การวิเคราะห์ข้อมูลปริมาณมาก เครื่องบิ๊กดาต้า การปรับขนาดและการจัดระดับ
ขึ้นอยู่กับวัสดุจากการวิจัยและแนวโน้ม
Big Data เป็นที่พูดถึงในวงการไอทีและการตลาดมาหลายปีแล้ว และเป็นที่ชัดเจนว่าเทคโนโลยีดิจิทัลได้แทรกซึมเข้ามาในชีวิต คนทันสมัย, “ทุกสิ่งถูกเขียนไว้” ปริมาณข้อมูลในด้านต่างๆ ของชีวิตมีเพิ่มมากขึ้น และในขณะเดียวกัน ความเป็นไปได้ในการจัดเก็บข้อมูลก็เพิ่มขึ้นด้วย
เทคโนโลยีระดับโลกสำหรับการจัดเก็บข้อมูล
ที่มา: ฮิลเบิร์ตและโลเปซ, `ความสามารถทางเทคโนโลยีของโลกในการจัดเก็บ สื่อสาร และคำนวณข้อมูล'' วิทยาศาสตร์ 2011 ทั่วโลก
ผู้เชี่ยวชาญส่วนใหญ่เห็นพ้องกันว่าการเร่งการเติบโตของข้อมูลนั้นเป็นความจริงตามวัตถุประสงค์ โซเชียลเน็ตเวิร์ก อุปกรณ์มือถือ ข้อมูลจากอุปกรณ์วัด ข้อมูลทางธุรกิจ นี่เป็นเพียงแหล่งข้อมูลไม่กี่ประเภทที่สามารถสร้างข้อมูลจำนวนมหาศาลได้ จากการศึกษาพบว่า ไอดีซีจักรวาลดิจิทัลซึ่งเผยแพร่ในปี 2555 ในอีก 8 ปีข้างหน้า จำนวนข้อมูลในโลกจะสูงถึง 40 ZB (เซตตะไบต์) ซึ่งเทียบเท่ากับ 5,200 GB สำหรับประชากรทุกคนในโลก
การเติบโตของการรวบรวมข้อมูลดิจิทัลในสหรัฐอเมริกา

ที่มา: ไอดีซี
ส่วนสำคัญของข้อมูลไม่ได้ถูกสร้างขึ้นโดยคน แต่โดยหุ่นยนต์ที่มีปฏิสัมพันธ์ทั้งต่อกันและกับเครือข่ายข้อมูลอื่น ๆ เช่น เซ็นเซอร์และ อุปกรณ์อัจฉริยะ. ในอัตราการเติบโตนี้ จำนวนข้อมูลในโลกตามที่นักวิจัยระบุว่าจะเพิ่มขึ้นสองเท่าทุกปี จำนวนเสมือนและ ฟิสิคัลเซิร์ฟเวอร์ในโลกจะเติบโตขึ้นสิบเท่าเนื่องจากการขยายและการสร้างศูนย์ข้อมูลใหม่ ด้วยเหตุนี้ จึงมีความต้องการใช้และสร้างรายได้จากข้อมูลนี้อย่างมีประสิทธิภาพเพิ่มมากขึ้น เนื่องจากการใช้ Big Data ในธุรกิจต้องใช้เงินลงทุนจำนวนมาก คุณจึงต้องเข้าใจสถานการณ์ให้ชัดเจน โดยพื้นฐานแล้ว เป็นเรื่องง่าย: คุณสามารถเพิ่มประสิทธิภาพทางธุรกิจได้โดยการลดต้นทุนและ/หรือเพิ่มปริมาณการขาย
ทำไมเราถึงต้องการข้อมูลขนาดใหญ่?
กระบวนทัศน์ Big Data กำหนดปัญหาหลักสามประเภท
- การจัดเก็บและจัดการข้อมูลหลายร้อยเทราไบต์หรือเพตะไบต์ที่ฐานข้อมูลเชิงสัมพันธ์ทั่วไปไม่สามารถนำมาใช้ได้อย่างมีประสิทธิภาพ
- จัดระเบียบข้อมูลที่ไม่มีโครงสร้างซึ่งประกอบด้วยข้อความ รูปภาพ วิดีโอ และข้อมูลประเภทอื่นๆ
- การวิเคราะห์ข้อมูลขนาดใหญ่ ซึ่งก่อให้เกิดคำถามเกี่ยวกับวิธีการทำงานกับข้อมูลที่ไม่มีโครงสร้าง การสร้างรายงานการวิเคราะห์ ตลอดจนการนำแบบจำลองการคาดการณ์ไปใช้
ตลาดโครงการ Big Data ตัดกับตลาดการวิเคราะห์ธุรกิจ (BA) ซึ่งมีปริมาณทั่วโลกตามที่ผู้เชี่ยวชาญระบุ มีมูลค่าประมาณ 100 พันล้านดอลลาร์ในปี 2555 ประกอบด้วยส่วนประกอบของเทคโนโลยีเครือข่าย เซิร์ฟเวอร์ ซอฟต์แวร์และบริการด้านเทคนิค
นอกจากนี้ การใช้เทคโนโลยี Big Data ยังเกี่ยวข้องกับโซลูชันระดับการประกันรายได้ (RA) ที่ออกแบบมาเพื่อทำให้กิจกรรมของบริษัทเป็นไปโดยอัตโนมัติ ระบบที่ทันสมัยการรับประกันรายได้ประกอบด้วยเครื่องมือในการตรวจจับความไม่สอดคล้องและการวิเคราะห์ข้อมูลเชิงลึก ช่วยให้สามารถตรวจจับความสูญเสียหรือการบิดเบือนข้อมูลที่อาจเกิดขึ้นได้ทันเวลาซึ่งอาจส่งผลให้ผลประกอบการทางการเงินลดลง เมื่อเทียบกับพื้นหลังนี้ บริษัท รัสเซียที่ยืนยันถึงความต้องการเทคโนโลยี Big Data ในตลาดภายในประเทศโปรดทราบว่าปัจจัยที่กระตุ้นการพัฒนา Big Data ในรัสเซียคือการเติบโตของข้อมูลการเร่งการตัดสินใจของฝ่ายบริหารและการปรับปรุงคุณภาพ
สิ่งที่ขัดขวางไม่ให้คุณทำงานกับ Big Data
ปัจจุบันมีการวิเคราะห์ข้อมูลดิจิทัลที่สะสมเพียง 0.5% แม้ว่าจะมีปัญหาทั่วทั้งอุตสาหกรรมที่สามารถแก้ไขได้โดยใช้ โซลูชั่นการวิเคราะห์คลาสข้อมูลขนาดใหญ่ ตลาดไอทีที่พัฒนาแล้วมีผลลัพธ์ที่สามารถใช้เพื่อประเมินความคาดหวังที่เกี่ยวข้องกับการสะสมและการประมวลผลข้อมูลขนาดใหญ่อยู่แล้ว
ปัจจัยหลักประการหนึ่งที่ทำให้การดำเนินโครงการ Big Data ช้าลง นอกเหนือจากต้นทุนที่สูงแล้ว ปัญหาในการเลือกข้อมูลที่ประมวลผล: คือการกำหนดว่าข้อมูลใดจำเป็นต้องดึง จัดเก็บ และวิเคราะห์ และข้อมูลใดควรละเว้น
ตัวแทนธุรกิจจำนวนมากทราบว่าความยากลำบากในการดำเนินโครงการ Big Data นั้นเกี่ยวข้องกับการขาดผู้เชี่ยวชาญ - นักการตลาดและนักวิเคราะห์ ความเร็วของผลตอบแทนจากการลงทุนใน Big Data ขึ้นอยู่กับคุณภาพงานของพนักงานที่มีส่วนร่วมในการวิเคราะห์เชิงลึกและเชิงคาดการณ์โดยตรง ศักยภาพมหาศาลของข้อมูลที่มีอยู่แล้วในองค์กรมักไม่สามารถนำมาใช้อย่างมีประสิทธิภาพโดยนักการตลาดเองได้ เนื่องจากกระบวนการทางธุรกิจที่ล้าสมัยหรือกฎระเบียบภายใน ดังนั้น โครงการ Big Data จึงมักถูกมองว่าเป็นเรื่องยากที่ไม่เพียงแต่จะนำไปใช้เท่านั้น แต่ยังรวมถึงการประเมินผลลัพธ์ด้วย ซึ่งก็คือมูลค่าของข้อมูลที่เก็บรวบรวม ลักษณะเฉพาะของการทำงานกับข้อมูลทำให้นักการตลาดและนักวิเคราะห์ต้องเปลี่ยนความสนใจจากเทคโนโลยีและสร้างรายงานเพื่อแก้ไขปัญหาทางธุรกิจที่เฉพาะเจาะจง
เนื่องจากมีปริมาณมากและ ความเร็วสูงการไหลของข้อมูล กระบวนการรวบรวมข้อมูลเกี่ยวข้องกับขั้นตอน ETL แบบเรียลไทม์ สำหรับการอ้างอิง:อีทีแอล - จากภาษาอังกฤษสารสกัด, แปลง, โหลด- อักษร "การแยก เปลี่ยนรูป โหลด") - หนึ่งในกระบวนการหลักในการจัดการ คลังข้อมูลซึ่งรวมถึง: การดึงข้อมูลจาก แหล่งข้อมูลภายนอกการเปลี่ยนแปลงของพวกเขาและ ทำความสะอาดเพื่อตอบสนองความต้องการ ควรมองว่า ETL ไม่เพียงแต่เป็นกระบวนการในการย้ายข้อมูลจากแอปพลิเคชันหนึ่งไปยังอีกแอปพลิเคชันหนึ่งเท่านั้น แต่ยังเป็นเครื่องมือในการเตรียมข้อมูลสำหรับการวิเคราะห์ด้วย
แล้วประเด็นการรับรองความปลอดภัยของข้อมูลที่มาจากแหล่งภายนอกจะต้องมีแนวทางแก้ไขที่สอดคล้องกับปริมาณข้อมูลที่รวบรวม เนื่องจากวิธีการวิเคราะห์ Big Data กำลังพัฒนาตามการเติบโตของปริมาณข้อมูลเท่านั้น ความสามารถของแพลตฟอร์มการวิเคราะห์ในการใช้วิธีการใหม่ในการเตรียมและรวบรวมข้อมูลจึงมีบทบาทสำคัญ สิ่งนี้ชี้ให้เห็นว่า ตัวอย่างเช่น ข้อมูลเกี่ยวกับผู้ซื้อที่มีศักยภาพหรือคลังข้อมูลขนาดใหญ่ที่มีประวัติการคลิกบนเว็บไซต์ช้อปปิ้งออนไลน์อาจเป็นที่สนใจในการแก้ปัญหาต่างๆ
ความยากลำบากไม่หยุด
