mērogošana un līmeņu noteikšana
Pamatojoties uz materiāliem no pētījumiem un tendencēm
Lielie dati IT un mārketinga presē tiek runāts jau vairākus gadus. Un tas ir skaidrs: digitālās tehnoloģijas ir caurstrāvojušas dzīvi mūsdienu cilvēks, "viss ir uzrakstīts." Pieaug datu apjoms par dažādiem dzīves aspektiem, un vienlaikus pieaug arī informācijas uzglabāšanas iespējas.
Globālās tehnoloģijas informācijas glabāšanai
Avots: Hilberts un Lopess, “Pasaules tehnoloģiskā spēja uzglabāt, sazināties un aprēķināt informāciju”, Science, 2011 Global.
Lielākā daļa ekspertu piekrīt, ka datu pieauguma paātrināšana ir objektīva realitāte. Sociālie tīkli, mobilās ierīces, dati no mērierīcēm, biznesa informācija – tie ir tikai daži avotu veidi, kas var radīt milzīgus informācijas apjomus. Saskaņā ar pētījumu IDCDigitālais Visums, publicēts 2012. gadā, tuvāko 8 gadu laikā datu apjoms pasaulē sasniegs 40 ZB (zetabaitus), kas ir līdzvērtīgi 5200 GB uz katru planētas iedzīvotāju.
Digitālās informācijas vākšanas pieaugums ASV

Avots: IDC
Ievērojamu informācijas daļu veido nevis cilvēki, bet gan roboti mijiedarbojoties gan savā starpā, gan ar citiem datu tīkliem – tādiem kā, piemēram, sensori un viedierīces. Pie šāda pieauguma tempa datu apjoms pasaulē, pēc pētnieku domām, katru gadu dubultosies. Skaits virtuālo un fiziskie serveri pasaulē pieaugs desmitkārtīgi, pateicoties paplašināšanai un jaunu datu centru izveidei. Tā rezultātā pieaug nepieciešamība efektīvi izmantot šos datus un gūt peļņu no tiem. Tā kā lielo datu izmantošana uzņēmējdarbībā prasa ievērojamus ieguldījumus, jums ir skaidri jāsaprot situācija. Un būtībā tas ir vienkārši: jūs varat palielināt biznesa efektivitāti, samazinot izmaksas un/vai palielinot pārdošanas apjomu.
Kāpēc mums ir nepieciešami lielie dati?
Lielo datu paradigma definē trīs galvenos problēmu veidus.
- Simtiem terabaitu vai petabaitu datu glabāšana un pārvaldība, ko parastās relāciju datu bāzes nevar efektīvi izmantot.
- Organizējiet nestrukturētu informāciju, kas sastāv no tekstiem, attēliem, video un cita veida datiem.
- Big Data analīze, kas liek uzdot jautājumu par veidiem, kā strādāt ar nestrukturētu informāciju, analītisko atskaišu ģenerēšanu, kā arī prognozējošo modeļu ieviešanu.
Big Data projektu tirgus krustojas ar biznesa analītikas (BA) tirgu, kura globālais apjoms, pēc ekspertu domām, 2012. gadā sasniedza aptuveni 100 miljardus USD. Tas ietver tīkla tehnoloģiju komponentus, serverus, programmatūra un tehniskie pakalpojumi.
Tāpat Big Data tehnoloģiju izmantošana ir aktuāla ienākumu nodrošināšanas (RA) klases risinājumiem, kas paredzēti uzņēmumu darbības automatizēšanai. Mūsdienu sistēmas ienākumu garantijas ietver instrumentus neatbilstību noteikšanai un padziļinātu datu analīzi, kas ļauj laikus atklāt iespējamos zaudējumus vai informācijas sagrozījumus, kas varētu novest pie finanšu rezultātu pasliktināšanās. Uz šī fona Krievijas uzņēmumi, apliecinot pieprasījumu pēc Big Data tehnoloģijām vietējā tirgū, atzīmē, ka faktori, kas stimulē Big Data attīstību Krievijā, ir datu pieaugums, vadības lēmumu pieņemšanas paātrināšana un to kvalitātes uzlabošana.
Kas jums traucē strādāt ar lielajiem datiem
Mūsdienās tiek analizēti tikai 0,5% no uzkrātajiem digitālajiem datiem, neskatoties uz to, ka ir objektīvi nozares mēroga problēmas, kuras varētu atrisināt, izmantojot analītiskie risinājumi Big Data klase. Attīstītajos IT tirgos jau ir rezultāti, kurus var izmantot, lai novērtētu cerības, kas saistītas ar lielo datu uzkrāšanu un apstrādi.
Tiek apskatīts viens no galvenajiem faktoriem, kas bremzē Big Data projektu realizāciju, papildus augstajām izmaksām apstrādāto datu atlases problēma: tas ir, nosakot, kuri dati ir jāizgūst, jāuzglabā un jāanalizē un kuri ir jāignorē.
Daudzi biznesa pārstāvji atzīmē, ka grūtības īstenot Big Data projektus ir saistītas ar speciālistu - mārketinga speciālistu un analītiķu - trūkumu. Lielajos datos ieguldīto ieguldījumu atdeves ātrums ir tieši atkarīgs no to darbinieku darba kvalitātes, kuri nodarbojas ar padziļinātu un paredzamu analīzi. Organizācijā jau esošo datu milzīgo potenciālu bieži vien paši tirgotāji nevar efektīvi izmantot novecojušu biznesa procesu vai iekšējo noteikumu dēļ. Tāpēc lielo datu projektus uzņēmēji bieži uztver kā sarežģīti ne tikai īstenot, bet arī novērtēt rezultātus: savākto datu vērtību. Darba ar datiem īpašais raksturs liek tirgotājiem un analītiķiem pārslēgt uzmanību no tehnoloģijām un atskaišu veidošanas uz konkrētu biznesa problēmu risināšanu.
Sakarā ar lielo apjomu un liels ātrums datu plūsma, to savākšanas process ietver ETL procedūras reāllaikā. Uzziņai:ETL - noAngļuEkstrakts, Pārveidot, Ielādēt- burtiski “iegūšana, pārveidošana, ielāde”) - viens no galvenajiem vadības procesiem datu noliktavas, kas ietver: datu izgūšanu no ārējie avoti, to transformācija un tīrīšana, lai apmierinātu vajadzības ETL ir jāuztver ne tikai kā datu pārvietošanas process no vienas lietojumprogrammas uz citu, bet arī kā rīks datu sagatavošanai analīzei.
Un tad no ārējiem avotiem nākošo datu drošības nodrošināšanas jautājumiem jābūt risinājumiem, kas atbilst savāktās informācijas apjomam. Tā kā lielo datu analīzes metodes attīstās tikai pēc datu apjoma pieauguma, liela nozīme ir analītisko platformu spējai izmantot jaunas datu sagatavošanas un apkopošanas metodes. Tas liecina, ka, piemēram, dati par potenciālajiem pircējiem vai masīva datu noliktava ar klikšķu vēsturi tiešsaistes iepirkšanās vietnēs var interesēt dažādu problēmu risināšanu.
Grūtības neapstājas
Neskatoties uz visām grūtībām ar Big Data ieviešanu, bizness plāno palielināt investīcijas šajā jomā. Kā izriet no Gartner datiem, 2013. gadā 64% pasaules lielāko uzņēmumu jau ir ieguldījuši vai plāno investēt Big Data tehnoloģiju ieviešanā savā biznesā, savukārt 2012. gadā tādu bija 58%. Saskaņā ar Gartner pētījumu, vadošās nozares, kas iegulda lielajos datos, ir mediju uzņēmumi, telekomunikāciju, banku un pakalpojumu uzņēmumi. Veiksmīgus rezultātus no Big Data ieviešanas jau ir sasnieguši daudzi lielie mazumtirdzniecības nozares dalībnieki attiecībā uz datu izmantošanu, kas iegūti, izmantojot radiofrekvences identifikācijas rīkus, loģistiku un pārvietošanas sistēmas. papildināšana- uzkrāšana, papildināšana - R&T), kā arī no lojalitātes programmām. Veiksmīga mazumtirdzniecības pieredze mudina citus tirgus sektorus atrast jaunus efektīvi veidi lielo datu monetizācija, lai pārvērstu to analīzi par resursu, kas darbojas uzņēmējdarbības attīstībai. Pateicoties tam, pēc ekspertu domām, laika posmā līdz 2020. gadam investīcijas pārvaldībā un uzglabāšanā uz vienu datu gigabaitu samazināsies no 2 USD līdz 0,2 USD, bet Big Data tehnoloģisko īpašību izpētei un analīzei pieaugs tikai par 40%.
