Въведение в XML-RPC. Състезания по програмиране Какво се вижда на диаграмата
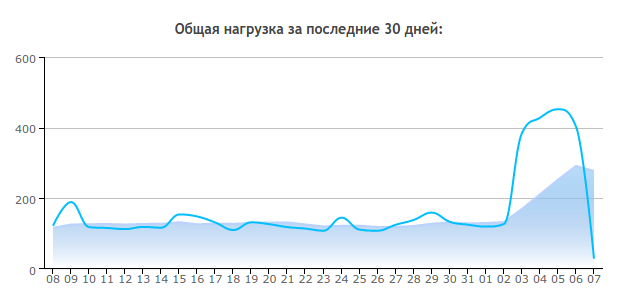
Преди няколко дни забелязах, че натоварването на моите сайтове на хостинг се е увеличило значително. Ако обикновено беше около 100-120 „папагала“ (CP), то през последните няколко дни се увеличи до 400-500 CP. В това няма нищо добро, защото хостът може да премине към по-скъпа тарифа или дори напълно да затвори достъпа до сайтовете, така че започнах да го разглеждам.
Но аз избрах метод, който ще запази функционалността на XML-RPC: инсталиране на приставката Disable XML-RPC Pingback. Той премахва само "опасните" методи pingback.ping и pingback.extensions.getPingbacks, оставяйки функционалността на XML-RPC. Веднъж инсталиран, плъгинът трябва само да се активира - не е необходима допълнителна конфигурация.
По пътя въведох всички IP адреси на нападателите във файла .htaccess на моите сайтове, за да блокирам достъпа им. Току-що добавих в края на файла:
Поръчка Разрешаване, Отказ Разрешаване от всички Отказ от 5.196.5.116 37.59.120.214 92.222.35.159
Това е всичко, сега надеждно защитихме блога от по-нататъшни атаки с помощта на xmlrpc.php. Нашите сайтове спряха да зареждат хостинга със заявки, както и DDoS атаки към сайтове на трети страни.
От обяд в събота моят сървър, където се хостват около 25 сайта на Wordpress, започна да изпитва сериозни забавяния. Тъй като успях да преживея предишните атаки ( , ) без да бъда забелязан, не разбрах веднага какво се случва.
Когато го разбрах, се оказа, че паролите са грубо форсирани + много заявки към XMLRPC.
В резултат на това успяхме да прекъснем всичко, макар и не веднага. Ето три прости трика как да избегнете това.
Тези техники най-вероятно са известни на всички, но стъпих на няколко грешки, които не намерих в описанията - може би това ще спести време на някого.
1. Спрете търсенето, инсталирайте приставката Limit Login Attempts - инсталирайте я, тъй като други защити значително забавят сървъра, например, когато използвате приставката Login Security Solution, сървърът умря след половин час, приставката натоварва силно базата данни .
В настройките не забравяйте да поставите отметка в квадратчето „За прокси“ - в противен случай той ще определи IP на вашия сървър за всички и автоматично ще блокира всички.
АКТУАЛИЗАЦИЯ, благодаря ви, подробностите са по-долу в коментарите - поставете отметка в квадратчето „За прокси“ само ако дефиницията не работи, когато е активирана „Директна връзка“
2. Деактивирайте XML-RPC - приставката за деактивиране на XML-RPC (лесно се активира и това е).
3. Затворете wp-login.php - ако влезете в сайта през IP, плъгинът не работи и пикерите продължават да сриват сайта. За да избегнете това, добавете към .htaccess:
Копираме файла wp-login, преименуваме го на произволно странно име, например poletnormalny.php, и вътре във файла използваме автокорекция, за да променим всички надписи wp-login.php на poletnormalny.php.
Това е всичко, сега можете да получите достъп до админ панела само чрез вашия файл.
След тези 3 лесни стъпки, сайтовете започнаха да летят отново и настъпи мир.
Е, изведнъж става интересно
Един от вариантите е да видите дали ви атакуват. Това може да се види в регистрационните файлове на nginx (например, тук е пътя за файла /var/log/nginx access.log на Debian).XML-RPC технологията се използва в системата WordPress за различни приятни функции като pingbacks, trackbacks, отдалечено управление на сайт без влизане в админ панела и т.н. За съжаление, нападателите могат да го използват за извършване на DDoS атаки на уебсайтове. Тоест създавате красиви, интересни WP проекти за себе си или по поръчка и в същото време, без да подозирате нищо, можете да бъдете част от DDoS ботнет. Свързвайки десетки и стотици хиляди сайтове заедно, лошите хора създават мощна атака срещу жертвата си. Въпреки че в същото време вашият сайт също страда, защото... натоварването отива към хостинга, където се намира.