แม้จะมีความยากลำบากในการใช้งาน Big Data แต่ธุรกิจก็มุ่งมั่นที่จะเพิ่มการลงทุนในด้านนี้ จากข้อมูลของ Gartner ในปี 2013 นั้น 64% ของบริษัทที่ใหญ่ที่สุดในโลกได้ลงทุนไปแล้วหรือมีแผนที่จะลงทุนในการนำเทคโนโลยี Big Data มาใช้สำหรับธุรกิจของตน ในขณะที่ในปี 2012 มี 58% จากการวิจัยของ Gartner ผู้นำในอุตสาหกรรมที่ลงทุนใน Big Data ได้แก่บริษัทสื่อ โทรคมนาคม ธนาคาร และบริการ ผลลัพธ์ที่ประสบความสำเร็จจากการนำ Big Data ไปใช้นั้นเกิดขึ้นแล้วโดยผู้เล่นหลักหลายรายในอุตสาหกรรมค้าปลีก ในแง่ของการใช้ข้อมูลที่ได้รับโดยใช้เครื่องมือระบุความถี่วิทยุ ระบบลอจิสติกส์ และระบบการย้ายที่ตั้ง การเติมเต็ม- การสะสม การเติมเต็ม - R&T) รวมถึงจากโปรแกรมความภักดี ประสบการณ์การค้าปลีกที่ประสบความสำเร็จส่งเสริมให้ภาคการตลาดอื่นๆ ค้นหาตลาดใหม่ๆ วิธีที่มีประสิทธิภาพการสร้างรายได้จาก Big Data เพื่อเปลี่ยนการวิเคราะห์ให้เป็นทรัพยากรที่เหมาะกับการพัฒนาธุรกิจ ด้วยเหตุนี้ ตามที่ผู้เชี่ยวชาญระบุ ในช่วงจนถึงปี 2020 การลงทุนด้านการจัดการและการจัดเก็บข้อมูลจะลดลงต่อกิกะไบต์ของข้อมูลจาก 2 ดอลลาร์เหลือ 0.2 ดอลลาร์ แต่สำหรับการศึกษาและวิเคราะห์คุณสมบัติทางเทคโนโลยีของ Big Data จะเพิ่มขึ้นเพียง 40%
ต้นทุนแสดงในรูปแบบต่างๆ โครงการลงทุนในด้าน Big Data มีลักษณะที่แตกต่างออกไป รายการต้นทุนขึ้นอยู่กับชนิดของผลิตภัณฑ์ที่ถูกเลือกตามการตัดสินใจบางอย่าง ตามที่ผู้เชี่ยวชาญระบุว่า ต้นทุนที่ใหญ่ที่สุดในโครงการลงทุนนั้นอยู่ที่ผลิตภัณฑ์ที่เกี่ยวข้องกับการรวบรวม การจัดโครงสร้างข้อมูล การทำความสะอาด และการจัดการข้อมูล
มันทำอย่างไร
มีซอฟต์แวร์และชุดค่าผสมมากมาย ฮาร์ดแวร์ซึ่งช่วยให้คุณสร้างได้ โซลูชั่นที่มีประสิทธิภาพ Big Data สำหรับสาขาวิชาธุรกิจต่างๆ จากโซเชียลมีเดีย และ แอปพลิเคชันมือถือ, ก่อน การวิเคราะห์เชิงคาดการณ์และการแสดงข้อมูลทางธุรกิจด้วยภาพ ข้อได้เปรียบที่สำคัญของ Big Data คือความเข้ากันได้ของเครื่องมือใหม่กับฐานข้อมูลที่ใช้กันอย่างแพร่หลายในธุรกิจ ซึ่งมีความสำคัญอย่างยิ่งเมื่อทำงานกับโครงการข้ามสาขาวิชา เช่น การจัดการขายหลายช่องทางและการสนับสนุนลูกค้า
ลำดับการทำงานกับ Big Data ประกอบด้วยการรวบรวมข้อมูล การจัดโครงสร้างข้อมูลที่ได้รับโดยใช้รายงานและแดชบอร์ด การสร้างข้อมูลเชิงลึกและบริบท และการกำหนดคำแนะนำสำหรับการดำเนินการ เนื่องจากการทำงานกับ Big Data เกี่ยวข้องกับค่าใช้จ่ายจำนวนมากในการรวบรวมข้อมูล ซึ่งไม่ทราบผลลัพธ์ของการประมวลผลล่วงหน้า ภารกิจหลักคือการทำความเข้าใจให้ชัดเจนว่าข้อมูลมีไว้เพื่ออะไร และไม่ต้องเข้าใจว่าข้อมูลนั้นมีอยู่มากน้อยเพียงใด ในกรณีนี้ การรวบรวมข้อมูลจะกลายเป็นกระบวนการรับข้อมูลที่จำเป็นสำหรับการแก้ปัญหาเฉพาะโดยเฉพาะ
ตัวอย่างเช่น ผู้ให้บริการโทรคมนาคมรวบรวมข้อมูลจำนวนมหาศาล รวมถึงตำแหน่งทางภูมิศาสตร์ซึ่งมีการอัปเดตอยู่ตลอดเวลา ข้อมูลนี้อาจเป็นผลประโยชน์ทางการค้าสำหรับเอเจนซี่โฆษณาที่อาจใช้เพื่อนำเสนอโฆษณาที่ตรงเป้าหมายและในท้องถิ่น รวมถึงผู้ค้าปลีกและธนาคาร ข้อมูลดังกล่าวสามารถมีบทบาทสำคัญในการตัดสินใจเปิดร้านค้าปลีกในสถานที่หนึ่งโดยอิงจากข้อมูลเกี่ยวกับการมีอยู่ของผู้คนเป้าหมายที่มีประสิทธิภาพ มีตัวอย่างการวัดประสิทธิภาพของการโฆษณาบนป้ายโฆษณากลางแจ้งในลอนดอน ขณะนี้การเข้าถึงของโฆษณาดังกล่าวสามารถวัดได้โดยการวางผู้คนด้วยอุปกรณ์พิเศษใกล้กับโครงสร้างโฆษณาที่นับจำนวนผู้ที่เดินผ่านไปมา เมื่อเปรียบเทียบกับการวัดประสิทธิภาพการโฆษณาประเภทนี้ ผู้ให้บริการมือถือความเป็นไปได้มากขึ้น - เขารู้ตำแหน่งของสมาชิกอย่างแม่นยำ เขารู้ลักษณะทางประชากรศาสตร์ เพศ อายุ สถานภาพสมรส ฯลฯ
จากข้อมูลดังกล่าว ในอนาคตมีโอกาสที่จะเปลี่ยนแปลงเนื้อหาของข้อความโฆษณาโดยใช้การตั้งค่าของบุคคลใดบุคคลหนึ่งที่ผ่านป้ายโฆษณา หากข้อมูลแสดงให้เห็นว่าผู้ที่สัญจรไปมาบ่อย ก็สามารถแสดงโฆษณารีสอร์ทได้ ผู้จัดการแข่งขันฟุตบอลสามารถประมาณจำนวนแฟนบอลเมื่อมาชมการแข่งขันเท่านั้น แต่หากได้มีโอกาสขอจากผู้ดำเนินการแล้ว การสื่อสารเคลื่อนที่ข้อมูลเกี่ยวกับตำแหน่งที่ผู้เข้าชมอยู่หนึ่งชั่วโมง หนึ่งวัน หรือหนึ่งเดือนก่อนการแข่งขัน ซึ่งจะทำให้ผู้จัดงานมีโอกาสวางแผนสถานที่เพื่อโฆษณาการแข่งขันครั้งต่อไป
อีกตัวอย่างหนึ่งคือวิธีที่ธนาคารสามารถใช้ Big Data เพื่อป้องกันการฉ้อโกงได้ หากลูกค้าแจ้งว่าบัตรสูญหายและเมื่อทำการซื้อด้วยบัตร ธนาคารจะเห็นตำแหน่งของโทรศัพท์ของลูกค้าในพื้นที่ทำรายการซื้อแบบเรียลไทม์ ธนาคารสามารถตรวจสอบข้อมูลในใบสมัครของลูกค้าได้ เพื่อดูว่าเขาพยายามจะหลอกลวงเขาหรือไม่ หรือสถานการณ์ตรงกันข้ามเมื่อลูกค้าซื้อสินค้าในร้านค้าธนาคารเห็นว่าบัตรที่ใช้ในการทำธุรกรรมและโทรศัพท์ของลูกค้าอยู่ในที่เดียวกันธนาคารสามารถสรุปได้ว่าเจ้าของบัตรกำลังใช้งานอยู่ ด้วยข้อได้เปรียบของ Big Data ดังกล่าว ขอบเขตของคลังข้อมูลแบบเดิมจึงได้รับการขยายออกไป
เพื่อให้ตัดสินใจใช้โซลูชัน Big Data ได้สำเร็จ บริษัทจำเป็นต้องคำนวณกรณีการลงทุน และทำให้เกิดปัญหาอย่างมากเนื่องจากมีองค์ประกอบที่ไม่รู้จักจำนวนมาก ความขัดแย้งของการวิเคราะห์ในกรณีเช่นนี้คือการทำนายอนาคตโดยอิงจากอดีต ซึ่งข้อมูลที่มักจะขาดหายไป ในกรณีนี้ ปัจจัยสำคัญคือการวางแผนที่ชัดเจนสำหรับการดำเนินการเบื้องต้นของคุณ:
- ขั้นแรกจำเป็นต้องระบุปัญหาทางธุรกิจเฉพาะที่จะใช้เทคโนโลยี Big Data งานนี้จะกลายเป็นแกนหลักในการพิจารณาความถูกต้องของแนวคิดที่เลือก คุณต้องมุ่งเน้นไปที่การรวบรวมข้อมูลที่เกี่ยวข้องกับงานเฉพาะนี้ และในระหว่างการพิสูจน์แนวคิด คุณสามารถใช้เครื่องมือ กระบวนการ และเทคนิคการจัดการต่างๆ ที่จะช่วยให้คุณตัดสินใจโดยมีข้อมูลมากขึ้นในอนาคต
- ประการที่สอง ไม่น่าเป็นไปได้ที่บริษัทที่ไม่มีทักษะและประสบการณ์ในการวิเคราะห์ข้อมูลจะสามารถดำเนินโครงการ Big Data ได้สำเร็จ ความรู้ที่จำเป็นมักมาจากประสบการณ์ด้านการวิเคราะห์ก่อนหน้านี้เสมอ ซึ่งเป็นปัจจัยหลักที่มีอิทธิพลต่อคุณภาพการทำงานกับข้อมูล วัฒนธรรมการใช้ข้อมูลมีบทบาทสำคัญ เนื่องจากบ่อยครั้งที่การวิเคราะห์ข้อมูลจะเปิดเผยออกมา ความจริงอันโหดร้ายเกี่ยวกับธุรกิจ และเพื่อยอมรับความจริงนี้และทำงานร่วมกับมัน จำเป็นต้องมีการพัฒนาวิธีการทำงานกับข้อมูล
- ประการที่สาม คุณค่าของเทคโนโลยี Big Data อยู่ที่การให้ข้อมูลเชิงลึก นักวิเคราะห์ที่ดี ยังขาดแคลนในตลาด พวกเขามักจะเรียกว่าผู้เชี่ยวชาญที่มีความเข้าใจอย่างลึกซึ้งเกี่ยวกับความหมายเชิงพาณิชย์ของข้อมูลและรู้วิธีใช้อย่างถูกต้อง การวิเคราะห์ข้อมูลเป็นวิธีหนึ่งในการบรรลุเป้าหมายทางธุรกิจ และเพื่อเข้าใจคุณค่าของ Big Data คุณต้องประพฤติตามและเข้าใจการกระทำของคุณ ในกรณีนี้ Big Data จะให้ข้อมูลได้มากมาย ข้อมูลที่เป็นประโยชน์เกี่ยวกับผู้บริโภคโดยพิจารณาจากการตัดสินใจที่เป็นประโยชน์ต่อธุรกิจ