Izmaksas norādītas dažādās investīciju projektiem lielo datu jomā, tiem ir atšķirīgs raksturs. Izmaksu pozīcijas ir atkarīgas no produktu veidiem, kas tiek izvēlēti, pamatojoties uz noteiktiem lēmumiem. Investīciju projektos lielāko izmaksu daļu, pēc ekspertu domām, veido produkti, kas saistīti ar datu vākšanu, strukturēšanu, tīrīšanu un informācijas pārvaldību.
Kā tas tiek darīts
Ir daudzas programmatūras kombinācijas un aparatūra, kas ļauj jums izveidot efektīvi risinājumi Big Data dažādām biznesa disciplīnām: no sociālajiem medijiem un mobilās lietojumprogrammas, pirms tam paredzamā analīze un biznesa datu vizualizācija. Būtiska Big Data priekšrocība ir jauno rīku savietojamība ar uzņēmējdarbībā plaši izmantotām datu bāzēm, kas ir īpaši svarīga, strādājot ar starpdisciplināriem projektiem, piemēram, organizējot daudzkanālu pārdošanu un klientu atbalstu.
Darba ar Big Data secība sastāv no datu vākšanas, saņemtās informācijas strukturēšanas, izmantojot pārskatus un informācijas paneļus, ieskatu un kontekstu veidošanas un rīcības ieteikumu formulēšanas. Tā kā darbs ar Big Data ir saistīts ar lielām datu vākšanas izmaksām, kuru apstrādes rezultāts iepriekš nav zināms, galvenais uzdevums ir skaidri saprast, kam tie ir paredzēti, nevis cik daudz no tiem ir pieejams. Šajā gadījumā datu vākšana pārvēršas par informācijas iegūšanas procesu, kas nepieciešama tikai konkrētu problēmu risināšanai.
Piemēram, telekomunikāciju pakalpojumu sniedzēji apkopo milzīgu datu apjomu, tostarp ģeogrāfisko atrašanās vietu, kas tiek pastāvīgi atjaunināta. Šī informācija var būt komerciāla interese reklāmas aģentūrām, kuras to var izmantot, lai sniegtu mērķtiecīgu un vietēju reklāmu, kā arī mazumtirgotājiem un bankām. Šādiem datiem var būt svarīga loma, pieņemot lēmumu par mazumtirdzniecības vietas atvēršanu noteiktā vietā, pamatojoties uz datiem par spēcīgas mērķtiecīgas cilvēku plūsmas klātbūtni. Londonā ir piemērs reklāmas efektivitātes mērīšanai uz āra stendiem. Tagad šādas reklāmas sasniedzamību var izmērīt, tikai novietojot cilvēkus pie reklāmas konstrukcijām ar īpašu ierīci, kas skaita garāmgājējus. Salīdzinot ar šāda veida reklāmas efektivitātes mērījumiem, mobilo sakaru operators daudz vairāk iespēju - viņš precīzi zina savu abonentu atrašanās vietu, viņš zina viņu demogrāfiskos raksturlielumus, dzimumu, vecumu, ģimenes stāvokli utt.
Pamatojoties uz šādiem datiem, nākotnē ir perspektīva mainīt reklāmas ziņojuma saturu, izmantojot konkrētas personas, kas iet garām stendam, preferences. Ja dati liecina, ka garāmbraucošs cilvēks daudz ceļo, tad viņam varētu parādīt kāda kūrorta sludinājumu. Futbola spēles organizatori var tikai aplēst līdzjutēju skaitu, kad viņi ierodas uz spēli. Bet, ja viņiem būtu iespēja pieprasīt no operatora šūnu komunikācija informācija par to, kur apmeklētāji atradās stundu, dienu vai mēnesi pirms spēles, tas dotu iespēju organizatoriem plānot vietas, kur reklamēt nākamos mačus.
Vēl viens piemērs ir tas, kā bankas var izmantot lielos datus, lai novērstu krāpšanu. Ja klients ziņo par kartes nozaudēšanu, un, veicot pirkumu ar to, banka reāllaikā redz klienta tālruņa atrašanās vietu pirkuma zonā, kurā notiek darījums, banka var pārbaudīt informāciju klienta pieteikumā. lai redzētu, vai viņš nemēģina viņu maldināt. Vai arī pretēja situācija, kad klients veic pirkumu veikalā, banka redz, ka darījumam izmantotā karte un klienta tālrunis atrodas vienā vietā, banka var secināt, ka kartes īpašnieks to izmanto. Pateicoties šādām Big Data priekšrocībām, tiek paplašinātas tradicionālo datu noliktavu robežas.
Lai veiksmīgi pieņemtu lēmumu par Big Data risinājumu ieviešanu, uzņēmumam ir jāaprēķina investīciju gadījums, un tas rada lielas grūtības daudzu nezināmu komponentu dēļ. Analītikas paradokss šādos gadījumos ir nākotnes prognozēšana, pamatojoties uz pagātni, par kuru bieži trūkst datu. Šajā gadījumā svarīgs faktors ir skaidra sākotnējo darbību plānošana:
- Pirmkārt, ir jānosaka viena konkrēta biznesa problēma, kuras risināšanai tiks izmantotas Big Data tehnoloģijas, šis uzdevums kļūs par pamatu izvēlētās koncepcijas pareizības noteikšanai. Jums jākoncentrējas uz datu apkopošanu saistībā ar šo konkrēto uzdevumu, un koncepcijas pārbaudes laikā varat izmantot dažādus rīkus, procesus un pārvaldības paņēmienus, kas ļaus jums pieņemt pārdomātākus lēmumus nākotnē.
- Otrkārt, maz ticams, ka uzņēmums bez datu analītikas prasmēm un pieredzes spēs veiksmīgi īstenot Big Data projektu. Nepieciešamās zināšanas vienmēr izriet no iepriekšējās analītikas pieredzes, kas ir galvenais faktors, kas ietekmē darba ar datiem kvalitāti. Datu izmantošanas kultūrai ir liela nozīme, jo bieži vien informācijas analīze atklāj skarbā patiesība par biznesu, un, lai pieņemtu šo patiesību un strādātu ar to, ir nepieciešamas izstrādātas metodes darbam ar datiem.
- Treškārt, lielo datu tehnoloģiju vērtība ir sniegt ieskatu. Labu analītiķu tirgū joprojām trūkst. Viņus parasti sauc par speciālistiem, kuri dziļi izprot datu komerciālo nozīmi un zina, kā tos pareizi izmantot. Datu analīze ir līdzeklis, lai sasniegtu biznesa mērķus, un, lai izprastu lielo datu vērtību, jums ir attiecīgi jārīkojas un jāizprot savas darbības. Šajā gadījumā lielie dati sniegs daudz noderīga informācija par patērētājiem, uz kuru pamata var pieņemt uzņēmējdarbībai noderīgus lēmumus.
Neskatoties uz to, ka Krievijas lielo datu tirgus tikai sāk veidoties, atsevišķi projekti šajā jomā jau tiek īstenoti diezgan veiksmīgi. Daži no tiem ir veiksmīgi datu vākšanas jomā, piemēram, Federālā nodokļu dienesta un Tinkoff Credit Systems Bank projekti, citi - datu analīzes un rezultātu praktiskā pielietojuma ziņā: tas ir Synqera projekts.
Tinkoff Credit Systems Bank īstenoja projektu, lai ieviestu EMC2 Greenplum platformu, kas ir rīks masveidā paralēlai skaitļošanai. Pēdējos gados banka ir paaugstinājusi prasības uzkrātās informācijas apstrādes ātrumam un datu analīzei reāllaikā, ko izraisa augstais lietotāju skaita pieauguma temps. kredītkartes. Banka paziņoja par plāniem paplašināt lielo datu tehnoloģiju izmantošanu, īpaši nestrukturētu datu apstrādei un darbam ar korporatīvā informācija iegūti no dažādiem avotiem.