Доказателство за такава лоша дейност може да бъде в регистрационните файлове на сървъра (access.log в nginx), съдържащи следните редове:
103.238.80.27 - - "POST /wp-login.php HTTP/1.0" 200 5791 "-" "-"
Но да се върнем към уязвимостта на XML-RPC. Визуално се проявява в бавното отваряне на сайтовете на вашия сървър или невъзможността за зареждането им изобщо (грешка 502 Bad Gateway). Техническата поддръжка на моя FASTVPS хост потвърди предположенията ми и ме посъветва:
- Актуализирайте WordPress до най-новата версия заедно с плъгини. Като цяло, ако следвате, може би сте чели за необходимостта от инсталиране на най-новата 4.2.3. поради критики към сигурността (точно както предишните версии). Накратко, добре е да се актуализира.
- Инсталирайте приставката Disable XML-RPC Pingback.
Деактивиране на XML-RPC в WordPress
Преди ми се струва, че опцията за активиране/деактивиране на XML-RPC беше някъде в системните настройки, но сега не мога да я намеря там. Следователно, най-лесният начин да се отървете от него е да използвате подходящия плъгин.

Намерете и изтеглете Disable XML-RPC Pingback или го инсталирайте директно от системния администраторски панел. Не е необходимо да конфигурирате нищо допълнително, модулът започва да работи веднага. Той премахва методите pingback.ping и pingback.extensions.getPingbacks от XML-RPC интерфейса. Освен това премахва X-Pingback от HTTP заглавките.
В един от блоговете намерих още няколко опции за премахване на деактивирането на XML-RPC.
1. Деактивирайте XML-RPC в шаблона.
За да направите това, добавете следния ред към файла functions.php на темата:
Аз лично не използвах последните два метода, защото... Свързах плъгина Disable XML-RPC Pingback - мисля, че ще е достатъчно. Само за тези, които не обичат ненужните инсталации, предложих алтернативни опции.
Организация на обработка на нишки с ефективно използване на паметта
Елиът Ръсти Харолд
Публикувана на 11.10.2007 г
PHP 5 представи XMLReader, нов клас за четене на Extensible Markup Language (XML). За разлика от обикновения XML или Document Object Model (DOM), XMLReader работи в режим на поточно предаване. Тоест чете документа от началото до края. Можете да започнете да работите със съдържанието на документа в началото на документа, преди да видите края. Това го прави много бърз, ефективен и с много ефективна памет. Колкото по-голям е размерът на документите, които трябва да бъдат обработени, толкова по-важно е това.
libxml
Описаният API на XMLReader е базиран на библиотеката libxml на проекта Gnome за C и C++. В действителност XMLReader е просто тънък PHP слой върху libxml XmlTextReader API. XmlTextReader също е моделиран след (въпреки че не споделя същия код като) .NET класовете XmlTextReader и XmlReader.
За разлика от простия XML API (SAX), XMLReader е по-скоро анализатор за изтегляне, отколкото анализатор за насочване. Това означава, че програмата е под контрол. Вместо анализаторът да ви казва какво вижда, когато го види; казвате на анализатора кога да премине към следващата част от документа. Вие питате за съдържание, вместо да реагирате на него. С други думи, можете да мислите за това по следния начин: XMLReader е имплементация на конструкцията Iterator, а не конструкцията Observer.
Примерна задача
Да започнем с един прост пример. Представете си, че пишете PHP скрипт, който получава XML-RPC заявки и генерира отговори. По-конкретно, представете си заявките, които изглеждат като листинг 1. Елементът на основния документ е methodCall, който съдържа елементите methodName и params. Името на метода е sqrt. Елементът params съдържа един елемент param, който включва двойно - числото, чийто квадратен корен искате да извлечете. Не се използват пространства от имена.
Листинг 1. XML-RPC заявка
Ето какво трябва да прави PHP скриптът:
- Проверете името на метода и генерирайте отговор за грешка, ако не е sqrt (единственият метод, който може да се обработва от този скрипт).
