Анализ на големи обеми от данни. Машина за големи данни. Мащабиране и подреждане
По материали от Research&Trends
Големите данни са обект на разговори в ИТ и маркетинг пресата от няколко години. И е ясно: цифровите технологии са проникнали в живота модерен човек, „всичко е написано“. Обемът на данните за различни аспекти на живота нараства, а в същото време възможностите за съхранение на информация нарастват.
Глобални технологии за съхранение на информация
Източник: Хилбърт и Лопес, „Технологичният капацитет на света за съхраняване, комуникация и изчисляване на информация“, Наука, 2011 г. в световен мащаб.
Повечето експерти са съгласни, че ускоряването на растежа на данните е обективна реалност. Социални мрежи, мобилни устройства, данни от измервателни уреди, бизнес информация – това са само няколко вида източници, които могат да генерират гигантски обеми информация. Според изследването IDCЦифрова вселена, публикуван през 2012 г., през следващите 8 години количеството данни в света ще достигне 40 ZB (зетабайта), което се равнява на 5200 GB за всеки жител на планетата.
Разрастване на събирането на цифрова информация в САЩ

Източник: IDC
Значителна част от информацията се създава не от хора, а от роботи, взаимодействащи както помежду си, така и с други мрежи за данни - като например сензори и умни устройства. При този темп на растеж количеството данни в света, според изследователите, ще се удвоява всяка година. Брой виртуални и физически сървърив света ще нарасне десетократно поради разширяването и създаването на нови центрове за данни. В резултат на това има нарастваща нужда от ефективно използване и монетизиране на тези данни. Тъй като използването на Big Data в бизнеса изисква значителни инвестиции, трябва ясно да разберете ситуацията. И по същество е просто: можете да увеличите ефективността на бизнеса чрез намаляване на разходите и/или увеличаване на обема на продажбите.
Защо се нуждаем от големи данни?
Парадигмата на големите данни дефинира три основни типа проблеми.
- Съхраняване и управление на стотици терабайти или петабайти данни, които конвенционалните релационни бази данни не могат да използват ефективно.
- Организирайте неструктурирана информация, състояща се от текстове, изображения, видеоклипове и други видове данни.
- Big Data анализ, който поставя въпроса за начините за работа с неструктурирана информация, генериране на аналитични отчети, както и внедряване на прогнозни модели.
Пазарът на проекти за големи данни се пресича с пазара на бизнес анализи (BA), чийто глобален обем, според експерти, възлиза на около 100 милиарда долара през 2012 г. Включва компоненти на мрежови технологии, сървъри, софтуери технически услуги.
Също така, използването на Big Data технологии е подходящо за решения от класа за осигуряване на доходи (RA), предназначени да автоматизират дейностите на компаниите. Съвременни системигаранциите за доходи включват инструменти за откриване на несъответствия и задълбочен анализ на данните, позволяващи своевременно откриване на възможни загуби или изкривяване на информация, които биха могли да доведат до намаляване на финансовите резултати. На този фон руските компании, потвърждавайки наличието на търсене на технологии за големи данни на вътрешния пазар, отбелязват, че факторите, които стимулират развитието на големи данни в Русия, са растежът на данните, ускоряването на вземането на управленски решения и подобряването на тяхното качество.
Какво ви пречи да работите с Big Data
Днес само 0,5% от натрупаните цифрови данни се анализират, въпреки факта, че има обективни проблеми в цялата индустрия, които могат да бъдат решени с помощта на аналитични решенияКлас Big Data. Развитите ИТ пазари вече имат резултати, които могат да се използват за оценка на очакванията, свързани с натрупването и обработката на големи данни.
Разглежда се един от основните фактори, които забавят изпълнението на проекти с големи данни, в допълнение към високата цена проблем при избора на обработени данни: тоест определяне кои данни трябва да бъдат извлечени, съхранени и анализирани и кои трябва да бъдат игнорирани.
Много представители на бизнеса отбелязват, че трудностите при реализирането на проекти за големи данни са свързани с липсата на специалисти - маркетолози и анализатори. Скоростта на възвръщаемост на инвестициите в Big Data пряко зависи от качеството на работа на служителите, ангажирани в задълбочени и прогнозни анализи. Огромният потенциал на данните, които вече съществуват в една организация, често не може да бъде използван ефективно от самите търговци поради остарели бизнес процеси или вътрешни разпоредби. Поради това проектите за големи данни често се възприемат от бизнеса като трудни не само за изпълнение, но и за оценка на резултатите: стойността на събраните данни. Специфичният характер на работата с данни изисква търговците и анализаторите да пренасочат вниманието си от технологиите и създаването на отчети към решаването на конкретни бизнес проблеми.