แม้ว่าตลาด Big Data ของรัสเซียเพิ่งเริ่มเป็นรูปเป็นร่าง แต่แต่ละโครงการในพื้นที่นี้ก็กำลังได้รับการดำเนินการค่อนข้างประสบความสำเร็จ บางส่วนประสบความสำเร็จในด้านการรวบรวมข้อมูล เช่น โครงการสำหรับ Federal Tax Service และ Tinkoff Credit Systems Bank และอื่นๆ ในแง่ของการวิเคราะห์ข้อมูลและการประยุกต์ใช้ผลลัพธ์ในทางปฏิบัติ นี่คือโครงการ Synqera
Tinkoff Credit Systems Bank ดำเนินโครงการเพื่อใช้แพลตฟอร์ม EMC2 Greenplum ซึ่งเป็นเครื่องมือสำหรับการประมวลผลแบบขนานขนาดใหญ่ ในช่วงไม่กี่ปีที่ผ่านมาธนาคารได้เพิ่มข้อกำหนดด้านความเร็วในการประมวลผลข้อมูลที่สะสมและวิเคราะห์ข้อมูลแบบเรียลไทม์อันเนื่องมาจากจำนวนผู้ใช้บริการที่มีอัตราเติบโตสูง บัตรเครดิต. ธนาคารได้ประกาศแผนการที่จะขยายการใช้เทคโนโลยี Big Data โดยเฉพาะอย่างยิ่งสำหรับการประมวลผลข้อมูลที่ไม่มีโครงสร้างและการทำงานร่วมกับ ข้อมูลองค์กรที่ได้รับจากแหล่งต่างๆ
ขณะนี้ Federal Tax Service ของรัสเซียกำลังสร้างเลเยอร์การวิเคราะห์สำหรับคลังข้อมูลของรัฐบาลกลาง บนพื้นฐานของมันเดียว พื้นที่ข้อมูลและเทคโนโลยีในการเข้าถึงข้อมูลภาษีทางสถิติและ การประมวลผลเชิงวิเคราะห์. ในระหว่างการดำเนินโครงการ งานกำลังดำเนินการเพื่อรวบรวมข้อมูลการวิเคราะห์จากแหล่งข้อมูลมากกว่า 1,200 แห่งในระดับท้องถิ่นของ Federal Tax Service
อีกหนึ่ง ตัวอย่างที่น่าสนใจการวิเคราะห์ข้อมูลขนาดใหญ่แบบเรียลไทม์คือ Synqera สตาร์ทอัพชาวรัสเซีย ซึ่งพัฒนาแพลตฟอร์ม Simplate โซลูชันนี้ขึ้นอยู่กับการประมวลผลข้อมูลจำนวนมาก โดยโปรแกรมจะวิเคราะห์ข้อมูลเกี่ยวกับลูกค้า ประวัติการซื้อ อายุ เพศ และแม้แต่อารมณ์ มีการติดตั้งเคาน์เตอร์ชำระเงินในเครือร้านเครื่องสำอาง หน้าจอสัมผัสพร้อมเซ็นเซอร์ที่จดจำอารมณ์ของลูกค้า โปรแกรมจะกำหนดอารมณ์ของบุคคล วิเคราะห์ข้อมูลเกี่ยวกับเขา กำหนดเวลาของวัน และสแกนฐานข้อมูลส่วนลดของร้านค้า หลังจากนั้นจะส่งข้อความที่ตรงเป้าหมายไปยังผู้ซื้อเกี่ยวกับโปรโมชั่นและ ข้อเสนอพิเศษ. โซลูชันนี้เพิ่มความภักดีของลูกค้าและเพิ่มยอดขายของผู้ค้าปลีก
หากเราพูดถึงกรณีที่ประสบความสำเร็จในต่างประเทศ ประสบการณ์ในการใช้เทคโนโลยี Big Data ในบริษัท Dunkin`Donuts ซึ่งใช้ข้อมูลแบบเรียลไทม์เพื่อขายสินค้าก็น่าสนใจในเรื่องนี้ จอแสดงผลดิจิทัลในร้านค้าเสนอข้อเสนอที่เปลี่ยนแปลงทุกนาที ขึ้นอยู่กับช่วงเวลาของวันและความพร้อมของผลิตภัณฑ์ ด้วยการใช้ใบเสร็จรับเงิน บริษัทจะได้รับข้อมูลว่าข้อเสนอใดได้รับการตอบรับจากลูกค้ามากที่สุด วิธีการประมวลผลข้อมูลนี้ช่วยให้เราเพิ่มผลกำไรและการหมุนเวียนของสินค้าในคลังสินค้าได้
จากประสบการณ์ในการดำเนินโครงการ Big Data แสดงให้เห็นว่าพื้นที่นี้ได้รับการออกแบบมาเพื่อแก้ไขปัญหาทางธุรกิจสมัยใหม่ได้สำเร็จ ในขณะเดียวกัน ปัจจัยสำคัญในการบรรลุเป้าหมายเชิงพาณิชย์เมื่อทำงานกับข้อมูลขนาดใหญ่คือการเลือกกลยุทธ์ที่เหมาะสม ซึ่งรวมถึงการวิเคราะห์ที่ระบุคำขอของผู้บริโภคตลอดจนการใช้งาน เทคโนโลยีที่เป็นนวัตกรรมในด้านบิ๊กดาต้า
จากการสำรวจทั่วโลกที่จัดทำเป็นประจำทุกปีโดย Econsultancy และ Adobe ตั้งแต่ปี 2012 ในกลุ่มนักการตลาดองค์กร พบว่า “ข้อมูลขนาดใหญ่” ที่ระบุลักษณะการกระทำของผู้คนบนอินเทอร์เน็ตสามารถทำอะไรได้มากมาย พวกเขาสามารถเพิ่มประสิทธิภาพกระบวนการทางธุรกิจออฟไลน์ ช่วยให้เข้าใจว่าเจ้าของอุปกรณ์มือถือใช้พวกเขาเพื่อค้นหาข้อมูลอย่างไร หรือเพียง "ทำให้การตลาดดีขึ้น" เช่น มีประสิทธิภาพมากกว่า. นอกจากนี้ฟังก์ชันหลังยังได้รับความนิยมมากขึ้นเรื่อยๆ ทุกปี ดังแผนภาพที่เรานำเสนอ
งานหลักของนักการตลาดอินเทอร์เน็ตในแง่ของลูกค้าสัมพันธ์

แหล่งที่มา: Econsultancy และ Adobe เผยแพร่– emarketer.com
โปรดทราบว่าสัญชาติของผู้ตอบแบบสอบถาม มีความสำคัญอย่างยิ่งไม่ได้มี. จากการสำรวจที่จัดทำโดย KPMG ในปี 2556 พบว่าส่วนแบ่งของ “ผู้มองโลกในแง่ดี” ได้แก่ ผู้ที่ใช้ Big Data ในการพัฒนากลยุทธ์ทางธุรกิจคือ 56% และความแปรผันในแต่ละภูมิภาคมีน้อย: จาก 63% ในประเทศอเมริกาเหนือไปจนถึง 50% ใน EMEA
การใช้ Big Data ในภูมิภาคต่างๆ ของโลก

แหล่งที่มา: KPMG, เผยแพร่แล้ว– emarketer.com
ในขณะเดียวกัน ทัศนคติของนักการตลาดต่อ "เทรนด์แฟชั่น" ดังกล่าวค่อนข้างชวนให้นึกถึงเรื่องตลกที่รู้จักกันดี:
บอกฉันหน่อยวาโนคุณชอบมะเขือเทศไหม?
- ฉันชอบกินแต่ไม่ชอบแบบนี้
แม้ว่านักการตลาดจะ "ชอบ" Big Data ด้วยวาจาและดูเหมือนจะใช้มันด้วยซ้ำ แต่ในความเป็นจริงแล้ว "ทุกอย่างมีความซับซ้อน" ขณะที่พวกเขาเขียนเกี่ยวกับความรักจากใจจริงบนโซเชียลเน็ตเวิร์ก
จากการสำรวจของ Circle Research ในเดือนมกราคม 2014 ในกลุ่มนักการตลาดชาวยุโรป พบว่า 4 ใน 5 ของผู้ตอบแบบสอบถามไม่ได้ใช้ Big Data (แม้ว่าพวกเขาจะ "ชอบมัน" ก็ตาม) เหตุผลแตกต่างกัน มีคนขี้ระแวงที่ไม่คุ้นเคยเพียงไม่กี่คน - 17% และมีจำนวนเท่ากันทุกประการกับสิ่งที่ตรงกันข้ามนั่นคือ ผู้ที่ตอบอย่างมั่นใจ: "ใช่" ที่เหลือก็ลังเลและสงสัย “หนองน้ำ” พวกเขาหลีกเลี่ยงคำตอบโดยตรงโดยใช้ข้ออ้างที่สมเหตุสมผล เช่น “ยังไม่ใช่ แต่เร็วๆ นี้” หรือ “เราจะรอจนกว่าคนอื่นๆ จะเริ่มต้น”
การใช้ Big Data โดยนักการตลาด ยุโรป มกราคม 2014

แหล่งที่มา:ดีเอ็นเอ็กซ์, ที่ตีพิมพ์ -อีมาร์เก็ตเตอร์ดอทคอม
อะไรทำให้พวกเขาสับสน? เรื่องไร้สาระบริสุทธิ์ บางคน (ครึ่งหนึ่ง) ไม่เชื่อข้อมูลนี้ คนอื่นๆ (ซึ่งมีอยู่ไม่น้อย - 55%) พบว่าเป็นการยากที่จะเชื่อมโยงชุด "ข้อมูล" และ "ผู้ใช้" เข้าด้วยกัน บางคนเพียงแต่มี (เพื่อให้ถูกต้องทางการเมือง) ความยุ่งเหยิงภายในองค์กร: ข้อมูลกำลังเดินไปโดยไม่มีใครดูแลระหว่างแผนกการตลาดและโครงสร้างไอที สำหรับคนอื่นๆ ซอฟต์แวร์ไม่สามารถรับมือกับงานหลั่งไหลเข้ามาได้ และอื่นๆ เนื่องจากจำนวนหุ้นทั้งหมดเกิน 100% อย่างมีนัยสำคัญ จึงเป็นที่แน่ชัดว่าสถานการณ์ “อุปสรรคหลายประการ” ไม่ใช่เรื่องแปลก
อุปสรรคในการใช้ Big Data ในด้านการตลาด

แหล่งที่มา:ดีเอ็นเอ็กซ์, ที่ตีพิมพ์ -อีมาร์เก็ตเตอร์ดอทคอม
ดังนั้นเราต้องยอมรับว่า ณ ตอนนี้ “Big Data” ถือเป็นศักยภาพที่ดีที่ยังต้องนำมาใช้ให้เป็นประโยชน์ อย่างไรก็ตาม นี่อาจเป็นสาเหตุที่ Big Data สูญเสียรัศมีของ "เทรนด์แฟชั่น" ดังที่เห็นได้จากการสำรวจที่จัดทำโดยบริษัท Econsultancy ซึ่งเราได้กล่าวไปแล้ว
แนวโน้มที่สำคัญที่สุดของการตลาดดิจิทัลปี 2556-2557

แหล่งที่มา: การให้คำปรึกษาและ Adobe
พวกเขากำลังถูกแทนที่ด้วยราชาองค์อื่น - การตลาดเนื้อหา นานแค่ไหน?