- Намерете аргумента и, ако липсва или е от грешен тип, генерирайте сигнал за грешка.
- В противен случай изчислете квадратния корен.
- Върнете резултата във формата, показана в списък 2.
Листинг 2. XML-RPC отговор
Нека го направим стъпка по стъпка.
Инициализиране на анализатора и зареждане на документа
Първата стъпка е да създадете нов парсер обект. Лесно е да се направи:
$reader = нов XMLReader();Добавяне на информация към оригиналните данни, които се изпращат
Ако установите, че $HTTP_RAW_POST_DATA е празен, добавете следния ред към вашия php.ini файл:
always_populate_raw_post_data = Включено
$заявка = $HTTP_RAW_POST_DATA; $reader->XML($request);Можете да анализирате всеки низ, независимо откъде сте го взели. Например, това може да е константа на низов литерал в програма или съдържанието на файл. Можете също да заредите данни от външен URL чрез функцията open(). Например, следната инструкция подготвя един от Atom каналите за анализиране:
$reader->XML("http://www.cafeaulait.org/today.atom");Откъдето и да сте взели изходните си данни, четецът вече е инсталиран и готов за извършване на анализ.
Четене на документ
Функцията read() премества анализатора към следващия токен. Най-простият подход е да повторите цикъл while в целия документ:
докато ($reader->read()) ( // обработващ код... )Когато приключите, затворете анализатора, за да освободите ресурсите, които заема, и го конфигурирайте отново за следния документ:
$reader->close();Вътре в цикъла парсерът се поставя в определен възел: в началото на елемент, в края на елемент, в текстов възел, в коментар и т.н. Следните свойства ви позволяват да знаете какво анализаторът гледа в момента:
- localName е локалното, непредефинирано име на хост.
- име - възможно предварително дефинирано име на възел. За възли, които нямат имена, като коментари, това са #comment , #text , #document и т.н., както в DOM (Document Object Model).
- namespaceURI е Uniform Resource Identifier (URI) за пространството от имена на хоста.
- nodeType е цяло число, представляващо типа на възела - например 2 за възел на атрибут и 7 за оператор за обработка.
- prefix е префиксът на пространството от имена на възела.
- стойността е текстовото съдържание на възела.
- hasValue - true, ако възелът има текстова стойност и false в противен случай.
Разбира се, не всички типове възли имат всички тези свойства. Например, текстови възли, CDATA секции, коментари, изрази за обработка, атрибути, знак за интервал, типове документи и XML описания имат значения. Други типове възли (особено елементи и документи) не го правят. Обикновено програмата използва свойството nodeType, за да определи какво се преглежда и да реагира съответно. Списък 3 показва прост цикъл while, който използва тези функции, за да изведе това, което гледа. Списък 4 показва изхода на тази програма, когато е даден листинг 1 като вход.
Листинг 3. Какво вижда анализаторът
while ($reader->read()) ( echo $reader->name; if ($reader->hasValue) ( echo ": ". $reader->value; ) echo "\n"; )Листинг 4. Резултат от листинг 3
methodCall #text: methodName #text: sqrt methodName #text: params #text: param #text: value double #text: 10 double value #text: param #text: params #text: methodCallПовечето програми не са толкова универсални. Те приемат входни данни в определена форма и ги обработват по определен начин. В примера на XML-RPC само един параметър трябва да бъде прочетен от входа: двойният елемент, от който трябва да има само един. За да направите това, намерете началото на елемента с име double:
if ($reader->name == "double" && $reader->nodeelementType == XMLReader::element) ( // ... )Този елемент също има единичен текстов дъщерен възел, който може да бъде прочетен чрез преместване на анализатора към следващия възел:
if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) ( $reader->read(); respond($reader->value); )Тук функцията respond() създава XML-RPC отговор и го изпраща на клиента. Преди да покажа това обаче, има още нещо, което трябва да се каже. Няма гаранция, че двойният елемент в документа на заявката съдържа само един текстов възел. Може да съдържа множество възли, както и коментари и изявления. Например може да изглежда така:
Вложени елементи
Има един възможен дефект в тази верига. Вложени двойни елементи, например
Устойчиво решение на проблема би било да се съберат всички деца на двоен текстов възел, да се свържат заедно и едва след това да се преобразува резултатът в double. Всякакви коментари или други възможни нетекстови възли трябва да се избягват. Това е малко по-сложно, но не прекалено сложно, както показва списък 5.