Krievijas Federālais nodokļu dienests pašlaik veido federālās datu noliktavas analītisko slāni. Uz tā pamata viens informācijas telpa un tehnoloģijas, lai piekļūtu nodokļu datiem statistikas un analītiskā apstrāde. Projekta īstenošanas laikā tiek veikts darbs, lai Federālā nodokļu dienesta vietējā līmenī centralizētu analītisko informāciju no vairāk nekā 1200 avotiem.
Vēl vienu interesants piemērs lielo datu analīzi reāllaikā veic Krievijas starta uzņēmums Synqera, kas izstrādāja Simplate platformu. Risinājuma pamatā ir liela datu apjoma apstrāde, programma analizē informāciju par klientiem, viņu pirkumu vēsturi, vecumu, dzimumu un pat garastāvokli. Pie kasēm kosmētikas veikalu ķēdē tika uzstādīti skārienekrāni ar sensoriem, kas atpazīst klientu emocijas. Programma nosaka cilvēka noskaņojumu, analizē informāciju par viņu, nosaka diennakts laiku un skenē veikala atlaižu datubāzi, pēc tam nosūta pircējam mērķtiecīgus ziņojumus par akcijām un Speciālie piedāvājumi. Šis risinājums palielina klientu lojalitāti un palielina mazumtirgotāju pārdošanas apjomu.
Ja runājam par ārvalstu veiksmīgiem gadījumiem, tad šajā ziņā interesanta ir Big Data tehnoloģiju izmantošanas pieredze uzņēmumā Dunkin`Donuts, kas produktu pārdošanai izmanto reāllaika datus. Digitālie displeji veikalos parāda piedāvājumus, kas mainās katru minūti, atkarībā no diennakts laika un preču pieejamības. Izmantojot kases čekus, uzņēmums saņem datus, kuri piedāvājumi guvuši vislielāko klientu atsaucību. Šāda datu apstrādes pieeja ļāva mums palielināt peļņu un preču apgrozījumu noliktavā.
Kā liecina Big Data projektu īstenošanas pieredze, šī joma veidota, lai veiksmīgi risinātu mūsdienu biznesa problēmas. Tajā pašā laikā svarīgs faktors komerciālo mērķu sasniegšanā, strādājot ar lielajiem datiem, ir pareizās stratēģijas izvēle, kas ietver analīzi, kas identificē patērētāju pieprasījumus, kā arī izmantošanu. inovatīvas tehnoloģijas lielo datu jomā.
Saskaņā ar globālo aptauju, ko katru gadu Econsultancy un Adobe kopš 2012. gada veic korporatīvo mārketinga speciālistu vidū, “lielie dati”, kas raksturo cilvēku rīcību internetā, var darīt daudz. Tie var optimizēt bezsaistes biznesa procesus, palīdzēt saprast, kā mobilo ierīču īpašnieki tās izmanto informācijas meklēšanai, vai vienkārši “padarīt mārketingu labāku”, t.i. efektīvāks. Turklāt pēdējā funkcija gadu no gada kļūst arvien populārāka, kā izriet no mūsu iesniegtās diagrammas.
Galvenās interneta mārketinga speciālistu darba jomas klientu attiecību jomā

Avots: Econsultancy un Adobe, publicēts- emarketer.com
Ņemiet vērā, ka respondentu tautība liela nozīme nav. Kā liecina KPMG 2013. gadā veiktā aptauja, “optimistu” īpatsvars, t.i. tie, kas izmanto lielos datus, izstrādājot biznesa stratēģiju, ir 56%, un atšķirības dažādos reģionos ir nelielas: no 63% Ziemeļamerikas valstīs līdz 50% EMEA.
Lielo datu izmantošana dažādos pasaules reģionos

Avots: KPMG, publicēts- emarketer.com
Tikmēr tirgotāju attieksme pret šādām “modes tendencēm” nedaudz atgādina kādu labi zināmu joku:
Saki, Vano, vai tev garšo tomāti?
- Man patīk ēst, bet ne šādi.
Neskatoties uz to, ka mārketinga speciālisti mutiski “mīl” Big Data un, šķiet, tos pat izmanto, patiesībā “viss ir sarežģīti”, rakstot par savām sirsnīgajām simpātijām sociālajos tīklos.
Saskaņā ar aptauju, ko Circle Research 2014. gada janvārī veica Eiropas mārketinga speciālistu vidū, 4 no 5 respondentiem neizmanto lielos datus (lai gan viņiem, protams, tas patīk). Iemesli ir dažādi. Neatlaidīgu skeptiķu ir maz - 17% un tieši tikpat cik viņu antipodu, t.i. tie, kas pārliecinoši atbild: "Jā." Pārējie vilcinās un šaubās, “purvs”. Viņi izvairās no tiešas atbildes, aizbildinoties ar tādiem ticamiem ieganstiem kā "vēl nē, bet drīz" vai "pagaidīsim, kamēr sāksies citi".
Lielo datu izmantošana mārketinga speciālistu vidū, Eiropa, 2014. gada janvāris

Avots:dnx, publicēts -e-tirgotājs.com
Kas viņus mulsina? Tīrās muļķības. Daži (tieši puse no viņiem) vienkārši netic šiem datiem. Citiem (to ir arī diezgan daudz - 55%) ir grūti korelēt “datu” un “lietotāju” kopas savā starpā. Dažiem cilvēkiem vienkārši ir (politiski pareizi izsakoties) iekšējs korporatīvais haoss: dati bez uzraudzības klīst starp mārketinga nodaļām un IT struktūrām. Citiem programmatūra nevar tikt galā ar darba pieplūdumu. Un tā tālāk. Tā kā kopējās daļas ievērojami pārsniedz 100%, ir skaidrs, ka “vairāku barjeru” situācija nav nekas neparasts.
Šķēršļi lielo datu izmantošanai mārketingā

Avots:dnx, publicēts -e-tirgotājs.com
Līdz ar to jāatzīst, ka pagaidām “Big Data” ir liels potenciāls, kas vēl ir jāizmanto. Starp citu, tas var būt iemesls, kāpēc Big Data zaudē savu "modes tendences" oreolu, kā liecina jau pieminētā uzņēmuma Econsultancy veiktā aptauja.
Nozīmīgākās tendences digitālajā mārketingā 2013.-2014

Avots: Konsultācijas un Adobe
Viņus nomaina cits karalis – satura mārketings. Cik ilgi?
Nevarētu teikt, ka lielie dati ir kaut kāda fundamentāli jauna parādība. Lieli datu avoti pastāv jau daudzus gadus: datu bāzes par klientu pirkumiem, kredītvēsturi, dzīvesveidu. Un gadiem ilgi zinātnieki ir izmantojuši šos datus, lai palīdzētu uzņēmumiem novērtēt risku un paredzēt nākotnes klientu vajadzības. Tomēr šodien situācija ir mainījusies divos aspektos:
Ir parādījušies sarežģītāki rīki un metodes dažādu datu kopu analīzei un apvienošanai;
Šos analītiskos rīkus papildina jaunu datu avotu lavīna, ko virza praktiski visu datu vākšanas un mērīšanas metožu digitalizācija.
Pieejamās informācijas klāsts ir gan iedvesmojošs, gan biedējošs pētniekiem, kas auguši strukturētās pētniecības vidēs. Patērētāju noskaņojumu uztver vietnes un visa veida sociālie mediji. Sludinājuma skatīšanās fakts tiek fiksēts ne tikai televizora pierīces, bet arī izmantojot digitālos tagus un mobilās ierīces sazinoties ar televizoru.
Uzvedības dati (piemēram, zvanu apjoms, iepirkšanās paradumi un pirkumi) tagad ir pieejami reāllaikā. Tādējādi lielu daļu no tā, ko iepriekš varēja iegūt, veicot pētījumus, tagad var uzzināt, izmantojot lielus datu avotus. Un visi šie informācijas līdzekļi tiek ģenerēti pastāvīgi, neatkarīgi no jebkādiem pētniecības procesiem. Šīs izmaiņas liek mums aizdomāties, vai lielie dati var aizstāt klasisko tirgus izpēti.