ไม่สามารถพูดได้ว่า Big Data เป็นปรากฏการณ์ใหม่โดยพื้นฐาน แหล่งข้อมูลขนาดใหญ่มีมานานหลายปี เช่น ฐานข้อมูลการซื้อของลูกค้า ประวัติเครดิต ไลฟ์สไตล์ และเป็นเวลาหลายปีที่นักวิทยาศาสตร์ใช้ข้อมูลนี้เพื่อช่วยให้บริษัทต่างๆ ประเมินความเสี่ยงและคาดการณ์ความต้องการของลูกค้าในอนาคต อย่างไรก็ตาม ในปัจจุบันสถานการณ์มีการเปลี่ยนแปลงในสองด้าน:
เครื่องมือและเทคนิคที่ซับซ้อนมากขึ้นได้เกิดขึ้นเพื่อวิเคราะห์และรวมชุดข้อมูลต่างๆ
เครื่องมือวิเคราะห์เหล่านี้ได้รับการเสริมด้วยแหล่งข้อมูลใหม่ๆ มากมายที่ขับเคลื่อนโดยการแปลงข้อมูลเป็นดิจิทัลของวิธีการรวบรวมและการวัดผลเกือบทั้งหมด
ข้อมูลที่มีอยู่หลากหลายเป็นทั้งแรงบันดาลใจและความกังวลสำหรับนักวิจัยที่เติบโตในสภาพแวดล้อมการวิจัยที่มีโครงสร้าง ความรู้สึกของผู้บริโภคถูกจับโดยเว็บไซต์และโซเชียลมีเดียทุกประเภท ความจริงของการดูโฆษณานั้นไม่เพียงถูกบันทึกไว้เท่านั้น กล่องรับสัญญาณแต่ยังใช้แท็กดิจิทัลและ อุปกรณ์เคลื่อนที่กำลังสื่อสารกับทีวี
ข้อมูลพฤติกรรม (เช่น ปริมาณการโทร พฤติกรรมการซื้อ และการซื้อ) มีให้บริการแบบเรียลไทม์แล้ว ดังนั้นสิ่งที่ก่อนหน้านี้ได้รับจากการวิจัยจึงสามารถเรียนรู้ได้โดยใช้แหล่งข้อมูลขนาดใหญ่ และสินทรัพย์ข้อมูลทั้งหมดนี้ถูกสร้างขึ้นอย่างต่อเนื่อง โดยไม่คำนึงถึงกระบวนการวิจัยใดๆ การเปลี่ยนแปลงเหล่านี้ทำให้เราสงสัยว่าข้อมูลขนาดใหญ่สามารถแทนที่การวิจัยตลาดแบบคลาสสิกได้หรือไม่
มันไม่เกี่ยวกับข้อมูล มันเกี่ยวกับคำถามและคำตอบ
ก่อนที่เราจะพบกับความตายสำหรับการวิจัยแบบคลาสสิก เราต้องเตือนตัวเองว่าการมีอยู่ของสินทรัพย์ข้อมูลบางอย่างนั้นไม่ใช่สิ่งสำคัญ แต่เป็นอย่างอื่น อะไรกันแน่? ความสามารถของเราในการตอบคำถามนั่นแหละ เรื่องตลกอย่างหนึ่งเกี่ยวกับโลกใหม่ของ Big Data ก็คือผลลัพธ์ที่ได้จากสินทรัพย์ข้อมูลใหม่ทำให้เกิดคำถามเพิ่มมากขึ้น และคำถามเหล่านี้มักจะได้รับคำตอบที่ดีที่สุดจากการวิจัยแบบดั้งเดิม ดังนั้น เมื่อข้อมูลขนาดใหญ่เติบโตขึ้น เราจะเห็นว่าความพร้อมใช้งานและความต้องการ "ข้อมูลขนาดเล็ก" เพิ่มขึ้นพร้อมๆ กัน ซึ่งสามารถให้คำตอบสำหรับคำถามจากโลกของข้อมูลขนาดใหญ่ได้
พิจารณาสถานการณ์: ผู้ลงโฆษณารายใหญ่ติดตามการเข้าชมร้านค้าและปริมาณการขายแบบเรียลไทม์อย่างต่อเนื่อง วิธีการวิจัยที่มีอยู่ (ซึ่งเราสำรวจผู้ร่วมอภิปรายเกี่ยวกับแรงจูงใจในการซื้อและพฤติกรรม ณ จุดขาย) ช่วยให้เรากำหนดเป้าหมายกลุ่มผู้ซื้อที่เฉพาะเจาะจงได้ดีขึ้น เทคนิคเหล่านี้สามารถขยายให้ครอบคลุมเนื้อหา Big Data ที่หลากหลายขึ้น จนถึงจุดที่ Big Data กลายเป็นวิธีการสังเกตแบบพาสซีฟ และการวิจัยกลายเป็นวิธีการสืบสวนการเปลี่ยนแปลงหรือเหตุการณ์ที่ต้องมีการศึกษาอย่างต่อเนื่องและมุ่งเน้นเฉพาะเจาะจง นี่คือวิธีที่ข้อมูลขนาดใหญ่สามารถค้นคว้าข้อมูลได้อย่างอิสระจากกิจวัตรที่ไม่จำเป็น การวิจัยเบื้องต้นไม่จำเป็นต้องมุ่งเน้นไปที่สิ่งที่เกิดขึ้นอีกต่อไป (ข้อมูลขนาดใหญ่จะทำอย่างนั้น) การวิจัยเบื้องต้นสามารถมุ่งเน้นไปที่การอธิบายว่าทำไมเราจึงสังเกตแนวโน้มหรือการเบี่ยงเบนไปจากแนวโน้ม ผู้วิจัยจะสามารถคิดน้อยลงเกี่ยวกับการรับข้อมูล แต่จะคิดถึงวิธีวิเคราะห์และนำไปใช้มากขึ้น
ในเวลาเดียวกัน เราเห็นว่าข้อมูลขนาดใหญ่สามารถแก้ปัญหาที่ใหญ่ที่สุดประการหนึ่งของเราได้ นั่นก็คือปัญหาการศึกษาที่ใช้เวลานานเกินไป จากการตรวจสอบการศึกษาพบว่าเครื่องมือวิจัยที่สูงเกินไปส่งผลเสียต่อคุณภาพข้อมูล แม้ว่าผู้เชี่ยวชาญหลายคนรับทราบปัญหานี้มานานแล้ว แต่พวกเขาก็ตอบกลับด้วยวลีที่ว่า "แต่ฉันต้องการข้อมูลนี้สำหรับผู้บริหารระดับสูง" และการสัมภาษณ์ที่ยาวนานก็ดำเนินต่อไป
ในโลกของข้อมูลขนาดใหญ่ ซึ่งสามารถรับการวัดเชิงปริมาณได้ผ่านการสังเกตแบบพาสซีฟ ปัญหานี้กลายเป็นประเด็นที่น่าสงสัย ลองคิดถึงการศึกษาวิจัยทั้งหมดนี้เกี่ยวกับการบริโภคกันอีกครั้ง หากข้อมูลขนาดใหญ่ให้ข้อมูลเชิงลึกเกี่ยวกับการบริโภคผ่านการสังเกตแบบเฉยๆ การวิจัยเชิงสำรวจเบื้องต้นก็ไม่จำเป็นต้องรวบรวมข้อมูลประเภทนี้อีกต่อไป และในที่สุดเราก็สามารถสนับสนุนวิสัยทัศน์ของการสำรวจสั้นๆ ด้วยสิ่งที่มากกว่าการคิดปรารถนาได้
Big Data ต้องการความช่วยเหลือจากคุณ
สุดท้ายนี้ “ความใหญ่” เป็นเพียงคุณลักษณะหนึ่งของข้อมูลขนาดใหญ่ ลักษณะ “ใหญ่” หมายถึงขนาดและขนาดของข้อมูล แน่นอนว่านี่เป็นคุณลักษณะหลัก เนื่องจากปริมาณของข้อมูลนี้เกินกว่าที่เราเคยร่วมงานด้วยมาก่อน แต่คุณลักษณะอื่นๆ ของสตรีมข้อมูลใหม่เหล่านี้ก็มีความสำคัญเช่นกัน โดยมักมีรูปแบบที่ไม่ดี ไม่มีโครงสร้าง (หรืออย่างดีที่สุด มีโครงสร้างบางส่วน) และเต็มไปด้วยความไม่แน่นอน การจัดการข้อมูลแขนงใหม่ซึ่งมีชื่อเรียกอย่างเหมาะสมว่าการวิเคราะห์เอนทิตี จะช่วยแก้ปัญหาการตัดเสียงรบกวนในข้อมูลขนาดใหญ่ หน้าที่ของมันคือการวิเคราะห์ชุดข้อมูลเหล่านี้และค้นหาว่าข้อสังเกตใดบ้างที่อ้างอิงถึงบุคคลคนเดียวกัน ข้อสังเกตใดที่เป็นปัจจุบัน และสิ่งใดที่สามารถนำมาใช้ได้
การทำความสะอาดข้อมูลประเภทนี้จำเป็นเพื่อขจัดสัญญาณรบกวนหรือข้อมูลที่ผิดพลาดเมื่อทำงานกับเนื้อหาข้อมูลขนาดใหญ่หรือขนาดเล็ก แต่ยังไม่เพียงพอ เรายังต้องสร้างบริบทเกี่ยวกับสินทรัพย์ข้อมูลขนาดใหญ่ตามประสบการณ์ การวิเคราะห์ และความรู้ด้านหมวดหมู่ก่อนหน้านี้ ในความเป็นจริง นักวิเคราะห์หลายคนชี้ไปที่ความสามารถในการจัดการความไม่แน่นอนที่มีอยู่ในข้อมูลขนาดใหญ่ในฐานะแหล่งที่มาของความได้เปรียบทางการแข่งขัน เนื่องจากช่วยให้ตัดสินใจได้ดีขึ้น
นี่คือจุดที่การวิจัยเบื้องต้นไม่เพียงแต่พบว่าตัวเองได้รับการปลดปล่อยจากข้อมูลขนาดใหญ่เท่านั้น แต่ยังมีส่วนช่วยในการสร้างและวิเคราะห์เนื้อหาภายในข้อมูลขนาดใหญ่อีกด้วย
ตัวอย่างที่สำคัญของเรื่องนี้คือการประยุกต์ใช้กรอบคุณค่าของแบรนด์ที่แตกต่างโดยพื้นฐานกับโซเชียลมีเดีย (เรากำลังพูดถึงการพัฒนาในมิลวาร์ด สีน้ำตาลแนวทางใหม่ในการวัดคุณค่าของแบรนด์ที่ อย่างมีความหมาย แตกต่าง กรอบ– “กระบวนทัศน์ความแตกต่างที่มีความหมาย” -ร & ต ). แบบจำลองนี้ได้รับการทดสอบตามพฤติกรรมภายในตลาดเฉพาะ ใช้งานบนพื้นฐานมาตรฐาน และสามารถนำไปใช้กับการตลาดแนวดิ่งอื่นๆ และระบบข้อมูลสนับสนุนการตัดสินใจ กล่าวอีกนัยหนึ่ง โมเดลมูลค่าแบรนด์ของเราซึ่งได้รับข้อมูลจากการวิจัยแบบสำรวจ (แม้ว่าจะไม่ได้อิงตามเพียงอย่างเดียว) มีคุณสมบัติทั้งหมดที่จำเป็นในการเอาชนะธรรมชาติของข้อมูลขนาดใหญ่ที่ไม่มีโครงสร้าง ไม่ปะติดปะต่อ และไม่แน่นอน
พิจารณาข้อมูลความเชื่อมั่นของผู้บริโภคที่ได้รับจากโซเชียลมีเดีย ในรูปแบบดิบ จุดสูงสุดและจุดต่ำสุดของความเชื่อมั่นของผู้บริโภคมักมีความสัมพันธ์น้อยที่สุดกับการวัดมูลค่าและพฤติกรรมของแบรนด์แบบออฟไลน์ กล่าวคือ ข้อมูลมีสัญญาณรบกวนมากเกินไป แต่เราสามารถลดสิ่งรบกวนนี้ได้โดยการนำโมเดลความหมายของผู้บริโภค การสร้างความแตกต่างของแบรนด์ ไดนามิก และความโดดเด่นมาใช้กับข้อมูลความรู้สึกของผู้บริโภคแบบดิบ ซึ่งเป็นวิธีการประมวลผลและรวบรวมข้อมูลโซเชียลมีเดียตามมิติเหล่านี้