Листинг 5. Обобщаване на цялото текстово съдържание на елемент
докато ($reader->read()) ( if ($reader->nodeType == XMLReader::TEXT || $reader->nodeType == XMLReader::CDATA || $reader->nodeType == XMLReader::WHITESPACE || $reader->nodeType == XMLReader::SIGNIFICANT_WHITESPACE) ( $input .= $reader->value; ) else if ($reader->nodeType == XMLReader::END_ELEMENT && $reader->name == "double ") ( прекъсване; ) )Засега цялото друго съдържание на документа може да бъде игнорирано. (Ще продължа да описвам обработката на грешки по-късно.)
Създаване на отговор
Както подсказва името, XMLReader е само за четене. Съответният клас XMLWriter в момента се разработва, но все още не е готов. За щастие писането на XML е много по-лесно от четенето му. Първо, трябва да зададете медийния тип на отговора с помощта на функцията header(). За XML-RPC това е application/xml. Например:
header("Content-type: application/xml");Листинг 6. XML картографиране
функция отговаря ($input) ( ехо "Можете дори да вмъкнете буквените части от отговора директно в PHP страницата, точно както бихте го направили в HTML. Тази технология е показана в списък 7.
Листинг 7. Литерал XML
функция respond($input) ( ?>Обработка на грешка
Досега се приемаше, че входният документ е форматиран правилно. Това обаче никой не може да гарантира. Като всеки XML анализатор, XMLReader трябва да спре обработката веднага щом срещне грешка при форматиране. Ако това се случи, функцията read() връща false.
На теория анализаторът може да обработва данни до първата срещана грешка. В моите експерименти с малки документи обаче почти веднага среща грешка. Базовият парсер анализира предварително голяма част от документа, кешира го и след това го извежда част по част. По този начин той обикновено идентифицира грешките на предварителен етап. От съображения за сигурност е по-добре да не поемате отговорност за факта, че можете да извършите анализ на съдържанието преди първата грешка в дизайна. Освен това не предполагайте, че няма да видите съдържание, преди анализаторът да се провали. Ако трябва да приемете само пълни, правилно форматирани документи, тогава се уверете, че скриптът не прави нищо необратимо до самия край на документа.
Ако анализаторът срещне грешка при форматиране, функцията read() показва съобщение за грешка, подобно на това (ако е конфигурирано подробно отчитане на грешки, както трябва да бъде на сървър за разработка):
Внимание: XMLReader::read() [function.read]:< value>
Може да не искате да копирате отчета в HTML страницата, представена на потребителя. По-добре е да заснемете съобщението за грешка в променливата на средата $php_errormsg. За да направите това, трябва да активирате конфигурационната опция track_errors във файла php.ini:
track_errors = ВклПо подразбиране опцията track_errors е деактивирана, което е изрично посочено в php.ini, така че не забравяйте да промените този ред. Ако добавите реда, показан по-горе, в началото на php.ini, тогава редът track_errors = Off по-долу ще го замени.
Тази програма трябва да изпраща отговори само на пълен, правилно форматиран вход. (Също надежден, но повече за това по-късно.) Следователно трябва да изчакате анализът на документа да завърши (излизане от цикъла while). Сега проверете дали стойността на $php_errormsg се е променила. Ако не, тогава документът е форматиран правилно и ще бъде изпратено XML-RPC съобщение за отговор. Ако променливата е зададена, това означава, че документът не е форматиран правилно и ще бъде изпратен сигнал за грешка на XML-RPC. Сигнал за неуспех също се изпраща, ако се изисква корен квадратен от отрицателно число. Вижте списък 8.