Runa nav par datiem, bet gan par jautājumiem un atbildēm.
Pirms nosaucam klasisko pētījumu nāves zvanu, mums sev jāatgādina, ka izšķiroša nozīme ir nevis noteiktu datu aktīvu klātbūtnei, bet gan kaut kam citam. Kas tieši? Mūsu spēja atbildēt uz jautājumiem, lūk, kas. Viena smieklīga lieta jaunajā lielo datu pasaulē ir tā, ka rezultāti, kas iegūti no jauniem datu aktīviem, rada vēl vairāk jautājumu, un uz šiem jautājumiem parasti vislabāk var atbildēt tradicionālie pētījumi. Tādējādi, pieaugot lielajiem datiem, mēs redzam paralēli pieaugošu “mazo datu” pieejamībai un nepieciešamībai, kas var sniegt atbildes uz jautājumiem no lielo datu pasaules.
Apsveriet situāciju: liels reklāmdevējs nepārtraukti uzrauga veikala trafiku un pārdošanas apjomus reāllaikā. Esošās pētījumu metodoloģijas (kurā mēs aptaujājam dalībniekus par viņu pirkšanas motivāciju un uzvedību pārdošanas vietās) palīdz mums labāk atlasīt konkrētus pircēju segmentus. Šīs metodes var paplašināt, iekļaujot plašāku lielo datu līdzekļu klāstu līdz vietai, kur lielie dati kļūst par pasīvās novērošanas līdzekli, un pētniecība kļūst par metodi nepārtrauktai, šauri mērķētai izmaiņu vai notikumu izpētei, kas prasa izpēti. Šādi lielie dati var atbrīvot pētniecību no nevajadzīgas rutīnas. Primārajiem pētījumiem vairs nav jākoncentrējas uz notiekošo (lielie dati to darīs). Tā vietā primārie pētījumi var koncentrēties uz izskaidrošanu, kāpēc mēs novērojam konkrētas tendences vai novirzes no tendencēm. Pētnieks varēs mazāk domāt par datu iegūšanu un vairāk par to, kā tos analizēt un izmantot.
Tajā pašā laikā mēs redzam, ka lielie dati var atrisināt vienu no mūsu lielākajām problēmām: pārāk ilgu pētījumu problēmu. Pašu pētījumu pārbaude ir parādījusi, ka pārlieku uzpūsti pētniecības instrumenti negatīvi ietekmē datu kvalitāti. Lai gan daudzi eksperti jau sen bija atzinuši šo problēmu, viņi vienmēr atbildēja ar frāzi: "Bet man ir vajadzīga šī informācija augstākajai vadībai", un garās intervijas turpinājās.
Lielo datu pasaulē, kur kvantitatīvos rādītājus var iegūt, izmantojot pasīvu novērošanu, šī problēma kļūst strīdīga. Atkal padomāsim par visiem šiem pētījumiem par patēriņu. Ja lielie dati sniedz mums ieskatu patēriņā, izmantojot pasīvo novērošanu, tad primārajiem aptauju pētījumiem vairs nav jāapkopo šāda veida informācija, un mēs beidzot varam atbalstīt savu redzējumu par īsajām aptaujām ar kaut ko vairāk nekā vēlmju domāšanu.
Big Data ir nepieciešama jūsu palīdzība
Visbeidzot, “liels” ir tikai viena lielo datu īpašība. Raksturlielums “liels” attiecas uz datu lielumu un mērogu. Protams, šī ir galvenā iezīme, jo šo datu apjoms pārsniedz visu, ar ko mēs esam strādājuši iepriekš. Taču svarīgas ir arī citas šo jauno datu plūsmu īpašības: tās bieži ir slikti formatētas, nestrukturētas (vai labākajā gadījumā daļēji strukturētas) un pilnas ar nenoteiktību. Jaunā datu pārvaldības joma, kas trāpīgi nosaukta par entītiju analīzi, risina problēmu, kas saistīta ar lielo datu trokšņa samazināšanu. Tās uzdevums ir analizēt šīs datu kopas un noskaidrot, cik novērojumu attiecas uz vienu un to pašu personu, kuri novērojumi ir aktuāli un kuri ir izmantojami.
Šāda veida datu tīrīšana ir nepieciešama, lai noņemtu troksni vai kļūdainus datus, strādājot ar lieliem vai maziem datu līdzekļiem, taču ar to nepietiek. Mums ir arī jārada konteksts ap lielajiem datu līdzekļiem, pamatojoties uz mūsu iepriekšējo pieredzi, analīzi un zināšanām par kategorijām. Faktiski daudzi analītiķi norāda uz spēju pārvaldīt lielajiem datiem raksturīgo nenoteiktību kā konkurences priekšrocību avotu, jo tas ļauj pieņemt labākus lēmumus.
Šeit primārie pētījumi ne tikai tiek atbrīvoti no lielajiem datiem, bet arī veicina satura veidošanu un analīzi lielo datu ietvaros.
Spilgts piemērs tam ir mūsu jaunā, būtiski atšķirīgā zīmola kapitāla regulējuma piemērošana sociālajiem medijiem (mēs runājam par izstrādātoMillward Brūnsjauna pieeja zīmola kapitāla mērīšanaiThe Nozīmīgi Savādāk Ietvars- "Jēgīgās atšķirības paradigma" -R & T ). Modelis ir uzvedības testēts konkrētos tirgos, ieviests standarta veidā, un to var viegli pielietot citām mārketinga vertikālēm un lēmumu atbalsta informācijas sistēmām. Citiem vārdiem sakot, mūsu zīmola kapitāla modelim, kura pamatā ir (lai gan ne tikai) aptaujas pētījumi, ir visas funkcijas, kas nepieciešamas, lai pārvarētu lielo datu nestrukturēto, nesadalīto un nenoteikto raksturu.
Apsveriet sociālo mediju sniegtos patērētāju noskaņojuma datus. Neapstrādātā veidā patērētāju noskaņojuma maksimumi un zemākie rādītāji ļoti bieži ir minimāli korelēti ar zīmola taisnīguma un uzvedības mērījumiem bezsaistē: datos vienkārši ir pārāk daudz trokšņu. Taču mēs varam samazināt šo troksni, piemērojot mūsu patērētāju nozīmes, zīmolu diferenciācijas, dinamikas un atšķirtspējas modeļus neapstrādātiem patērētāju noskaņojuma datiem — veids, kā apstrādāt un apkopot sociālo mediju datus šajās dimensijās.
Kad dati ir sakārtoti saskaņā ar mūsu sistēmu, identificētās tendences parasti atbilst bezsaistes zīmolu taisnīgumam un uzvedības pasākumiem. Būtībā sociālo mediju dati nevar runāt paši par sevi. Lai tos izmantotu šim nolūkam, ir nepieciešama mūsu pieredze un modeļi, kas veidoti, pamatojoties uz zīmoliem. Kad sociālie mediji sniedz mums unikālu informāciju, kas izteikta valodā, ko patērētāji lieto zīmolu aprakstam, mums šī valoda ir jāizmanto, veidojot pētījumu, lai primārie pētījumi būtu daudz efektīvāki.
Atbrīvoto pētījumu priekšrocības
Tas mūs atgriež pie tā, ka lielie dati ne tik daudz aizstāj pētniecību, bet gan tos atbrīvo. Pētnieki tiks atbrīvoti no nepieciešamības katram jaunam gadījumam izveidot jaunu pētījumu. Arvien pieaugošos lielo datu līdzekļus var izmantot dažādām pētniecības tēmām, ļaujot turpmākajos primārajos pētījumos iedziļināties tēmā un aizpildīt esošās nepilnības. Pētnieki tiks atbrīvoti no nepieciešamības paļauties uz pārlieku uzpūstām aptaujām. Tā vietā viņi var izmantot īsas aptaujas un koncentrēties uz svarīgākajiem parametriem, kas uzlabo datu kvalitāti.
Līdz ar šo atbrīvošanos pētnieki varēs izmantot savus iedibinātos principus un idejas, lai pievienotu lielajiem datu līdzekļiem precizitāti un nozīmi, tādējādi radot jaunas aptauju izpētes jomas. Šim ciklam būtu jārada lielāka izpratne par virkni stratēģisku jautājumu un galu galā virzība uz to, kam vienmēr jābūt mūsu primārajam mērķim – informēt un uzlabot zīmola un komunikācijas lēmumu kvalitāti.