เมื่อข้อมูลได้รับการจัดระเบียบตามกรอบงานของเรา แนวโน้มที่ระบุมักจะสอดคล้องกับคุณค่าของแบรนด์ออฟไลน์และการวัดผลทางพฤติกรรม โดยพื้นฐานแล้ว ข้อมูลโซเชียลมีเดียไม่สามารถพูดเพื่อตัวเองได้ หากต้องการใช้สิ่งเหล่านี้เพื่อจุดประสงค์นี้ต้องอาศัยประสบการณ์และแบบจำลองของเราที่สร้างขึ้นจากแบรนด์ต่างๆ เมื่อโซเชียลมีเดียให้ข้อมูลที่เป็นเอกลักษณ์แก่เราซึ่งแสดงในภาษาที่ผู้บริโภคใช้เพื่ออธิบายแบรนด์ เราต้องใช้ภาษานั้นเมื่อสร้างงานวิจัยของเราเพื่อทำให้การวิจัยเบื้องต้นมีประสิทธิภาพมากขึ้น
ประโยชน์ของการวิจัยที่ได้รับการยกเว้น
สิ่งนี้ทำให้เราย้อนกลับไปดูว่าข้อมูลขนาดใหญ่ไม่ได้เข้ามาแทนที่การวิจัยมากนักและเป็นการปลดปล่อยข้อมูลดังกล่าว นักวิจัยจะไม่ต้องสร้างการศึกษาใหม่สำหรับแต่ละกรณีใหม่ สินทรัพย์ข้อมูลขนาดใหญ่ที่เพิ่มมากขึ้นเรื่อยๆ สามารถใช้กับหัวข้อการวิจัยต่างๆ ได้ ช่วยให้การวิจัยเบื้องต้นที่ตามมาสามารถเจาะลึกเข้าไปในหัวข้อและเติมเต็มช่องว่างที่มีอยู่ได้ นักวิจัยจะไม่ต้องพึ่งพาการสำรวจที่สูงเกินจริงอีกต่อไป แต่สามารถใช้แบบสำรวจสั้นๆ และมุ่งเน้นไปที่พารามิเตอร์ที่สำคัญที่สุด ซึ่งจะช่วยปรับปรุงคุณภาพของข้อมูลแทน
ด้วยการปลดปล่อยนี้ นักวิจัยจะสามารถใช้หลักการและแนวคิดที่กำหนดไว้เพื่อเพิ่มความแม่นยำและความหมายให้กับสินทรัพย์ข้อมูลขนาดใหญ่ ซึ่งนำไปสู่พื้นที่ใหม่สำหรับการวิจัยเชิงสำรวจ วงจรนี้ควรนำไปสู่ความเข้าใจที่มากขึ้นในประเด็นเชิงกลยุทธ์ต่างๆ และท้ายที่สุดคือการก้าวไปสู่สิ่งที่ควรเป็นเป้าหมายหลักของเราเสมอมา นั่นคือการแจ้งและปรับปรุงคุณภาพของการตัดสินใจด้านแบรนด์และการสื่อสาร
โดยปกติแล้ว เมื่อพวกเขาพูดถึงการประมวลผลเชิงวิเคราะห์ที่จริงจัง โดยเฉพาะอย่างยิ่งหากพวกเขาใช้คำว่า Data Mining นั่นหมายความว่ามีข้อมูลจำนวนมหาศาล โดยทั่วไปไม่เป็นเช่นนั้น เนื่องจากคุณต้องประมวลผลชุดข้อมูลขนาดเล็กบ่อยครั้ง และการค้นหารูปแบบในชุดข้อมูลเหล่านั้นก็ไม่ง่ายไปกว่าการบันทึกหลายร้อยล้านรายการ แม้ว่าไม่ต้องสงสัยเลยว่าความจำเป็นในการค้นหารูปแบบในฐานข้อมูลขนาดใหญ่ทำให้การวิเคราะห์ที่ไม่สำคัญอยู่แล้วมีความซับซ้อน
สถานการณ์นี้เป็นเรื่องปกติโดยเฉพาะอย่างยิ่งสำหรับธุรกิจที่เกี่ยวข้องกับ การค้าปลีก,โทรคมนาคม,ธนาคาร,อินเตอร์เน็ต ฐานข้อมูลของพวกเขารวบรวมข้อมูลจำนวนมากที่เกี่ยวข้องกับธุรกรรม: เช็ค การชำระเงิน การโทร บันทึก ฯลฯ
ไม่มีวิธีการวิเคราะห์หรืออัลกอริธึมที่เป็นสากลที่เหมาะสมสำหรับทุกกรณีและข้อมูลจำนวนเท่าใดก็ได้ วิธีการวิเคราะห์ข้อมูลมีความแตกต่างกันอย่างมากในด้านประสิทธิภาพ คุณภาพของผลลัพธ์ ความง่ายในการใช้งาน และข้อกำหนดด้านข้อมูล การเพิ่มประสิทธิภาพสามารถดำเนินการได้ในหลายระดับ: อุปกรณ์ ฐานข้อมูล แพลตฟอร์มการวิเคราะห์ การเตรียมข้อมูลเบื้องต้น อัลกอริธึมเฉพาะทาง การวิเคราะห์ข้อมูลจำนวนมากต้องใช้แนวทางพิเศษ เนื่องจาก... เป็นเรื่องยากทางเทคนิคที่จะประมวลผลโดยใช้เพียง " กำลังดุร้าย"นั่นคือการใช้อุปกรณ์ที่ทรงพลังมากขึ้น
แน่นอนว่าเป็นไปได้ที่จะเพิ่มความเร็วในการประมวลผลข้อมูลเนื่องจากฮาร์ดแวร์ที่มีประสิทธิภาพมากขึ้น โดยเฉพาะอย่างยิ่งเมื่อเซิร์ฟเวอร์และเวิร์กสเตชันสมัยใหม่ใช้โปรเซสเซอร์แบบมัลติคอร์ แกะขนาดที่สำคัญและทรงพลัง ดิสก์อาร์เรย์. อย่างไรก็ตาม มีวิธีอื่นๆ อีกหลายวิธีในการประมวลผลข้อมูลจำนวนมากที่ช่วยเพิ่มความสามารถในการปรับขนาดและไม่จำเป็นต้องใช้ การต่ออายุที่ไม่มีที่สิ้นสุดอุปกรณ์.
ความสามารถของ DBMS
ฐานข้อมูลสมัยใหม่ประกอบด้วยกลไกต่าง ๆ ซึ่งการใช้งานจะช่วยเพิ่มความเร็วของการประมวลผลเชิงวิเคราะห์ได้อย่างมาก:
- การคำนวณข้อมูลเบื้องต้น ข้อมูลที่ใช้บ่อยที่สุดสำหรับการวิเคราะห์สามารถคำนวณล่วงหน้าได้ (เช่น ในเวลากลางคืน) และจัดเก็บไว้ในรูปแบบที่เตรียมไว้สำหรับการประมวลผลบนเซิร์ฟเวอร์ฐานข้อมูลในรูปแบบของคิวบ์หลายมิติ มุมมองที่เป็นรูปธรรม และตารางพิเศษ
- แคชตารางลงใน RAM ข้อมูลที่ใช้พื้นที่น้อยแต่มักเข้าถึงได้ในระหว่างกระบวนการวิเคราะห์ เช่น ไดเร็กทอรี สามารถแคชลงใน RAM โดยใช้เครื่องมือฐานข้อมูล ซึ่งจะช่วยลดการเรียกไปยังระบบย่อยของดิสก์ที่ช้ากว่าหลายครั้ง
- การแบ่งพาร์ติชันตารางออกเป็นพาร์ติชันและพื้นที่ตาราง คุณสามารถวางข้อมูล ดัชนี และตารางเสริมบนดิสก์ที่แยกจากกัน ซึ่งจะช่วยให้ DBMS สามารถอ่านและเขียนข้อมูลลงดิสก์แบบขนานได้ นอกจากนี้ตารางยังสามารถแบ่งออกเป็นพาร์ติชั่นเพื่อให้มีการดำเนินการดิสก์จำนวนขั้นต่ำเมื่อเข้าถึงข้อมูล ตัวอย่างเช่น หากเราวิเคราะห์ข้อมูลในเดือนที่ผ่านมาบ่อยที่สุด เราก็สามารถใช้ตารางเดียวกับข้อมูลประวัติได้อย่างสมเหตุสมผล แต่จะแยกออกเป็นหลายพาร์ติชั่น เพื่อให้เมื่อเข้าถึงข้อมูลรายเดือน พาร์ติชั่นขนาดเล็กจะถูกอ่านและไม่มีการเข้าถึง ไปยังข้อมูลทางประวัติศาสตร์ทั้งหมด
นี่เป็นเพียงส่วนหนึ่งของความสามารถที่ DBMS สมัยใหม่มีให้เท่านั้น คุณสามารถเพิ่มความเร็วในการดึงข้อมูลจากฐานข้อมูลได้หลายวิธี: การจัดทำดัชนีอย่างมีเหตุผล การสร้างแผนการสืบค้น การประมวลผลคำสั่ง SQL แบบขนาน การใช้คลัสเตอร์ การเตรียมข้อมูลที่วิเคราะห์โดยใช้ขั้นตอนการจัดเก็บและทริกเกอร์ที่ด้านข้างของเซิร์ฟเวอร์ฐานข้อมูล ฯลฯ . ยิ่งไปกว่านั้น กลไกหลายอย่างเหล่านี้สามารถใช้งานได้ไม่เพียงแต่กับ DBMS ที่ "หนัก" เท่านั้น แต่ยังสามารถใช้ได้อีกด้วย ฐานข้อมูลฟรีข้อมูล.
การผสมผสานโมเดล
ความเป็นไปได้ในการเพิ่มความเร็วไม่ได้จำกัดอยู่ที่การปรับประสิทธิภาพของฐานข้อมูลให้เหมาะสม สามารถทำได้หลายอย่างโดยการรวมโมเดลต่างๆ เข้าด้วยกัน เป็นที่ทราบกันดีว่าความเร็วในการประมวลผลมีความสัมพันธ์อย่างมากกับความซับซ้อนของอุปกรณ์ทางคณิตศาสตร์ที่ใช้ ยิ่งใช้กลไกการวิเคราะห์ที่ง่ายกว่า การวิเคราะห์ข้อมูลก็จะยิ่งเร็วขึ้นเท่านั้น
เป็นไปได้ที่จะสร้างสถานการณ์การประมวลผลข้อมูลในลักษณะที่ข้อมูลถูก "เรียกใช้" ผ่านตะแกรงของแบบจำลอง แนวคิดง่ายๆ นำไปใช้ได้ที่นี่: อย่าเสียเวลาไปกับการประมวลผลสิ่งที่คุณไม่จำเป็นต้องวิเคราะห์
อัลกอริธึมที่ง่ายที่สุดจะถูกใช้ก่อน ส่วนหนึ่งของข้อมูลที่สามารถประมวลผลได้โดยใช้อัลกอริธึมดังกล่าวและไม่มีประโยชน์ในการประมวลผลโดยใช้มากขึ้น วิธีการที่ซับซ้อนได้รับการวิเคราะห์และแยกออกจากการประมวลผลเพิ่มเติม ข้อมูลที่เหลือจะถูกถ่ายโอนไปยังขั้นตอนการประมวลผลถัดไป ซึ่งใช้อัลกอริธึมที่ซับซ้อนมากขึ้น และอื่นๆ ตามลำดับ ที่โหนดสุดท้ายของสคริปต์การประมวลผล จะใช้อัลกอริธึมที่ซับซ้อนที่สุด แต่ปริมาณของข้อมูลที่วิเคราะห์จะน้อยกว่าตัวอย่างเริ่มต้นหลายเท่า เป็นผลให้เวลารวมที่ต้องใช้ในการประมวลผลข้อมูลทั้งหมดลดลงตามลำดับความสำคัญ
ให้กันเถอะ ตัวอย่างการปฏิบัติโดยใช้แนวทางนี้ เมื่อแก้ไขปัญหาการคาดการณ์ความต้องการ ขอแนะนำให้ทำการวิเคราะห์ XYZ ในตอนแรก ซึ่งช่วยให้คุณระบุได้ว่าความต้องการสินค้าต่างๆ มีเสถียรภาพเพียงใด ผลิตภัณฑ์ของกลุ่ม X มีการขายค่อนข้างสม่ำเสมอ ดังนั้นการใช้อัลกอริธึมการคาดการณ์ทำให้เราได้รับการคาดการณ์คุณภาพสูง ผลิตภัณฑ์ของกลุ่ม Y ขายได้น้อยลงบางทีอาจคุ้มค่าที่จะสร้างแบบจำลองสำหรับพวกเขาไม่ใช่สำหรับแต่ละบทความ แต่สำหรับกลุ่มซึ่งจะช่วยให้คุณปรับอนุกรมเวลาให้ราบรื่นและตรวจสอบการทำงานของอัลกอริธึมการคาดการณ์ ผลิตภัณฑ์ของกลุ่ม Z ขายอย่างวุ่นวายดังนั้นจึงไม่จำเป็นต้องสร้างแบบจำลองการคาดการณ์สำหรับผลิตภัณฑ์เหล่านี้เลย ความจำเป็นสำหรับผลิตภัณฑ์เหล่านี้ควรคำนวณตามสูตรง่าย ๆ เช่น ยอดขายเฉลี่ยต่อเดือน