Листинг 8. Проверка за правилно форматиране
// изпращане на заявка $request = $HTTP_RAW_POST_DATA; докладване_за_грешка(E_ГРЕШКА | E_ПРЕДУПРЕЖДЕНИЕ | E_PARSE); if (isset($php_errormsg)) unset(($php_errormsg); // създаване на програма за четене (reader) $reader = new XMLReader(); // $reader->setRelaxNGschema("request.rng"); $reader- > XML($request); $input = ""; while ($reader->read()) ( if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) ( докато ($reader->read()) ( if ($reader->nodeType == XMLReader::TEXT || $reader->nodeType == XMLReader::CDATA || $reader->nodeType == XMLReader::WHITESPACE | | $reader->nodeType == XMLReader::SIGNIFICANT_WHITESPACE) ( $input .= $reader->value; ) else if ($reader->nodeType == XMLReader::END_ELEMENT && $reader->name == "double " ) ( break; ) ) break; ) ) // проверка на правилното форматиране на входната информация if (isset($php_errormsg)) fault(21, $php_errormsg); else if ($input< 0) fault(20, "Cannot take square root of negative number"); else respond($input);Ето опростена версия на общия шаблон за обработка на XML поток. Анализаторът попълва структура от данни, според която се извършват действия, когато документът приключи. Обикновено структурата на данните е по-проста от самия документ. Тук структурата на данните е особено проста: един ред.
Валидиране
libxml версия
Ранните версии на libxml, библиотеката, от която зависи XMLReader, имаха сериозни недостатъци на RELAX NG. Уверете се, че използвате поне версия 2.06.26. Много системи, включително Mac OS X Tiger, съдържат по-ранна версия с недостатъци.
Досега не съм наблягал особено на проверката дали данните действително са там, където си мисля, че са. Най-лесният начин да извършите тази проверка е да сравните документа с диаграмата. XMLReader поддържа езика за описание на схемата RELAX NG; Листинг 9 показва проста RELAX NG схема за тази конкретна форма на XML-RPC заявка.
Списък 9. XML-RPC заявка
Схемата може да бъде добавена директно към PHP скрипт като низов литерал с помощта на setRelaxNGSchemaSource() или прочетена от външен файл или URL с помощта на setRelaxNGSchema(). Например, ако приемем, че съдържанието на листинг 9 е записано във файла sqrt.rng, схемата ще се зареди по следния начин:
reader->setRelaxNGSchema("sqrt.rng")Направи го предислед което започвате да анализирате документа. Анализаторът сравнява документа със схемата, докато чете. За да проверите дали даден документ е валиден, извикайте функцията isValid(), която връща true, ако документът е валиден (в този момент), и false в противен случай. Листинг 10 показва пълната програма, съдържаща всички обработки на грешки. Програмата трябва да приеме всеки валиден вход и да върне правилни стойности и да отхвърли всички неправилни заявки. Добавих също метод fault(), който изпраща XML-RPC грешка, ако нещо се обърка.
Списък 10. Пълен XML-RPC бекенд с квадратен корен
Атрибути
Атрибутите не се виждат по време на нормален анализ. За да прочетете атрибути, трябва да спрете в началото на елемента и да поискате конкретен атрибут по име или номер.
Предайте името на атрибута, чиято стойност искате да намерите в текущия елемент, на функцията getAttribute(). Например следната конструкция изисква атрибута id на текущия елемент:
$id = $reader->getAttribute("id");Ако атрибутът е в пространство от имена, например xlink:href, тогава извикайте getAttributeNS() и предайте локалното име и URI на пространството от имена съответно като първи и втори аргумент (префиксът няма значение). Например този оператор отправя запитване към стойността на атрибута xlink:href в пространството от имена http://www.w3.org/1999/xlink/:
$href = $reader->getAttributeNS("href", "http://www.w3.org/1999/xlink/");Ако атрибутът не съществува, тогава и двата метода ще върнат празен низ. (Това е неправилно, защото те трябва да връщат null. Тази реализация затруднява разграничаването между атрибути, чиято стойност е празен низ и тези, които нямат никаква стойност.)
Ред на атрибутите
В XML документи редът на атрибутите няма значение и не се запазва от анализатора. Той използва числа за индексиране на атрибути само за удобство. Няма гаранция, че първият атрибут в отварящия таг ще бъде атрибут 1, вторият ще бъде атрибут 2 и т.н. Не пишете код, който зависи от реда на атрибутите.
Ако трябва да знаете всички атрибути на даден елемент, но техните имена не са известни предварително, тогава извикайте moveToNextAttribute(), когато частта за четене е зададена на елемента. Ако анализаторът е на атрибутен възел, тогава можете да прочетете неговото име, пространство от имена и стойност, като използвате същите свойства, които са били използвани за елементи. Например следният кодов фрагмент отпечатва всички атрибути на текущия елемент:
if ($reader->hasAttributes and $reader->nodeType == XMLReader::ELEMENT) ( while ($reader->moveToNextAttribute()) ( echo $reader->name . "="" . $reader->value . ""\n"; ) ехо "\n"; )Много необичайно за XML API, XMLReader ви позволява да четете атрибути от самото начало, било то от краяелемент. За да се избегне двойното отчитане, важно е да се гарантира, че типът на възела е XMLReader::ELEMENT, а не XMLReader::END_ELEMENT, който също може да има атрибути.