Parasti, runājot par nopietnu analītisko apstrādi, it īpaši, ja viņi izmanto terminu datu ieguve, viņi nozīmē, ka ir milzīgs datu apjoms. Kopumā tas tā nav, jo diezgan bieži ir jāapstrādā nelielas datu kopas, un modeļu atrašana tajās nav vieglāka kā simtiem miljonu ierakstu. Lai gan nav šaubu, ka nepieciešamība meklēt modeļus lielās datubāzēs sarežģī jau tā nenozīmīgo analīzes uzdevumu.
Īpaši šī situācija ir raksturīga uzņēmumiem, kas saistīti ar Mazumtirdzniecība, telekomunikācijas, bankas, internets. Viņu datubāzēs tiek uzkrāts milzīgs daudzums informācijas, kas saistīta ar darījumiem: čeki, maksājumi, zvani, žurnāli utt.
Nav universālu analīzes metožu vai algoritmu, kas piemēroti visiem gadījumiem un jebkuram informācijas apjomam. Datu analīzes metodes ievērojami atšķiras pēc veiktspējas, rezultātu kvalitātes, lietošanas vienkāršības un datu prasībām. Optimizāciju var veikt dažādos līmeņos: aprīkojums, datu bāzes, analītiskā platforma, sākotnējo datu sagatavošana, specializēti algoritmi. Liela apjoma datu analīzei nepieciešama īpaša pieeja, jo... ir tehniski grūti tos apstrādāt, izmantojot tikai " brutālu spēku", t.i., izmantojot jaudīgāku aprīkojumu.
Protams, ir iespējams palielināt datu apstrādes ātrumu, pateicoties efektīvākai aparatūrai, jo īpaši tāpēc, ka mūsdienu serveros un darbstacijās tiek izmantoti daudzkodolu procesori, RAM ievērojams izmērs un spēcīgs disku masīvi. Tomēr ir daudzi citi veidi, kā apstrādāt lielu datu apjomu, kas ļauj palielināt mērogojamību un nav nepieciešami bezgalīga atjaunošana iekārtas.
DBVS iespējas
Mūsdienu datubāzēs ir iekļauti dažādi mehānismi, kuru izmantošana ievērojami palielinās analītiskās apstrādes ātrumu:
- Sākotnējais datu aprēķins. Informācija, kas visbiežāk tiek izmantota analīzei, var tikt aprēķināta iepriekš (piemēram, naktī) un uzglabāta formā, kas sagatavota apstrādei datu bāzes serverī daudzdimensionālu kubu, materializētu skatu un īpašu tabulu veidā.
- Tabulu saglabāšana kešatmiņā RAM. Datus, kas aizņem maz vietas, bet kuriem bieži piekļūst analīzes procesā, piemēram, direktorijus, var saglabāt kešatmiņā RAM, izmantojot datu bāzes rīkus. Tas daudzkārt samazina zvanus uz lēnāku diska apakšsistēmu.
- Tabulu sadalīšana starpsienās un tabulu telpās. Varat ievietot datus, indeksus un palīgtabulas atsevišķos diskos. Tas ļaus DBVS paralēli lasīt un ierakstīt informāciju diskos. Turklāt tabulas var sadalīt nodalījumos, lai, piekļūstot datiem, būtu minimāls diska darbību skaits. Piemēram, ja visbiežāk analizējam pēdējā mēneša datus, tad loģiski varam izmantot vienu tabulu ar vēsturiskajiem datiem, bet fiziski sadalīt vairākos nodalījumos, lai, piekļūstot ikmēneša datiem, tiktu nolasīts neliels nodalījums un nav piekļuves. visiem vēsturiskajiem datiem.
Šī ir tikai daļa no iespējām, ko nodrošina mūsdienu DBVS. Informācijas izguves ātrumu no datu bāzes var palielināt vēl desmitos veidos: racionāla indeksēšana, vaicājumu plānu veidošana, SQL vaicājumu paralēla apstrāde, klasteru izmantošana, analizēto datu sagatavošana, izmantojot saglabātās procedūras un trigerus datu bāzes servera pusē utt. . Turklāt daudzus no šiem mehānismiem var izmantot, izmantojot ne tikai “smagās” DBVS, bet arī bezmaksas datu bāzes datus.
Modeļu apvienošana
Ātruma palielināšanas iespējas neaprobežojas tikai ar datu bāzes veiktspējas optimizēšanu, daudz ko var izdarīt, kombinējot dažādus modeļus. Ir zināms, ka apstrādes ātrums ir būtiski saistīts ar izmantotā matemātiskā aparāta sarežģītību. Jo vienkāršāki tiek izmantoti analīzes mehānismi, jo ātrāk tiek analizēti dati.
Datu apstrādes scenāriju iespējams konstruēt tā, ka dati tiek “izlaisti” caur modeļu sietu. Šeit ir piemērota vienkārša ideja: netērējiet laiku, lai apstrādātu to, kas jums nav jāanalizē.
Vispirms tiek izmantoti vienkāršākie algoritmi. Daļa no datiem, kurus var apstrādāt, izmantojot šādus algoritmus, un kurus ir bezjēdzīgi apstrādāt, izmantojot vairāk sarežģītas metodes, tiek analizēts un izslēgts no turpmākās apstrādes. Atlikušie dati tiek pārsūtīti uz nākamo apstrādes posmu, kur tiek izmantoti sarežģītāki algoritmi un tā tālāk ķēdē. Apstrādes skripta pēdējā mezglā tiek izmantoti vissarežģītākie algoritmi, taču analizēto datu apjoms ir daudzkārt mazāks nekā sākotnējā paraugā. Tā rezultātā kopējais laiks, kas nepieciešams visu datu apstrādei, tiek samazināts par lielumu kārtām.
Dosim praktisks piemērs izmantojot šo pieeju. Risinot pieprasījuma prognozēšanas problēmu, sākotnēji ieteicams veikt XYZ analīzi, kas ļauj noteikt, cik stabils ir pieprasījums pēc dažādām precēm. X grupas produkti tiek pārdoti diezgan konsekventi, tāpēc prognožu algoritmu pielietošana tiem ļauj iegūt kvalitatīvu prognozi. Y grupas produkti tiek pārdoti mazāk konsekventi, iespējams, ir vērts tiem veidot modeļus nevis katram rakstam, bet grupai, tas ļauj izlīdzināt laikrindas un nodrošināt prognozēšanas algoritma darbību. Z grupas produkti tiek pārdoti haotiski, tāpēc tiem vispār nav jāveido prognozēšanas modeļi, nepieciešamība pēc tiem jāaprēķina pēc vienkāršām formulām, piemēram, vidējie mēneša pārdošanas apjomi.
Saskaņā ar statistiku, aptuveni 70% no sortimenta veido Z grupas produkti. Vēl aptuveni 25% ir Y grupas preces, un tikai aptuveni 5% ir X grupas preces. Tādējādi sarežģītu modeļu uzbūve un pielietojums ir aktuāls ne vairāk kā 30% produktu. Tāpēc, izmantojot iepriekš aprakstīto pieeju, analīzes un prognozēšanas laiks samazināsies 5-10 reizes.
Paralēlā apstrāde
Vēl viena efektīva stratēģija liela datu apjoma apstrādei ir datu sadalīšana segmentos un modeļu izveide katram segmentam atsevišķi, pēc tam rezultātu apvienošana. Visbiežāk lielos datu apjomos var identificēt vairākas apakškopas, kas atšķiras viena no otras. Tās varētu būt, piemēram, klientu grupas, produkti, kas uzvedas līdzīgi un kuriem vēlams būvēt vienu modeli.
Šajā gadījumā tā vietā, lai izveidotu vienu sarežģītu modeli visiem, jūs varat izveidot vairākus vienkāršus katram segmentam. Šī pieeja ļauj palielināt analīzes ātrumu un samazināt atmiņas prasības, apstrādājot mazākus datu apjomus vienā piegājienā. Turklāt šajā gadījumā analītisko apstrādi var paralēli, kas arī pozitīvi ietekmē pavadīto laiku. Turklāt dažādi analītiķi var izveidot modeļus katram segmentam.