ตามสถิติประมาณ 70% ของการแบ่งประเภทประกอบด้วยผลิตภัณฑ์จากกลุ่ม Z อีกประมาณ 25% เป็นผลิตภัณฑ์จากกลุ่ม Y และเพียงประมาณ 5% เท่านั้นเป็นผลิตภัณฑ์จากกลุ่ม X ดังนั้นการก่อสร้างและการใช้แบบจำลองที่ซับซ้อนจึงมีความเกี่ยวข้อง สูงสุด 30% ของผลิตภัณฑ์ ดังนั้นการใช้วิธีการที่อธิบายไว้ข้างต้นจะช่วยลดเวลาในการวิเคราะห์และคาดการณ์ได้ 5-10 เท่า
การประมวลผลแบบขนาน
กลยุทธ์ที่มีประสิทธิภาพอีกประการหนึ่งสำหรับการประมวลผลข้อมูลจำนวนมากคือการแบ่งข้อมูลออกเป็นส่วนๆ และสร้างแบบจำลองสำหรับแต่ละส่วนแยกกัน จากนั้นจึงรวมผลลัพธ์เข้าด้วยกัน บ่อยครั้งที่ข้อมูลจำนวนมากสามารถระบุชุดย่อยหลายชุดที่แตกต่างกันได้ ตัวอย่างเช่น กลุ่มลูกค้า ผลิตภัณฑ์ที่มีลักษณะคล้ายกันและแนะนำให้สร้างแบบจำลองหนึ่งรายการ
ในกรณีนี้ แทนที่จะสร้างโมเดลที่ซับซ้อนเพียงโมเดลเดียวสำหรับทุกคน คุณสามารถสร้างโมเดลง่ายๆ หลายโมเดลสำหรับแต่ละเซ็กเมนต์ได้ วิธีการนี้ช่วยให้คุณเพิ่มความเร็วในการวิเคราะห์และลดความต้องการหน่วยความจำโดยการประมวลผลข้อมูลจำนวนน้อยลงในการส่งผ่านครั้งเดียว นอกจากนี้ ในกรณีนี้ การประมวลผลเชิงวิเคราะห์สามารถดำเนินการแบบขนานได้ ซึ่งส่งผลดีต่อเวลาที่ใช้ด้วย นอกจากนี้ นักวิเคราะห์ที่แตกต่างกันสามารถสร้างแบบจำลองสำหรับแต่ละส่วนได้
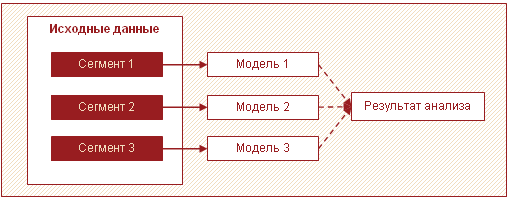
นอกเหนือจากการเพิ่มความเร็วแล้ว วิธีการนี้ยังมีข้อได้เปรียบที่สำคัญอีกประการหนึ่ง - โมเดลที่ค่อนข้างเรียบง่ายหลายรุ่นแยกกันนั้นสามารถสร้างและบำรุงรักษาได้ง่ายกว่ารุ่นใหญ่ คุณสามารถรันโมเดลเป็นขั้นๆ ได้ ดังนั้นจึงได้รับผลลัพธ์แรกในเวลาที่สั้นที่สุดเท่าที่จะเป็นไปได้
ตัวอย่างตัวแทน
หากมีข้อมูลจำนวนมาก ข้อมูลบางอย่างอาจไม่สามารถนำมาใช้ในการสร้างแบบจำลองได้ แต่จะใช้ชุดย่อยบางชุด - เป็นตัวอย่างที่เป็นตัวแทนได้ ตัวอย่างตัวแทนที่จัดเตรียมอย่างถูกต้องประกอบด้วยข้อมูลที่จำเป็นในการสร้างแบบจำลองคุณภาพสูง
กระบวนการประมวลผลเชิงวิเคราะห์แบ่งออกเป็น 2 ส่วน คือ การสร้างแบบจำลองและการประยุกต์ใช้แบบจำลองที่สร้างขึ้นกับข้อมูลใหม่ การสร้างแบบจำลองที่ซับซ้อนเป็นกระบวนการที่ต้องใช้ทรัพยากรมาก ขึ้นอยู่กับอัลกอริธึมที่ใช้ ข้อมูลจะถูกแคช สแกนหลายพันครั้ง คำนวณพารามิเตอร์เสริมจำนวนมาก ฯลฯ การใช้แบบจำลองที่สร้างไว้แล้วกับข้อมูลใหม่ต้องใช้ทรัพยากรน้อยลงหลายสิบเท่า บ่อยครั้งสิ่งนี้เกิดขึ้นจากการคำนวณฟังก์ชันง่ายๆ บางอย่าง
ดังนั้น หากแบบจำลองถูกสร้างขึ้นบนชุดที่ค่อนข้างเล็กและนำไปใช้กับชุดข้อมูลทั้งหมดในเวลาต่อมา เวลาเพื่อให้ได้ผลลัพธ์จะลดลงตามลำดับความสำคัญ เมื่อเทียบกับความพยายามในการประมวลผลชุดข้อมูลที่มีอยู่ทั้งหมดอย่างสมบูรณ์

เพื่อให้ได้ตัวอย่างที่เป็นตัวแทน มีวิธีพิเศษ เช่น การสุ่มตัวอย่าง การใช้งานทำให้สามารถเพิ่มความเร็วของการประมวลผลเชิงวิเคราะห์ได้โดยไม่กระทบต่อคุณภาพของการวิเคราะห์
สรุป
วิธีการที่อธิบายไว้เป็นเพียงส่วนเล็กๆ ของวิธีการที่ช่วยให้คุณสามารถวิเคราะห์ข้อมูลจำนวนมหาศาลได้ มีวิธีการอื่นๆ เช่น การใช้อัลกอริธึมพิเศษที่ปรับขนาดได้ แบบจำลองลำดับชั้น การเรียนรู้ผ่านหน้าต่าง เป็นต้น
การวิเคราะห์ ฐานขนาดใหญ่การจัดการข้อมูลเป็นงานที่ไม่สำคัญ ซึ่งในกรณีส่วนใหญ่ไม่สามารถแก้ไขได้โดยตรง แต่ฐานข้อมูลและแพลตฟอร์มการวิเคราะห์สมัยใหม่เสนอวิธีการมากมายในการแก้ปัญหานี้ เมื่อใช้อย่างชาญฉลาด ระบบจะสามารถประมวลผลข้อมูลหลายเทราไบต์ด้วยความเร็วที่ยอมรับได้
คอลัมน์โดยครู HSE เกี่ยวกับมายาคติและกรณีต่างๆ ของการทำงานกับข้อมูลขนาดใหญ่
ไปที่บุ๊กมาร์ก
ครูที่ School of New Media ที่ National Research University Higher School of Economics Konstantin Romanov และ Alexander Pyatigorsky ซึ่งเป็นผู้อำนวยการด้านการเปลี่ยนแปลงทางดิจิทัลที่ Beeline ได้เขียนคอลัมน์สำหรับเว็บไซต์เกี่ยวกับความเข้าใจผิดหลักเกี่ยวกับ Big Data - ตัวอย่างการใช้งาน เทคโนโลยีและเครื่องมือ ผู้เขียนแนะนำว่าสิ่งพิมพ์จะช่วยให้ผู้จัดการบริษัทเข้าใจแนวคิดนี้
ตำนานและความเข้าใจผิดเกี่ยวกับ Big Data
Big Data ไม่ใช่การตลาด
คำว่า Big Data กลายเป็นคำที่ทันสมัยมาก โดยถูกใช้ในสถานการณ์นับล้านและมีการตีความที่แตกต่างกันหลายร้อยแบบ ซึ่งมักไม่เกี่ยวข้องกับสิ่งที่เป็นอยู่ แนวคิดมักถูกแทนที่ในหัวของผู้คน และ Big Data ก็สับสนกับผลิตภัณฑ์ทางการตลาด นอกจากนี้ในบางบริษัท Big Data ยังเป็นส่วนหนึ่งของแผนกการตลาดอีกด้วย ผลลัพธ์ของการวิเคราะห์ข้อมูลขนาดใหญ่สามารถเป็นแหล่งกิจกรรมทางการตลาดได้อย่างแน่นอน แต่ไม่มีอะไรมากไปกว่านั้น มาดูกันว่ามันทำงานอย่างไร
หากเราระบุรายชื่อผู้ที่ซื้อสินค้าที่มีมูลค่ามากกว่าสามพันรูเบิลในร้านของเราเมื่อสองเดือนที่แล้วแล้วส่งข้อเสนอบางอย่างให้กับผู้ใช้เหล่านี้แสดงว่านี่คือการตลาดโดยทั่วไป เราได้รูปแบบที่ชัดเจนจากข้อมูลเชิงโครงสร้างและใช้เพื่อเพิ่มยอดขาย
อย่างไรก็ตาม หากเรารวมข้อมูล CRM เข้ากับข้อมูลสตรีมมิ่งจาก เช่น Instagram แล้ววิเคราะห์ เราจะพบรูปแบบ: บุคคลที่ลดกิจกรรมของเขาในเย็นวันพุธและมีรูปถ่ายล่าสุดแสดงให้เห็นว่าลูกแมวควรยื่นข้อเสนอบางอย่าง นี่จะเป็น Big Data อยู่แล้ว เราพบตัวกระตุ้น ส่งต่อไปยังนักการตลาด และพวกเขาใช้มันเพื่อจุดประสงค์ของตนเอง
จากนี้ไปเทคโนโลยีมักจะทำงานกับข้อมูลที่ไม่มีโครงสร้าง และแม้ว่าข้อมูลจะมีโครงสร้างแล้ว ระบบก็ยังคงมองหารูปแบบที่ซ่อนอยู่ในข้อมูลนั้นต่อไป ซึ่งการตลาดไม่ได้ทำ
Big Data ไม่ใช่ไอที
สุดขั้วที่สองของเรื่องนี้: Big Data มักจะสับสนกับไอที นี่เป็นเพราะความจริงที่ว่าใน บริษัท รัสเซียตามกฎแล้ว ผู้เชี่ยวชาญด้านไอทีเป็นผู้ขับเคลื่อนเทคโนโลยีทั้งหมด รวมถึงข้อมูลขนาดใหญ่ด้วย ดังนั้นหากทุกอย่างเกิดขึ้นในแผนกนี้ บริษัทโดยรวมจะรู้สึกว่านี่คือกิจกรรมไอทีบางประเภท
ในความเป็นจริงมีความแตกต่างพื้นฐานอยู่ที่นี่: Big Data เป็นกิจกรรมที่มุ่งเพื่อให้ได้มาซึ่งผลิตภัณฑ์เฉพาะซึ่งไม่เกี่ยวข้องกับไอทีเลย แม้ว่าเทคโนโลยีจะไม่สามารถดำรงอยู่ได้หากไม่มีมันก็ตาม
Big Data ไม่ใช่การรวบรวมและวิเคราะห์ข้อมูลเสมอไป
มีความเข้าใจผิดเกี่ยวกับ Big Data อีกประการหนึ่ง ทุกคนเข้าใจดีว่าเทคโนโลยีนี้เกี่ยวข้องกับข้อมูลจำนวนมาก แต่ประเภทของข้อมูลนั้นไม่ได้ชัดเจนเสมอไป ทุกคนสามารถรวบรวมและใช้ข้อมูลได้ ตอนนี้สิ่งนี้เป็นไปได้ไม่เพียงแต่ในภาพยนตร์เกี่ยวกับ แต่ยังรวมถึงในบริษัทเล็กๆ อีกด้วย คำถามเดียวคือต้องรวบรวมอะไรและจะใช้อย่างไรให้เป็นประโยชน์
แต่ก็ควรจะเข้าใจว่า เทคโนโลยีที่ยิ่งใหญ่ข้อมูลจะไม่ใช่การรวบรวมและวิเคราะห์ข้อมูลใดๆ อย่างแน่นอน ตัวอย่างเช่น หากคุณรวบรวมข้อมูลเกี่ยวกับบุคคลใดบุคคลหนึ่งบนโซเชียลเน็ตเวิร์ก ก็จะไม่ใช่ Big Data
Big Data แท้จริงแล้วคืออะไร?