Заключение
XMLReader е полезно допълнение към инструментариума на PHP програмиста. За разлика от SimpleXML, това е пълен XML анализатор, който обработва всички документи, а не само някои от тях. За разлика от DOM, той може да обработва документи, по-големи от наличната памет. За разлика от SAX, той установява контрол върху програмата. Ако PHP програмите трябва да приемат XML вход, тогава трябва сериозно да обмислите използването на XMLReader.
Въведение в XML-RPC
В интернет има много различни ресурси, които предоставят на потребителите определена информация. Това не означава обикновени статични страници, а например данни, извлечени от база данни или архиви. Това може да бъде архив от финансови данни (обменни курсове, данни за котировки на ценни книжа), данни за времето или по-обемна информация - новини, статии, съобщения от форуми. Такава информация може да бъде представена на посетителя на страницата, например чрез формуляр, като отговор на заявка или може да се генерира динамично всеки път. Но трудността е, че често такава информация е необходима не толкова на крайния потребител - човек, а на други системи и програми, които ще използват тези данни за своите изчисления или други нужди.
Реален пример: страница на банков уебсайт, която показва валутни котировки. Ако влезете в страницата като обикновен потребител, през браузър, виждате целия дизайн на страницата, банери, менюта и друга информация, която „рамкира“ истинската цел на търсенето - валутни котировки. Ако трябва да въведете тези котировки във вашия онлайн магазин, тогава не остава нищо друго, освен ръчно да изберете необходимите данни и да ги прехвърлите на вашия уебсайт чрез клипборда. И ще трябва да правите това всеки ден. Наистина ли няма изход?
Ако разрешите проблема директно, веднага възниква решение: програма (скрипт на уебсайт), която се нуждае от данни, получава страница от сървъра като „обикновен потребител“, анализира (анализира) получения html код и извлича необходимата информация от него. Това може да се направи или с регулярен регулярен израз, или с помощта на всеки html парсер. Трудността на подхода се състои в неговата неефективност. Първо, за да получите малка част от данните (данните за валутите са буквално дузина или два знака), трябва да получите цялата страница, която е поне няколко десетки килобайта. Второ, при всяка промяна в кода на страницата, например дизайнът се е променил или нещо друго, нашият алгоритъм за анализ ще трябва да бъде преработен. И това ще отнеме доста средства.
Затова разработчиците стигнаха до решение - необходимо е да се разработи някакъв универсален механизъм, който да позволи прозрачен (на ниво протокол и среда за предаване) и лесен обмен на данни между програми, които могат да бъдат разположени навсякъде, да бъдат написани на всеки език и да работи под всяка операционна система, системи и на всяка хардуерна платформа. Такъв механизъм сега се нарича с гръмките термини „уеб услуги“, „SOAP“, „ориентирана към услуги архитектура“. За обмен на данни се използват отворени и изпитани във времето стандарти - HTTP протоколът се използва за предаване на съобщения (въпреки че могат да се използват и други протоколи - SMTP, например). Самите данни (в нашия пример валутните курсове) се предават пакетирани в междуплатформен формат - под формата на XML документи. За тази цел е изобретен специален стандарт - SOAP.
Да, сега уеб услугите, SOAP и XML са на устните на всички, те започват активно да се внедряват и големи корпорации като IBM и Microsoft пускат нови продукти, предназначени да помогнат за пълното внедряване на уеб услуги.
Но! За нашия пример с обменни курсове, които трябва да бъдат предадени от уебсайта на банката към двигателя на онлайн магазина, такова решение ще бъде много трудно. В края на краищата само описанието на стандарта SOAP заема неприлични хиляда и половина страници и това не е всичко. За практическа употреба ще трябва също да научите как да работите с библиотеки и разширения на трети страни (само от PHP 5.0 той включва библиотека за работа със SOAP) и да напишете стотици и хиляди редове от собствен код. И всичко това, за да получите няколко букви и цифри, очевидно е много тромаво и нерационално.