Поради големия обем и висока скоростпоток от данни, процесът на тяхното събиране включва ETL процедури в реално време. За справка:ETL – отАнглийскиЕкстракт, Трансформирайте, Заредете- буквално "извличане, трансформиране, зареждане") - един от основните процеси в управлението складове за данни, което включва: извличане на данни от външни източници, тяхната трансформация и почистване за задоволяване на нуждите ETL трябва да се разглежда не само като процес на преместване на данни от едно приложение в друго, но и като инструмент за подготовка на данни за анализ.
И тогава въпросите за гарантиране на сигурността на данните, идващи от външни източници, трябва да имат решения, които съответстват на обема на събраната информация. Тъй като методите за анализ на големи данни се развиват само след нарастването на обема на данните, способността на аналитичните платформи да използват нови методи за подготовка и агрегиране на данни играе голяма роля. Това предполага, че например данни за потенциални купувачи или масивно хранилище с данни с история на кликванията върху сайтове за онлайн пазаруване може да представлява интерес за решаване на различни проблеми.
Трудностите не спират
Въпреки всички трудности с внедряването на Big Data, бизнесът възнамерява да увеличи инвестициите в тази област. Както следва от данните на Gartner, през 2013 г. 64% от най-големите компании в света вече са инвестирали или планират да инвестират в внедряването на технологии за големи данни за своя бизнес, докато през 2012 г. те са били 58%. Според изследването на Gartner лидерите в индустриите, инвестиращи в Big Data, са медийни компании, телекомуникации, банки и компании за услуги. Успешни резултати от внедряването на Big Data вече са постигнати от много големи играчи в индустрията за търговия на дребно по отношение на използването на данни, получени с помощта на инструменти за радиочестотна идентификация, логистика и системи за преместване. попълване- натрупване, попълване - R&T), както и от програми за лоялност. Успешният опит в търговията на дребно насърчава други пазарни сектори да намерят нови ефективни начинимонетизиране на големи данни, за да превърне анализа им в ресурс, който работи за развитието на бизнеса. Благодарение на това, според експертите, в периода до 2020 г. инвестициите в управление и съхранение на гигабайт данни ще намалеят от $2 на $0,2, но за изследване и анализ на технологичните свойства на Big Data ще се увеличат само с 40%.
Разходи, представени в различни инвестиционни проектив областта на Big Data, имат различен характер. Разходните позиции зависят от видовете продукти, които се избират въз основа на определени решения. Най-голямата част от разходите в инвестиционните проекти, според експерти, се падат на продукти, свързани със събиране, структуриране на данни, почистване и управление на информация.
Как се прави
Има много комбинации от софтуер и хардуер, които ви позволяват да създавате ефективни решения Big Data за различни бизнес дисциплини: от социални медии и мобилни приложения, преди прогнозен анализи визуализация на бизнес данни. Важно предимство на Big Data е съвместимостта на новите инструменти с бази данни, широко използвани в бизнеса, което е особено важно при работа с междудисциплинарни проекти, като организиране на многоканални продажби и поддръжка на клиенти.
Последователността на работа с Big Data се състои от събиране на данни, структуриране на получената информация с помощта на отчети и табла за управление, създаване на прозрения и контексти и формулиране на препоръки за действие. Тъй като работата с Big Data е свързана с големи разходи за събиране на данни, резултатът от обработката на които е предварително неизвестен, основната задача е ясно да се разбере за какво са данните, а не колко от тях са налични. В този случай събирането на данни се превръща в процес на получаване на информация, изключително необходима за решаване на конкретни проблеми.
Например доставчиците на телекомуникационни услуги събират огромно количество данни, включително геолокация, която се актуализира постоянно. Тази информация може да бъде от търговски интерес за рекламните агенции, които могат да я използват за предоставяне на целева и местна реклама, както и за търговци на дребно и банки. Такива данни могат да играят важна роля при вземането на решение за откриване на търговски обект на определено място въз основа на данни за наличието на мощен целеви поток от хора. Има пример за измерване на ефективността на рекламата върху външни билбордове в Лондон. Сега обхватът на такава реклама може да бъде измерен само чрез поставяне на хора в близост до рекламни конструкции със специално устройство, което брои минувачите. В сравнение с този тип измерване на рекламната ефективност, мобилен оператормного повече възможности - той знае точно местоположението на своите абонати, знае техните демографски характеристики, пол, възраст, семейно положение и т.н.