Big Data ประกอบด้วยสามองค์ประกอบ:
- ข้อมูล;
- การวิเคราะห์;
- เทคโนโลยี
Big Data ไม่ได้เป็นเพียงองค์ประกอบหนึ่งเท่านั้น แต่ยังเป็นการผสมผสานองค์ประกอบทั้งสามเข้าด้วยกัน ผู้คนมักจะแทนที่แนวคิด: บางคนเชื่อว่า Big Data เป็นเพียงข้อมูล บางคนเชื่อว่ามันเป็นเทคโนโลยี แต่ในความเป็นจริง ไม่ว่าคุณจะรวบรวมข้อมูลได้มากเพียงใด คุณก็ไม่สามารถทำอะไรกับมันได้หากไม่มี เทคโนโลยีที่จำเป็นและนักวิเคราะห์ หากมีการวิเคราะห์ที่ดี แต่ไม่มีข้อมูล ก็จะยิ่งแย่ลงไปอีก
ถ้าเราพูดถึงข้อมูล นี่ไม่ใช่แค่ข้อความเท่านั้น แต่ยังรวมถึงรูปภาพทั้งหมดที่โพสต์บน Instagram และโดยทั่วไปทุกอย่างที่สามารถวิเคราะห์และใช้เพื่อวัตถุประสงค์และงานที่แตกต่างกัน กล่าวอีกนัยหนึ่ง Data หมายถึงข้อมูลภายในและภายนอกจำนวนมหาศาลของโครงสร้างต่างๆ
การวิเคราะห์ก็เป็นสิ่งจำเป็นเช่นกัน เพราะหน้าที่ของ Big Data คือการสร้างรูปแบบบางอย่าง นั่นคือการวิเคราะห์คือการระบุการพึ่งพาที่ซ่อนอยู่และการค้นหาคำถามและคำตอบใหม่โดยอิงจากการวิเคราะห์ปริมาณข้อมูลที่แตกต่างกันทั้งหมด ยิ่งไปกว่านั้น Big Data ยังก่อให้เกิดคำถามที่ไม่สามารถได้มาจากข้อมูลนี้โดยตรง
เมื่อพูดถึงรูปภาพ การที่คุณโพสต์รูปถ่ายของตัวเองที่สวมเสื้อยืดสีน้ำเงินไม่ได้มีความหมายอะไรเลย แต่ถ้าคุณใช้การถ่ายภาพสำหรับการสร้างแบบจำลอง Big Data อาจกลายเป็นว่าตอนนี้คุณควรเสนอเงินกู้เพราะพฤติกรรมดังกล่าวในกลุ่มโซเชียลของคุณบ่งบอกถึงปรากฏการณ์บางอย่างในการดำเนินการ ดังนั้นข้อมูลที่ “เปล่า” ที่ไม่มีการวิเคราะห์ โดยไม่ระบุการพึ่งพาที่ซ่อนอยู่และไม่ชัดเจนจึงไม่ใช่ Big Data
ดังนั้นเราจึงมีข้อมูลขนาดใหญ่ อาร์เรย์ของพวกเขามีขนาดใหญ่มาก เรามีนักวิเคราะห์ด้วย แต่เราจะแน่ใจได้อย่างไรว่าจากข้อมูลดิบนี้ เราจะสามารถหาวิธีแก้ปัญหาเฉพาะได้ ในการทำเช่นนี้ เราจำเป็นต้องมีเทคโนโลยีที่ไม่เพียงแต่ช่วยให้เราจัดเก็บสิ่งเหล่านั้นได้ (และเมื่อก่อนนี้เป็นไปไม่ได้เลย) แต่ยังวิเคราะห์ได้ด้วย
พูดง่ายๆ ก็คือ หากคุณมีข้อมูลจำนวนมาก คุณจะต้องมีเทคโนโลยี เช่น Hadoop ซึ่งทำให้สามารถจัดเก็บข้อมูลทั้งหมดในรูปแบบดั้งเดิมเพื่อการวิเคราะห์ในภายหลัง เทคโนโลยีประเภทนี้เกิดขึ้นในยักษ์ใหญ่อินเทอร์เน็ต เนื่องจากพวกเขาเป็นคนแรกที่ประสบปัญหาในการจัดเก็บข้อมูลจำนวนมากและวิเคราะห์เพื่อสร้างรายได้ในภายหลัง
นอกจากเครื่องมือสำหรับการจัดเก็บข้อมูลที่ได้รับการปรับปรุงและราคาถูกแล้ว คุณต้องมีเครื่องมือวิเคราะห์ รวมถึงส่วนเสริมสำหรับแพลตฟอร์มที่ใช้ ตัวอย่างเช่น ระบบนิเวศทั้งหมดของโครงการและเทคโนโลยีที่เกี่ยวข้องได้ก่อตัวขึ้นรอบๆ Hadoop แล้ว นี่คือบางส่วนของพวกเขา:
- Pig เป็นภาษาวิเคราะห์ข้อมูลเชิงประกาศ
- Hive - การวิเคราะห์ข้อมูลโดยใช้ภาษาที่คล้ายกับ SQL
- Oozie - เวิร์กโฟลว์ Hadoop
- Hbase เป็นฐานข้อมูล (ไม่เกี่ยวข้อง) คล้ายกับ Google Big Table
- ควาญช้าง - การเรียนรู้ของเครื่อง
- Sqoop - ถ่ายโอนข้อมูลจาก RSDB ไปยัง Hadoop และในทางกลับกัน
- Flume - ถ่ายโอนบันทึกไปยัง HDFS
- Zookeeper, MRUnit, Avro, Giraph, Ambari, Cassandra, HCatalog, Fuse-DFS และอื่นๆ
เครื่องมือทั้งหมดนี้เปิดให้ทุกคนใช้งานได้ฟรี แต่ก็มีส่วนเสริมที่ต้องชำระเงินอีกมากมาย
นอกจากนี้ยังจำเป็นต้องมีผู้เชี่ยวชาญ: นักพัฒนาและนักวิเคราะห์ (ที่เรียกว่า Data Scientist) จำเป็นต้องมีผู้จัดการที่สามารถเข้าใจวิธีใช้การวิเคราะห์นี้เพื่อแก้ไขปัญหาเฉพาะได้ เนื่องจากในตัวมันเองแล้ว มันไม่มีความหมายเลยหากไม่ได้รวมเข้ากับกระบวนการทางธุรกิจ
พนักงานทั้งสามคนจะต้องทำงานเป็นทีม ผู้จัดการที่ให้ผู้เชี่ยวชาญด้าน Data Science ค้นหารูปแบบบางอย่างต้องเข้าใจว่าเขาจะไม่ได้พบสิ่งที่ต้องการเสมอไป ในกรณีนี้ ผู้จัดการควรรับฟังสิ่งที่ Data Scientist พบอย่างรอบคอบ เนื่องจากบ่อยครั้งการค้นพบของเขาจะน่าสนใจและเป็นประโยชน์ต่อธุรกิจมากกว่า งานของคุณคือนำสิ่งนี้ไปใช้กับธุรกิจและสร้างผลิตภัณฑ์ขึ้นมา
แม้ว่าปัจจุบันจะมีเครื่องจักรและเทคโนโลยีหลายประเภท แต่การตัดสินใจขั้นสุดท้ายก็ยังขึ้นอยู่กับบุคคลเสมอ เมื่อต้องการทำเช่นนี้ ข้อมูลจะต้องมีการแสดงภาพ มีเครื่องมือมากมายสำหรับสิ่งนี้
ตัวอย่างที่ชัดเจนที่สุดคือรายงานเชิงภูมิศาสตร์ บริษัท Beeline ทำงานร่วมกับรัฐบาลของเมืองและภูมิภาคต่างๆ เป็นอย่างมาก บ่อยครั้งที่องค์กรเหล่านี้สั่งรายงาน เช่น "การจราจรติดขัดในบางพื้นที่"
ชัดเจนว่ารายงานดังกล่าวควรส่งถึงหน่วยงานของรัฐในรูปแบบที่เรียบง่ายและเข้าใจได้ หากเราจัดเตรียมตารางขนาดใหญ่และไม่สามารถเข้าใจได้อย่างสมบูรณ์ให้พวกเขา (นั่นคือข้อมูลในรูปแบบที่เราได้รับ) พวกเขาไม่น่าจะซื้อรายงานดังกล่าว - มันจะไร้ประโยชน์โดยสิ้นเชิงพวกเขาจะไม่ได้รับความรู้จากมันว่า พวกเขาต้องการรับ
ดังนั้น ไม่ว่านักวิทยาศาสตร์ข้อมูลจะเก่งแค่ไหนและไม่ว่าพวกเขาจะพบรูปแบบใดก็ตาม คุณจะไม่สามารถทำงานกับข้อมูลนี้ได้หากไม่มีเครื่องมือสร้างภาพที่ดี
แหล่งข้อมูล
อาร์เรย์ของข้อมูลที่ได้รับมีขนาดใหญ่มาก จึงสามารถแบ่งออกเป็นหลายกลุ่มได้
ข้อมูลภายในบริษัท
แม้ว่า 80% ของข้อมูลที่รวบรวมจะเป็นของกลุ่มนี้ แต่แหล่งข้อมูลนี้ก็ไม่ได้ใช้เสมอไป บ่อยครั้งเป็นข้อมูลที่ดูเหมือนไม่มีใครต้องการเลย เช่น บันทึก แต่หากคุณมองจากมุมที่ต่างออกไป บางครั้งคุณอาจพบรูปแบบที่ไม่คาดคิดในตัวมัน
แหล่งที่มาของแชร์แวร์
ซึ่งรวมถึงข้อมูลด้วย สังคมออนไลน์อินเทอร์เน็ตและทุกสิ่งที่คุณสามารถเข้าใช้งานได้ฟรี ทำไมแชร์แวร์ถึงฟรี? ในอีกด้านหนึ่ง ข้อมูลนี้ใช้ได้กับทุกคน แต่ถ้าคุณเป็นบริษัทขนาดใหญ่ การได้มาซึ่งข้อมูลดังกล่าวในขนาดฐานสมาชิกที่มีลูกค้านับหมื่น ร้อย หรือหลายล้านรายก็ไม่ใช่เรื่องง่ายอีกต่อไป จึงมี บริการชำระเงินเพื่อให้ข้อมูลนี้
แหล่งจ่าย
ซึ่งรวมถึงบริษัทที่ขายข้อมูลเพื่อเงินด้วย สิ่งเหล่านี้อาจเป็นโทรคมนาคม, DMP, บริษัทอินเทอร์เน็ต, สำนักงานข้อมูลเครดิต และผู้รวบรวมข้อมูล ในรัสเซีย โทรคมนาคมไม่ขายข้อมูล ประการแรก มันไม่ทำกำไรในเชิงเศรษฐกิจ และประการที่สอง เป็นสิ่งต้องห้ามตามกฎหมาย ดังนั้นพวกเขาจึงขายผลลัพธ์ของการประมวลผล เช่น รายงานเชิงภูมิศาสตร์
เปิดข้อมูล
รัฐกำลังอำนวยความสะดวกให้กับธุรกิจต่างๆ และเปิดโอกาสให้พวกเขาใช้ข้อมูลที่พวกเขารวบรวม สิ่งนี้ได้รับการพัฒนาในระดับตะวันตกมากขึ้น แต่รัสเซียในเรื่องนี้ก็ยังตามทันเวลาอยู่ ตัวอย่างเช่น มี Open Data Portal ของรัฐบาลมอสโกซึ่งมีการเผยแพร่ข้อมูลเกี่ยวกับสิ่งอำนวยความสะดวกโครงสร้างพื้นฐานในเมืองต่างๆ
สำหรับผู้พักอาศัยและแขกในมอสโก ข้อมูลจะถูกนำเสนอในรูปแบบตารางและการทำแผนที่ และสำหรับนักพัฒนา - ในรูปแบบพิเศษที่เครื่องอ่านได้ ในขณะที่โปรเจ็กต์กำลังทำงานในโหมดที่จำกัด โปรเจ็กต์กำลังพัฒนา ซึ่งหมายความว่ายังเป็นแหล่งข้อมูลที่คุณสามารถใช้สำหรับงานทางธุรกิจของคุณได้
วิจัย
ดังที่ได้กล่าวไปแล้ว หน้าที่ของ Big Data คือการค้นหารูปแบบ บ่อยครั้งที่การวิจัยที่ดำเนินการทั่วโลกอาจกลายเป็นจุดศูนย์กลางในการค้นหารูปแบบเฉพาะ คุณสามารถได้รับผลลัพธ์ที่เฉพาะเจาะจงและพยายามใช้ตรรกะที่คล้ายกันเพื่อวัตถุประสงค์ของคุณเอง
Big Data เป็นพื้นที่ที่กฎทางคณิตศาสตร์ไม่ได้ใช้ทั้งหมด ตัวอย่างเช่น “1” + “1” ไม่ใช่ “2” แต่มากกว่านั้นมาก เนื่องจากการผสมผสานแหล่งข้อมูลจะทำให้เอฟเฟกต์ได้รับการปรับปรุงอย่างมีนัยสำคัญ