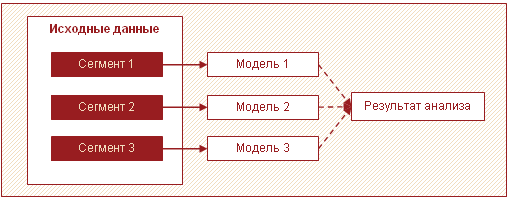
Papildus ātruma palielināšanai šai pieejai ir vēl viena svarīga priekšrocība - vairākus salīdzinoši vienkāršus modeļus atsevišķi ir vieglāk izveidot un uzturēt nekā vienu lielu. Jūs varat palaist modeļus pa posmiem, tādējādi iegūstot pirmos rezultātus pēc iespējas īsākā laikā.
Reprezentatīvie paraugi
Ja ir pieejami lieli datu apjomi, modeļa izveidošanai var izmantot ne visu informāciju, bet gan noteiktu apakškopu – reprezentatīvu paraugu. Pareizi sagatavots reprezentatīvs paraugs satur informāciju, kas nepieciešama augstas kvalitātes modeļa izveidošanai.
Analītiskās apstrādes process ir sadalīts 2 daļās: modeļa izveidošana un konstruētā modeļa piemērošana jauniem datiem. Sarežģīta modeļa izveide ir resursietilpīgs process. Atkarībā no izmantotā algoritma dati tiek saglabāti kešatmiņā, skenēti tūkstošiem reižu, tiek aprēķināti daudzi palīgparametri utt. Jau uzbūvēta modeļa piemērošana jauniem datiem prasa desmitiem un simtiem reižu mazāk resursu. Ļoti bieži tas ir saistīts ar dažu vienkāršu funkciju aprēķināšanu.
Tādējādi, ja modelis ir veidots uz salīdzinoši nelielām kopām un pēc tam tiek piemērots visai datu kopai, tad rezultāta iegūšanas laiks tiks samazināts par lielumu, salīdzinot ar mēģinājumu pilnībā apstrādāt visu esošo datu kopu.

Reprezentatīvu paraugu iegūšanai ir īpašas metodes, piemēram, paraugu ņemšana. To izmantošana ļauj palielināt analītiskās apstrādes ātrumu, nezaudējot analīzes kvalitāti.
Kopsavilkums
Aprakstītās pieejas ir tikai neliela daļa no metodēm, kas ļauj analizēt milzīgus datu apjomus. Ir arī citas metodes, piemēram, īpašu mērogojamu algoritmu izmantošana, hierarhiskie modeļi, logu apmācība utt.
Analīze milzīgas bāzes Datu pārvaldība ir nenozīmīgs uzdevums, ko vairumā gadījumu nevar atrisināt uzreiz, taču mūsdienu datu bāzes un analītiskās platformas piedāvā daudzas metodes šīs problēmas risināšanai. Lietojot saprātīgi, sistēmas spēj apstrādāt terabaitus datu pieņemamā ātrumā.
HSE skolotāju sleja par mītiem un gadījumiem darbā ar lielajiem datiem
Uz grāmatzīmēm
Nacionālās pētniecības universitātes Ekonomikas augstskolas Jauno mediju skolas skolotāji Konstantīns Romanovs un Aleksandrs Pjatigorskis, kurš ir arī Beeline digitālās transformācijas direktors, vietnei uzrakstīja sleju par galvenajiem maldīgajiem priekšstatiem par lielajiem datiem — izmantošanas piemēri. tehnoloģija un instrumenti. Autori ierosina, ka publikācija palīdzēs uzņēmumu vadītājiem izprast šo jēdzienu.
Mīti un maldīgi priekšstati par lielajiem datiem
Lielie dati nav mārketings
Lielo datu jēdziens ir kļuvis ļoti moderns – tas tiek lietots miljonos situāciju un ar simtiem dažādu interpretāciju, kas bieži vien nav saistīts ar to, kas tas ir. Jēdzieni bieži tiek aizstāti cilvēku galvās, un lielie dati tiek sajaukti ar mārketinga produktu. Turklāt dažos uzņēmumos Big Data ir daļa no mārketinga nodaļas. Lielo datu analīzes rezultāts patiešām var būt mārketinga aktivitāšu avots, bet nekas vairāk. Apskatīsim, kā tas darbojas.
Ja mēs identificējām sarakstu ar tiem, kuri pirms diviem mēnešiem mūsu veikalā iegādājās preces, kuru vērtība pārsniedz trīs tūkstošus rubļu, un pēc tam nosūtīja šiem lietotājiem kādu piedāvājumu, tad tas ir tipisks mārketings. Mēs iegūstam skaidru modeli no strukturālajiem datiem un izmantojam tos, lai palielinātu pārdošanas apjomu.
Taču, ja apvienojam CRM datus ar straumēšanas informāciju no, piemēram, Instagram, un analizējam tos, atrodam modeli: cilvēkam, kurš trešdienas vakarā ir samazinājis savu aktivitāti un kura jaunākajā fotoattēlā redzami kaķēni, vajadzētu izteikt noteiktu piedāvājumu. Tas jau būs Big Data. Mēs atradām aktivizētāju, nodevām to tirgotājiem, un viņi to izmantoja saviem mērķiem.
No tā izriet, ka tehnoloģija parasti strādā ar nestrukturētiem datiem, un pat tad, ja dati ir strukturēti, sistēma joprojām turpina meklēt tajos slēptos modeļus, ko mārketings nedara.
Lielie dati nav IT
Šī stāsta otrā galējība: Big Data bieži tiek sajaukta ar IT. Tas ir saistīts ar faktu, ka in Krievijas uzņēmumi IT speciālisti parasti ir visu tehnoloģiju, tostarp lielo datu, virzītājspēki. Tāpēc, ja viss notiek šajā nodaļā, uzņēmumam kopumā rodas iespaids, ka tā ir kaut kāda IT darbība.
Patiesībā šeit ir būtiska atšķirība: Big Data ir darbība, kuras mērķis ir iegūt konkrētu produktu, kas nebūt nav saistīts ar IT, lai gan tehnoloģija bez tā nevar pastāvēt.
Lielie dati ne vienmēr ir informācijas vākšana un analīze
Ir vēl viens nepareizs priekšstats par lielajiem datiem. Ikviens saprot, ka šī tehnoloģija ietver lielu datu apjomu, taču ne vienmēr ir skaidrs, kāda veida dati ir domāti. Ikviens var vākt un izmantot informāciju, tagad tas ir iespējams ne tikai filmās par, bet arī jebkurā, pat ļoti mazā uzņēmumā. Jautājums tikai, ko tieši savākt un kā to izmantot savā labā.
Bet tas ir jāsaprot Lielā tehnoloģija Dati nebūs absolūti nekādas informācijas vākšana un analīze. Piemēram, ja sociālajos tīklos apkoposiet datus par konkrētu personu, tie nebūs Big Data.
Kas īsti ir lielie dati?
Lielie dati sastāv no trim elementiem:
- dati;
- analītika;
- tehnoloģijas.
Lielie dati nav tikai viens no šiem komponentiem, bet gan visu trīs elementu kombinācija. Cilvēki bieži aizstāj jēdzienus: daži uzskata, ka lielie dati ir tikai dati, citi uzskata, ka tā ir tehnoloģija. Bet patiesībā neatkarīgi no tā, cik daudz datu jūs savācat, bez tiem jūs nevarat darīt neko nepieciešamās tehnoloģijas un analītiķi. Ja ir laba analīze, bet nav datu, tas ir vēl sliktāk.
Ja mēs runājam par datiem, tie ir ne tikai teksti, bet arī visi Instagram ievietotie fotoattēli un kopumā viss, ko var analizēt un izmantot dažādiem mērķiem un uzdevumiem. Citiem vārdiem sakot, dati attiecas uz milzīgiem dažādu struktūru iekšējo un ārējo datu apjomiem.
Nepieciešama arī analīze, jo Big Data uzdevums ir izveidot dažus modeļus. Tas ir, analītika ir slēpto atkarību identificēšana un jaunu jautājumu un atbilžu meklēšana, pamatojoties uz visa neviendabīgo datu apjoma analīzi. Turklāt lielie dati uzdod jautājumus, kurus nevar tieši iegūt no šiem datiem.