Въз основа на тези данни в бъдеще има перспектива да се промени съдържанието на рекламното съобщение, като се използват предпочитанията на конкретно лице, минаващо покрай билборда. Ако данните покажат, че преминаващ човек пътува много, тогава може да му се покаже реклама на курорт. Организаторите на футболен мач могат само да преценят броя на феновете, когато дойдат на мача. Но ако имаха възможност да поискат от оператора клетъчна комуникацияинформация за това къде са били посетителите час, ден или месец преди мача, това ще даде възможност на организаторите да планират места за рекламиране на следващите мачове.
Друг пример е как банките могат да използват големи данни за предотвратяване на измами. Ако клиентът съобщи за загуба на картата и при извършване на покупка с нея, банката вижда в реално време местоположението на телефона на клиента в зоната за покупка, където се извършва транзакцията, банката може да провери информацията в приложението на клиента за да види дали се опитва да го измами. Или обратната ситуация, когато клиент прави покупка в магазин, банката вижда, че картата, използвана за транзакцията, и телефонът на клиента са на едно и също място, банката може да заключи, че собственикът на картата я използва. Благодарение на тези предимства на Big Data, границите на традиционните хранилища за данни се разширяват.
За да вземе успешно решение за внедряване на Big Data решения, една компания трябва да изчисли инвестиционен случай, а това създава големи трудности поради много непознати компоненти. Парадоксът на анализа в такива случаи е предсказване на бъдещето въз основа на миналото, данни за което често липсват. В този случай важен фактор е ясното планиране на вашите първоначални действия:
- Първо, необходимо е да се определи един конкретен бизнес проблем, за който ще се използват технологиите за големи данни; тази задача ще бъде в основата на определянето на правилността на избраната концепция. Трябва да се съсредоточите върху събирането на данни, свързани с тази конкретна задача, и по време на доказването на концепцията можете да използвате различни инструменти, процеси и техники за управление, които ще ви позволят да вземате по-информирани решения в бъдеще.
- Второ, малко вероятно е компания без умения и опит за анализ на данни да може успешно да реализира проект за големи данни. Необходимите знания винаги произтичат от предишен опит в анализите, който е основният фактор, влияещ върху качеството на работа с данни. Културата на използване на данни играе важна роля, тъй като често анализът на информацията разкрива жестоката истиназа бизнеса и за да приемем тази истина и да работим с нея, са необходими разработени методи за работа с данни.
- Трето, стойността на технологиите за големи данни се крие в предоставянето на прозрения Добрите анализатори остават недостиг на пазара. Те обикновено се наричат специалисти, които имат дълбоко разбиране за търговското значение на данните и знаят как да ги използват правилно. Анализът на данни е средство за постигане на бизнес цели и за да разберете стойността на Big Data, трябва да се държите съответно и да разбирате действията си. В този случай големите данни ще осигурят много полезна информацияза потребителите, въз основа на които могат да се вземат решения, полезни за бизнеса.
Въпреки факта, че руският пазар на големи данни едва започва да се оформя, отделни проекти в тази област вече се изпълняват доста успешно. Някои от тях са успешни в областта на събирането на данни, като проекти за Федералната данъчна служба и Tinkoff Credit Systems Bank, други - по отношение на анализа на данни и практическото приложение на резултатите от него: това е проектът Synqera.
Tinkoff Credit Systems Bank реализира проект за внедряване на платформата EMC2 Greenplum, която е инструмент за масови паралелни изчисления. През последните години банката завиши изискванията към скоростта на обработка на натрупаната информация и анализ на данните в реално време, поради високия темп на нарастване на броя на потребителите кредитни карти. Банката обяви планове за разширяване на използването на технологиите за големи данни, по-специално за обработка на неструктурирани данни и работа с тях корпоративна информацияполучени от различни източници.
В момента Федералната данъчна служба на Русия създава аналитичен слой за федералното хранилище на данни. На негова основа единичен информационно пространствои технология за достъп до данъчни данни за статистически и аналитична обработка. По време на изпълнението на проекта се работи за централизиране на аналитична информация от повече от 1200 източника на местно ниво на Федералната данъчна служба.