ตัวอย่างสินค้า
หลายคนคุ้นเคยกับบริการเลือกเพลง Spotify เป็นเรื่องดีเพราะไม่ได้ถามผู้ใช้ว่าวันนี้อารมณ์ของพวกเขาเป็นอย่างไร แต่คำนวณตามแหล่งที่มาที่มีอยู่ เขารู้อยู่เสมอว่าคุณต้องการอะไรในตอนนี้ - แจ๊สหรือฮาร์ดร็อค นี่คือข้อแตกต่างหลักที่มอบให้กับแฟนๆ และแตกต่างจากบริการอื่นๆ

ผลิตภัณฑ์ดังกล่าวมักเรียกว่าผลิตภัณฑ์ที่ให้ความรู้สึก - ผลิตภัณฑ์ที่รู้สึกถึงลูกค้า
เทคโนโลยี Big Data ยังใช้ในอุตสาหกรรมยานยนต์อีกด้วย ตัวอย่างเช่น Tesla ทำสิ่งนี้ - ในพวกเขา รุ่นใหม่ล่าสุดมีระบบอัตโนมัติ บริษัทมุ่งมั่นที่จะสร้างรถยนต์ที่จะพาผู้โดยสารไปยังที่ที่เขาต้องการ หากไม่มี Big Data ก็เป็นไปไม่ได้ เพราะถ้าเราใช้เฉพาะข้อมูลที่เราได้รับโดยตรงแบบที่คนๆ หนึ่งทำ รถก็จะไม่สามารถปรับปรุงได้

เมื่อเราขับรถด้วยตัวเอง เราใช้เซลล์ประสาทในการตัดสินใจโดยพิจารณาจากปัจจัยหลายประการที่เราไม่ได้สังเกตเห็นด้วยซ้ำ ตัวอย่างเช่น เราอาจไม่รู้ว่าเหตุใดเราจึงตัดสินใจไม่เร่งความเร็วทันทีที่ไฟเขียว แต่ปรากฎว่าการตัดสินใจนั้นถูกต้อง - มีรถวิ่งผ่านคุณไปด้วยความเร็วที่อันตราย และคุณหลีกเลี่ยงอุบัติเหตุได้
คุณสามารถยกตัวอย่างการใช้ Big Data ในกีฬาได้ ในปี 2002 Billy Beane ผู้จัดการทั่วไปของทีมเบสบอล Oakland Athletics ตัดสินใจที่จะทำลายกระบวนทัศน์ในการรับสมัครนักกีฬา - เขาเลือกและฝึกฝนผู้เล่น "ตามจำนวน"
โดยปกติแล้วผู้จัดการจะพิจารณาถึงความสำเร็จของผู้เล่น แต่ในกรณีนี้ ทุกอย่างแตกต่างออกไป - เพื่อให้ได้ผลลัพธ์ ผู้จัดการได้ศึกษาว่าเขาต้องการนักกีฬาชุดใดโดยคำนึงถึงลักษณะเฉพาะของแต่ละบุคคล ยิ่งกว่านั้นเขาเลือกนักกีฬาที่ไม่มีศักยภาพในตัวเองมากนัก แต่โดยรวมทีมกลับประสบความสำเร็จอย่างมากจนชนะได้ 20 นัดติดต่อกัน

ต่อมาผู้กำกับเบนเน็ตต์ มิลเลอร์ได้สร้างภาพยนตร์เกี่ยวกับเรื่องนี้โดยเฉพาะเรื่อง “The Man Who Changed Everything” ที่นำแสดงโดยแบรด พิตต์
เทคโนโลยี Big Data ยังมีประโยชน์ในภาคการเงินอีกด้วย ไม่ใช่คนเดียวในโลกที่สามารถตัดสินใจได้อย่างอิสระและแม่นยำว่าควรให้เงินกู้แก่ใครบางคนหรือไม่ ในการตัดสินใจ จะมีการให้คะแนน นั่นคือ แบบจำลองความน่าจะเป็นถูกสร้างขึ้น ซึ่งสามารถเข้าใจได้ว่าบุคคลนี้จะคืนเงินหรือไม่ นอกจากนี้ การให้คะแนนจะถูกนำไปใช้ในทุกขั้นตอน: คุณสามารถคำนวณได้ว่าบุคคลหนึ่งจะหยุดจ่ายเงินในช่วงเวลาหนึ่ง
ข้อมูลขนาดใหญ่ช่วยให้คุณไม่เพียงแต่สร้างรายได้ แต่ยังช่วยประหยัดอีกด้วย โดยเฉพาะอย่างยิ่งเทคโนโลยีนี้ช่วยให้กระทรวงแรงงานของเยอรมนีลดต้นทุนสวัสดิการการว่างงานได้ 10 พันล้านยูโร เนื่องจากหลังจากการวิเคราะห์ข้อมูลเป็นที่ชัดเจนว่ามีการจ่ายผลประโยชน์ 20% โดยไม่สมควร
เทคโนโลยียังใช้ในการแพทย์ด้วย (นี่เป็นเรื่องปกติสำหรับอิสราเอล) ด้วยความช่วยเหลือของ Big Data คุณสามารถทำการวิเคราะห์ที่แม่นยำมากกว่าที่แพทย์ที่มีประสบการณ์สามสิบปีจะทำได้
แพทย์คนใดเมื่อทำการวินิจฉัยจะต้องอาศัยตัวเขาเองเท่านั้น ประสบการณ์ของตัวเอง. เมื่อเครื่องจักรทำเช่นนี้ ก็มาจากประสบการณ์ของแพทย์ดังกล่าวหลายพันคนและประวัติเคสที่มีอยู่ทั้งหมด โดยคำนึงถึงว่าบ้านของผู้ป่วยทำจากวัสดุอะไร เหยื่ออาศัยอยู่บริเวณไหน มีควันประเภทไหน และอื่นๆ นั่นคือคำนึงถึงปัจจัยหลายประการที่แพทย์ไม่ได้คำนึงถึง
ตัวอย่างของการใช้ Big Data ในการดูแลสุขภาพคือโครงการ Project Artemis ซึ่งดำเนินการโดยโรงพยาบาลเด็กโตรอนโต นี้ ระบบข้อมูลซึ่งรวบรวมและวิเคราะห์ข้อมูลเกี่ยวกับเด็กทารกแบบเรียลไทม์ เครื่องช่วยให้คุณวิเคราะห์ตัวชี้วัดสุขภาพของเด็กแต่ละคนได้ 1,260 รายการทุกๆ วินาที โครงงานนี้มีวัตถุประสงค์เพื่อพยากรณ์ภาวะไม่แน่นอนของเด็กและการป้องกันโรคในเด็ก
รัสเซียเริ่มมีการใช้ Big Data เช่นกัน ตัวอย่างเช่น Yandex มีแผนกข้อมูลขนาดใหญ่ บริษัทร่วมกับ AstraZeneca และ Russian Society of Clinical Oncology RUSSCO ได้เปิดตัวแพลตฟอร์ม RAY ซึ่งมีไว้สำหรับนักพันธุศาสตร์และนักชีววิทยาระดับโมเลกุล โครงการนี้ช่วยให้เราสามารถปรับปรุงวิธีการวินิจฉัยโรคมะเร็งและระบุแนวโน้มที่จะเกิดมะเร็งได้ แพลตฟอร์มดังกล่าวจะเปิดตัวในเดือนธันวาคม 2559
คำว่า Big Data มักจะหมายถึงข้อมูลที่มีโครงสร้าง กึ่งโครงสร้าง และไม่มีโครงสร้างจำนวนเท่าใดก็ได้ อย่างไรก็ตาม รายการที่สองและสามสามารถและควรสั่งซื้อเพื่อการวิเคราะห์ข้อมูลในภายหลัง Big Data ไม่ได้เทียบเท่ากับปริมาณจริงใดๆ แต่เมื่อพูดถึง Big Data ในกรณีส่วนใหญ่ เราหมายถึงข้อมูลเทราไบต์ เพตาไบต์ และแม้แต่ไบต์พิเศษ ธุรกิจใดๆ ก็ตามสามารถสะสมข้อมูลจำนวนนี้ในช่วงเวลาหนึ่งได้ หรือในกรณีที่บริษัทต้องการรับข้อมูลจำนวนมากแบบเรียลไทม์
การวิเคราะห์ข้อมูลขนาดใหญ่
เมื่อพูดถึงการวิเคราะห์ Big Data เราหมายถึงการรวบรวมและจัดเก็บข้อมูลจากแหล่งต่างๆ เป็นหลัก ตัวอย่างเช่น ข้อมูลเกี่ยวกับลูกค้าที่ซื้อสินค้า คุณลักษณะของพวกเขา ข้อมูลเกี่ยวกับการเปิดตัว บริษัทโฆษณาและการประเมินประสิทธิผล ข้อมูล ศูนย์ติดต่อ. ใช่ ข้อมูลทั้งหมดนี้สามารถเปรียบเทียบและวิเคราะห์ได้ เป็นไปได้และจำเป็น แต่ในการทำเช่นนี้ คุณต้องตั้งค่าระบบที่ช่วยให้คุณสามารถรวบรวมและแปลงข้อมูลโดยไม่บิดเบือน จัดเก็บ และสุดท้ายก็แสดงภาพได้ เห็นด้วย เนื่องจากข้อมูลขนาดใหญ่ ตารางที่พิมพ์ลงบนหน้าหลายพันหน้าช่วยได้เพียงเล็กน้อยในการตัดสินใจทางธุรกิจ
1. การมาถึงของข้อมูลขนาดใหญ่
บริการส่วนใหญ่ที่รวบรวมข้อมูลเกี่ยวกับการกระทำของผู้ใช้มีความสามารถในการส่งออกได้ เพื่อให้แน่ใจว่าพวกเขาจะมาถึงบริษัทในรูปแบบที่มีโครงสร้าง จึงมีการใช้ระบบต่างๆ เช่น Alteryx ซอฟต์แวร์นี้ช่วยให้คุณได้รับ โหมดอัตโนมัติข้อมูล ประมวลผล แต่ที่สำคัญที่สุด - แปลงเป็น ประเภทที่ถูกต้องและรูปแบบที่ไม่บิดเบือน
2. การจัดเก็บและการประมวลผลข้อมูลขนาดใหญ่
เกือบทุกครั้งเมื่อรวบรวมข้อมูลจำนวนมาก ปัญหาในการจัดเก็บข้อมูลก็เกิดขึ้น ในบรรดาแพลตฟอร์มทั้งหมดที่เราศึกษา บริษัทของฉันชอบ Vertica มากกว่า แตกต่างจากผลิตภัณฑ์อื่นๆ Vertica สามารถ "คืน" ข้อมูลที่จัดเก็บไว้ในผลิตภัณฑ์ได้อย่างรวดเร็ว ข้อเสียได้แก่ การบันทึกเป็นเวลานาน แต่เมื่อวิเคราะห์ข้อมูลขนาดใหญ่ ความเร็วของการส่งคืนจะมาเป็นอันดับแรก ตัวอย่างเช่น หากเรากำลังพูดถึงการคอมไพล์โดยใช้ข้อมูลขนาดเพตะไบต์ ความเร็วในการอัพโหลดก็เป็นหนึ่งในคุณสมบัติที่สำคัญที่สุด
3. การแสดงข้อมูลขนาดใหญ่
และสุดท้าย ขั้นตอนที่สามของการวิเคราะห์ข้อมูลจำนวนมากก็คือ ในการดำเนินการนี้ คุณต้องมีแพลตฟอร์มที่สามารถแสดงข้อมูลที่ได้รับทั้งหมดในรูปแบบภาพที่สะดวก ในความเห็นของเรา ผลิตภัณฑ์ซอฟต์แวร์เพียงตัวเดียวเท่านั้นที่สามารถรับมือกับงานนี้ได้ - Tableau แน่นอนว่าเป็นหนึ่งในสิ่งที่ดีที่สุด วันนี้โซลูชันที่สามารถแสดงข้อมูลใด ๆ ที่เป็นภาพ เปลี่ยนงานของบริษัทให้เป็นแบบจำลองสามมิติ รวบรวมการดำเนินการของทุกแผนกเป็นห่วงโซ่ที่พึ่งพาซึ่งกันและกัน (คุณสามารถอ่านเพิ่มเติมเกี่ยวกับความสามารถของ Tableau)
โปรดทราบว่าตอนนี้เกือบทุกบริษัทสามารถสร้าง Big Data ของตนเองได้ การวิเคราะห์ข้อมูลขนาดใหญ่ไม่ใช่กระบวนการที่ซับซ้อนและมีราคาแพงอีกต่อไป ขณะนี้ฝ่ายบริหารของบริษัทจำเป็นต้องกำหนดคำถามให้ถูกต้อง ข้อมูลที่รวบรวมในขณะที่แทบไม่เหลือพื้นที่สีเทาที่มองไม่เห็นเหลืออยู่
ดาวน์โหลด Tableau