Runājot par attēliem, tas, ka ievietojat fotogrāfiju, kurā esat ģērbies zilā T-kreklā, neko nenozīmē. Bet, ja izmantosi fotogrāfiju Big Data modelēšanai, var izrādīties, ka tieši tagad tev vajadzētu piedāvāt aizdevumu, jo tavā sociālajā grupā šāda uzvedība liecina par noteiktu parādību darbībā. Tāpēc “plieni” dati bez analītikas, bez slēptu un nepārprotamu atkarību identificēšanas nav lielie dati.
Tātad mums ir lieli dati. Viņu klāsts ir milzīgs. Mums ir arī analītiķis. Bet kā mēs varam nodrošināt, ka no šiem neapstrādātajiem datiem mēs nonākam pie konkrēta risinājuma? Lai to izdarītu, mums ir vajadzīgas tehnoloģijas, kas ļauj tos ne tikai uzglabāt (un iepriekš tas nebija iespējams), bet arī analizēt.
Vienkārši sakot, ja jums ir daudz datu, jums būs nepieciešamas tehnoloģijas, piemēram, Hadoop, kas ļauj saglabāt visu informāciju sākotnējā formā vēlākai analīzei. Šāda veida tehnoloģija radās interneta gigantos, jo viņi bija pirmie, kas saskārās ar liela datu apjoma glabāšanas un analīzes problēmu turpmākai monetizācijai.
Papildus optimizētas un lētas datu glabāšanas rīkiem jums ir nepieciešami analītiskie rīki, kā arī izmantotās platformas papildinājumi. Piemēram, ap Hadoop jau ir izveidojusies vesela saistītu projektu un tehnoloģiju ekosistēma. Šeit ir daži no tiem:
- Pig ir deklaratīva datu analīzes valoda.
- Hive - datu analīze, izmantojot valodu, kas līdzīga SQL.
- Oozie — Hadoop darbplūsma.
- Hbase ir datu bāze (bez relāciju), līdzīga Google Big Table.
- Mahout — mašīnmācība.
- Sqoop - datu pārsūtīšana no RSDB uz Hadoop un otrādi.
- Flume - žurnālu pārsūtīšana uz HDFS.
- Zookeeper, MRUnit, Avro, Giraph, Ambari, Cassandra, HCatalog, Fuse-DFS un tā tālāk.
Visi šie rīki ir pieejami ikvienam bez maksas, taču ir arī vairāki maksas papildinājumi.
Turklāt ir nepieciešami speciālisti: izstrādātājs un analītiķis (tā sauktais datu zinātnieks). Vajadzīgs arī vadītājs, kurš saprastu, kā šo analīzi pielietot konkrētas problēmas risināšanai, jo pati par sevi ir pilnīgi bezjēdzīga, ja tā nav integrēta biznesa procesos.
Visiem trim darbiniekiem jāstrādā kā komandai. Vadītājam, kurš uzdod datu zinātnes speciālistam atrast noteiktu modeli, ir jāsaprot, ka viņš ne vienmēr atradīs tieši to, kas viņam nepieciešams. Tādā gadījumā vadītājam rūpīgi jāieklausās datu zinātnieka atrastajā, jo bieži vien viņa atklājumi izrādās interesantāki un biznesam noderīgāki. Jūsu uzdevums ir piemērot to uzņēmumam un izveidot no tā produktu.
Neskatoties uz to, ka tagad ir daudz dažādu mašīnu un tehnoloģiju, galīgais lēmums vienmēr paliek cilvēkam. Lai to izdarītu, informācija ir kaut kā jāvizualizē. Šim nolūkam ir diezgan daudz rīku.
Visspilgtākais piemērs ir ģeoanalītiskie ziņojumi. Uzņēmums Beeline daudz sadarbojas ar dažādu pilsētu un reģionu valdībām. Ļoti bieži šīs organizācijas pasūta pārskatus, piemēram, “Satiksmes sastrēgumi noteiktā vietā”.
Ir skaidrs, ka šādam ziņojumam ir jānonāk valsts aģentūrās vienkāršā un saprotamā formā. Ja mēs viņiem nodrošināsim milzīgu un pilnīgi nesaprotamu tabulu (tas ir, informāciju tādā formā, kādā mēs to saņemam), viņi diez vai iegādāsies šādu pārskatu - tas būs pilnīgi bezjēdzīgi, viņi no tā neiegūs zināšanas, viņi gribēja saņemt.
Tāpēc neatkarīgi no tā, cik labi ir datu zinātnieki un neatkarīgi no tā, kādus modeļus viņi atrod, jūs nevarēsit strādāt ar šiem datiem bez labiem vizualizācijas rīkiem.
Datu avoti
Iegūto datu masīvs ir ļoti liels, tāpēc to var iedalīt vairākās grupās.
Uzņēmuma iekšējie dati
Lai gan 80% no savāktajiem datiem pieder šai grupai, šis avots ne vienmēr tiek izmantots. Bieži vien tie ir dati, kas šķietami nevienam nav vajadzīgi, piemēram, žurnāli. Bet, ja paskatās uz tiem no cita leņķa, dažreiz tajos var atrast negaidītus rakstus.
Shareware avoti
Tas ietver datus sociālie tīkli, internets un viss, kur tajā var iekļūt bez maksas. Kāpēc tā ir bezmaksas koplietošanas programmatūra? No vienas puses, šie dati ir pieejami ikvienam, taču, ja esat liels uzņēmums, tad to iegūšana desmitiem tūkstošu, simtu vai miljonu klientu lielas abonentu bāzes apjomā vairs nav viegls uzdevums. Tāpēc ir maksas pakalpojumi lai sniegtu šos datus.
Maksas avoti
Tas ietver uzņēmumus, kas pārdod datus par naudu. Tie var būt telekomunikācijas, DMP, interneta uzņēmumi, kredītu biroji un apkopotāji. Krievijā telekomunikācijas nepārdod datus. Pirmkārt, tas ir ekonomiski neizdevīgi, otrkārt, tas ir aizliegts ar likumu. Tāpēc viņi pārdod to apstrādes rezultātus, piemēram, ģeoanalītiskās atskaites.
Atvērtie dati
Valsts ir pretimnākoša uzņēmējiem un dod tiem iespēju izmantot savāktos datus. Rietumos tas ir attīstīts lielākā mērā, bet arī Krievija šajā ziņā iet līdzi laikam. Piemēram, ir Maskavas valdības atvērto datu portāls, kurā tiek publicēta informācija par dažādiem pilsētas infrastruktūras objektiem.
Maskavas iedzīvotājiem un viesiem dati tiek parādīti tabulas un kartogrāfiskā veidā, bet izstrādātājiem - īpašos mašīnlasāmos formātos. Kamēr projekts darbojas ierobežotā režīmā, tas attīstās, kas nozīmē, ka tas ir arī datu avots, ko varat izmantot saviem biznesa uzdevumiem.
Pētījumi
Kā jau minēts, Big Data uzdevums ir atrast modeli. Bieži vien visā pasaulē veiktie pētījumi var kļūt par atbalsta punktu konkrēta modeļa atrašanai – jūs varat iegūt konkrētu rezultātu un mēģināt pielietot līdzīgu loģiku saviem mērķiem.
Lielie dati ir joma, kurā nav spēkā visi matemātikas likumi. Piemēram, “1” + “1” nav “2”, bet daudz vairāk, jo, sajaucot datu avotus, efektu var ievērojami uzlabot.
Produktu piemēri
Daudzi cilvēki ir pazīstami ar mūzikas atlases pakalpojumu Spotify. Tas ir lieliski, jo tas nejautā lietotājiem, kāds ir viņu šodienas noskaņojums, bet gan aprēķina to, pamatojoties uz tai pieejamajiem avotiem. Viņš vienmēr zina, kas tev tagad vajadzīgs – džezs vai hārdroks. Šī ir galvenā atšķirība, kas nodrošina to ar faniem un atšķir to no citiem pakalpojumiem.

Šādus produktus parasti sauc par sajūtu produktiem – tādiem, kas jūt savus klientus.