Следователно има друг, може да се каже, алтернативен стандарт за обмен на информация - XML-RPC. Той е разработен с участието на Microsoft от UserLand Software Inc и е предназначен за унифициран трансфер на данни между приложенията през Интернет. Той може да замени SOAP при изграждане на прости услуги, където не са необходими всички „корпоративни“ възможности на реалните уеб услуги.
Какво означава абревиатурата (съкращението) XML-RPC? RPC означава Remote Procedure Call. Това означава, че приложение (независимо дали е скрипт на сървъра или обикновено приложение на клиентския компютър) може прозрачно да използва метод, който е физически внедрен и изпълнен на друг компютър. XML се използва тук, за да осигури универсален формат за описание на предаваните данни. Като транспорт, HTTP протоколът се използва за предаване на съобщения, което ви позволява безпроблемно да обменяте данни през всякакви мрежови устройства - рутери, защитни стени, прокси сървъри.
И така, за да използвате, трябва да имате: XML-RPC сървър, който предоставя един или повече методи, XML-RPC клиент, който може да генерира правилна заявка и да обработи сървърния отговор, и също така да знаете параметрите на сървъра, необходими за успешна работа - адрес, име на метод и предадени параметри.
Цялата работа с XML-RPC се извършва в режим „заявка-отговор“, това е една от разликите между технологията и стандарта SOAP, където има както концепциите за транзакции, така и възможността за извършване на забавени повиквания (когато сървърът записва искането и отговаря на него в определен момент в бъдеще). Тези допълнителни функции са по-полезни за мощни корпоративни услуги, те значително усложняват разработката и поддръжката на сървъри и поставят допълнителни изисквания към разработчиците на клиентски решения.
Процедурата за работа с XML-RPC започва с формиране на заявка. Типичната заявка изглежда така:
POST /RPC2 HTTP/1.0
Потребителски агент: eshop-test/1.1.1 (FreeBSD)
Хост: server.localnet.com
Тип съдържание: текст/xml
Дължина на съдържанието: 172
Първите редове формират стандартната HTTP POST заглавка на заявката. Задължителните параметри включват хост, тип данни (MIME тип), който трябва да бъде текст/xml, и дължина на съобщението. Стандартът също така определя, че полето User-Agent трябва да бъде попълнено, но може да съдържа произволна стойност.
Следва обичайната заглавка на XML документа. Основният елемент на заявката е
Линия
След това се задават предаваните параметри. Този раздел се използва за това.
Описанието на всички параметри е последвано от затварящи тагове. Заявката и отговорът в XML-RPC са обикновени XML документи, така че всички тагове трябва да бъдат затворени. Но в XML-RPC няма единични тагове, въпреки че те присъстват в XML стандарта.
Сега нека да разгледаме отговора на сървъра. Заглавката на HTTP отговора е нормална; ако заявката е обработена успешно, сървърът връща HTTP/1.1 200 OK отговор. Точно както в заявката, трябва правилно да посочите MIME типа, дължината на съобщението и датата на генериране на отговора.
Самото тяло на отговора е както следва:
Сега вместо основния маркер
Ако е възникнала грешка при обработката на вашата заявка, вместо Отговорът ще съдържа елемента
Сега нека разгледаме накратко типовете данни в XML-RPC. Има общо 9 типа данни - седем прости типа и 2 сложни. Всеки тип се описва със собствен етикет или набор от тагове (за сложни типове).
Прости видове:
Цели числа- етикет
Булев тип- етикет
ASCII низ- описано от етикет
Числа с плаваща запетая- етикет
дата и час- описано от етикет
Последният прост тип е base64 кодиран низ, което е описано от тага
Сложните типове са представени от структури и масиви. Структурата се определя от коренния елемент
Масивите нямат имена и се описват от тага
Разбира се, някой ще каже, че такъв списък от типове данни е много лош и „не ви позволява да се разширявате“. Да, ако трябва да прехвърлите сложни обекти или големи количества данни, тогава е по-добре да използвате SOAP. И за малки, непретенциозни приложения XML-RPC е доста подходящ, освен това много често дори неговите възможности се оказват твърде много! Като се има предвид лекотата на внедряване, много голям брой библиотеки за почти всеки език и платформа и широка поддръжка в PHP, тогава XML-RPC често просто няма конкуренти. Въпреки че не може веднага да се препоръча като универсално решение - във всеки конкретен случай трябва да се решава според обстоятелствата.