Big Data tehnoloģija tiek izmantota arī automobiļu rūpniecībā. Piemēram, Tesla to dara - viņu jaunākais modelis ir autopilots. Uzņēmums cenšas radīt automašīnu, kas pati nogādās pasažieri tur, kur viņam jādodas. Bez Big Data tas nav iespējams, jo, ja mēs izmantosim tikai tos datus, kurus saņemam tieši, kā to dara cilvēks, tad auto nevarēs uzlaboties.

Kad paši braucam ar automašīnu, mēs izmantojam savus neironus, lai pieņemtu lēmumus, pamatojoties uz daudziem faktoriem, kurus mēs pat nepamanām. Piemēram, mēs varam neapzināties, kāpēc pie zaļās gaismas nolēmām uzreiz nepaātrināt, bet tad izrādās, ka lēmums bija pareizs – jums milzīgā ātrumā pabrauca garām automašīna, un jūs izvairījāties no avārijas.
Varat arī sniegt piemēru Big Data izmantošanai sportā. 2002. gadā Oklendas Athletics beisbola komandas ģenerālmenedžeris Billijs Bīns nolēma lauzt sportistu atlases paradigmu - viņš atlasīja un apmācīja spēlētājus “pēc skaitļiem”.
Parasti menedžeri skatās uz spēlētāju panākumiem, taču šajā gadījumā viss bija savādāk - lai gūtu rezultātus, menedžeris pētīja, kādas sportistu kombinācijas viņam vajadzīgas, pievēršot uzmanību individuālajām īpatnībām. Turklāt viņš izvēlējās sportistus, kuriem pašiem nebija daudz potenciāla, bet komanda kopumā izrādījās tik veiksmīga, ka uzvarēja divdesmit mačos pēc kārtas.

Pēc tam režisors Benets Millers uzņēma šim stāstam veltītu filmu "Cilvēks, kurš visu mainīja" ar Bredu Pitu galvenajā lomā.
Big Data tehnoloģija ir noderīga arī finanšu sektorā. Neviens cilvēks pasaulē nevar patstāvīgi un precīzi noteikt, vai ir vērts kādam dot kredītu. Lai pieņemtu lēmumu, tiek veikta punktu skaitīšana, tas ir, tiek uzbūvēts varbūtības modelis, pēc kura var saprast, vai šis cilvēks naudu atdos vai ne. Turklāt vērtēšana tiek piemērota visos posmos: jūs varat, piemēram, aprēķināt, ka noteiktā brīdī persona pārtrauks maksāt.
Lielie dati ļauj ne tikai pelnīt naudu, bet arī tos ietaupīt. Jo īpaši šī tehnoloģija palīdzēja Vācijas Darba ministrijai samazināt bezdarbnieka pabalstu izmaksas par 10 miljardiem eiro, jo pēc informācijas analīzes kļuva skaidrs, ka 20% pabalstu izmaksāti nepelnīti.
Tehnoloģijas tiek izmantotas arī medicīnā (tas īpaši raksturīgi Izraēlai). Ar Big Data palīdzību jūs varat veikt daudz precīzāku analīzi, nekā to spēj ārsts ar trīsdesmit gadu pieredzi.
Jebkurš ārsts, veicot diagnozi, paļaujas tikai uz savu pašu pieredzi. Kad iekārta to dara, tas izriet no tūkstošiem šādu ārstu pieredzes un visas esošās slimības vēstures. Tas ņem vērā, no kāda materiāla ir izgatavota pacienta māja, kādā teritorijā cietušais dzīvo, kādi dūmi ir utt. Tas ir, tas ņem vērā daudzus faktorus, kurus ārsti neņem vērā.
Lielo datu izmantošanas piemērs veselības aprūpē ir Project Artemis projekts, kuru īstenoja Toronto Bērnu slimnīca. Šis Informācijas sistēma, kas reāllaikā apkopo un analizē datus par mazuļiem. Iekārta ļauj analizēt 1260 katra bērna veselības rādītājus katru sekundi. Šis projekts ir vērsts uz bērna nestabilā stāvokļa prognozēšanu un bērnu slimību profilaksi.
Lielos datus sāk izmantot arī Krievijā: piemēram, Yandex ir lielo datu nodaļa. Uzņēmums kopā ar AstraZeneca un Krievijas Klīniskās onkoloģijas biedrību RUSSCO uzsāka RAY platformu, kas paredzēta ģenētiķiem un molekulārbiologiem. Projekts ļauj pilnveidot metodes vēža diagnosticēšanai un vēža noslieces noteikšanai. Platforma sāks darboties 2016. gada decembrī.
Termins lielie dati parasti attiecas uz jebkādu strukturētu, daļēji strukturētu un nestrukturētu datu apjomu. Taču otro un trešo var un vajag pasūtīt turpmākai informācijas analīzei. Lielie dati nav līdzvērtīgi nevienam faktiskajam apjomam, taču, runājot par Big Data, vairumā gadījumu mēs domājam terabaitus, petabaitus un pat papildu baitus informācijas. Jebkurš uzņēmums var uzkrāt šādu datu apjomu laika gaitā vai gadījumos, kad uzņēmumam ir jāsaņem daudz informācijas, reāllaikā.
Lielo datu analīze
Runājot par lielo datu analīzi, mēs galvenokārt domājam informācijas vākšanu un uzglabāšanu no dažādiem avotiem. Piemēram, dati par pircējiem, kuri veikuši pirkumus, to raksturojums, informācija par palaišanu reklāmas uzņēmumi un tās efektivitātes novērtējums, dati kontaktu centrs. Jā, visu šo informāciju var salīdzināt un analizēt. Tas ir iespējams un nepieciešams. Bet, lai to izdarītu, jums ir jāizveido sistēma, kas ļauj apkopot un pārveidot informāciju, to neizkropļojot, uzglabāt un, visbeidzot, vizualizēt. Piekrītu, ar lieliem datiem tabulas, kas izdrukātas uz vairākiem tūkstošiem lappušu, maz palīdz pieņemt biznesa lēmumus.
1. Lielo datu ienākšana
Lielākajai daļai pakalpojumu, kas apkopo informāciju par lietotāja darbībām, ir iespēja eksportēt. Lai nodrošinātu, ka tie nonāk uzņēmumā strukturētā veidā, tiek izmantotas dažādas sistēmas, piemēram, Alteryx. Šī programmatūra ļauj jums saņemt automātiskais režīms informāciju, apstrādāt to, bet galvenais – pārvērst to par pareizais tips un formāts bez izkropļojumiem.
2. Lielo datu uzglabāšana un apstrāde
Gandrīz vienmēr, vācot lielu informācijas apjomu, rodas problēmas ar tās saglabāšanu. No visām mūsu pētītajām platformām mūsu uzņēmums dod priekšroku Vertica. Atšķirībā no citiem produktiem, Vertica spēj ātri “atdot” tajā saglabāto informāciju. Trūkumi ietver ilgstošu ierakstīšanu, taču, analizējot lielos datus, priekšplānā izvirzās atgriešanās ātrums. Piemēram, ja mēs runājam par apkopošanu, izmantojot informācijas petabaitu, augšupielādes ātrums ir viens no svarīgākajiem parametriem.
3. Lielo datu vizualizācija
Un visbeidzot, liela datu apjoma analīzes trešais posms ir . Lai to izdarītu, nepieciešama platforma, kas var vizuāli atspoguļot visu saņemto informāciju ērtā formā. Mūsuprāt, ar uzdevumu var tikt galā tikai viens programmatūras produkts - Tableau. Noteikti viens no labākajiem šodien risinājums, kas spēj vizuāli parādīt jebkuru informāciju, pārvēršot uzņēmuma darbu trīsdimensiju modelī, apkopojot visu nodaļu darbības vienotā savstarpēji atkarīgā ķēdē (par Tableau iespējām varat lasīt vairāk).
Tā vietā ņemiet vērā, ka gandrīz jebkurš uzņēmums tagad var izveidot savus lielos datus. Lielo datu analīze vairs nav sarežģīts un dārgs process. Uzņēmuma vadībai tagad ir pareizi jāformulē jautājumi savākto informāciju, savukārt neredzamu pelēko laukumu praktiski nav palicis.
Lejupielādēt Tableau