Още едно интересен примеранализ на големи данни в реално време е руският стартъп Synqera, разработил платформата Simplate. Решението се основава на обработка на големи количества данни, програмата анализира информация за клиентите, тяхната история на покупки, възраст, пол и дори настроение. На касите във верига козметични магазини са монтирани сензорни екранисъс сензори, които разпознават емоциите на клиента. Програмата определя настроението на човек, анализира информация за него, определя времето от деня и сканира базата данни с отстъпки на магазина, след което изпраща целеви съобщения до купувача за промоции и специални оферти. Това решение повишава лоялността на клиентите и увеличава продажбите на търговците.
Ако говорим за чуждестранни успешни случаи, тогава опитът от използването на технологиите за големи данни в компанията Dunkin`Donuts, която използва данни в реално време за продажба на продукти, е интересен в това отношение. Цифровите дисплеи в магазините показват оферти, които се променят всяка минута, в зависимост от времето на деня и наличността на продукта. С помощта на касовите бележки компанията получава данни кои оферти са получили най-голям отзвук от клиентите. Този подход за обработка на данни ни позволи да увеличим печалбите и оборота на стоките в склада.
Както показва опитът от изпълнението на проекти за големи данни, тази област е предназначена за успешно решаване на съвременни бизнес проблеми. В същото време важен фактор за постигане на търговски цели при работа с големи данни е изборът на правилната стратегия, която включва анализи, които идентифицират потребителските заявки, както и използването иновативни технологиив областта на Big Data.
Според глобално проучване, провеждано ежегодно от Econsultancy и Adobe от 2012 г. сред корпоративни търговци, „големите данни“, които характеризират действията на хората в Интернет, могат да направят много. Те могат да оптимизират офлайн бизнес процесите, да помогнат да се разбере как собствениците на мобилни устройства ги използват за търсене на информация или просто да „направят маркетинга по-добър“, т.е. по-ефикасно. Освен това последната функция става все по-популярна от година на година, както следва от диаграмата, която представихме.
Основните области на работа на интернет търговците по отношение на връзките с клиентите

Източник: Econsultancy и Adobe, изд– emarketer.com
Имайте предвид, че националността на респондентите от голямо значениене притежава. Както показва проучване, проведено от KPMG през 2013 г., делът на „оптимистите“, т.е. тези, които използват Big Data при разработване на бизнес стратегия, са 56%, а вариациите от регион на регион са малки: от 63% в страните от Северна Америка до 50% в EMEA.
Използване на големи данни в различни региони на света

Източник: KPMG, изд– emarketer.com
Междувременно отношението на търговците към такива „модни тенденции“ донякъде напомня на добре позната шега:
Кажи, Вано, обичаш ли домати?
- Обичам да ям, но не така.
Въпреки факта, че търговците вербално „обичат“ Big Data и изглежда дори ги използват, в действителност „всичко е сложно“, както пишат за сърдечните си привързаности в социалните мрежи.
Според проучване, проведено от Circle Research през януари 2014 г. сред европейски търговци, 4 от 5 респонденти не използват Big Data (въпреки че те, разбира се, „го обичат“). Причините са различни. Малко са закоравелите скептици - 17% и точно толкова са техните антиподи, т.е. онези, които уверено отговарят: „Да“. Останалите се колебаят и съмняват, „блатото“. Те избягват директен отговор под правдоподобни предлози като „още не, но скоро“ или „ще изчакаме, докато другите започнат“.
Използване на големи данни от търговци, Европа, януари 2014 г

източник:dnx, публикувано –emarketer.com
Какво ги обърква? Чисти глупости. Някои (точно половината от тях) просто не вярват на тези данни. Други (също има доста от тях - 55%) намират за трудно да съпоставят набори от „данни“ и „потребители“ един с друг. Някои хора просто имат (политически коректно казано) вътрешна корпоративна бъркотия: данните се лутат без надзор между маркетинговите отдели и ИТ структурите. За други софтуерът не може да се справи с наплива от работа. И така нататък. Тъй като общите дялове значително надхвърлят 100%, е ясно, че ситуацията на „множество бариери“ не е необичайна.
Бариери пред използването на Big Data в маркетинга

източник:dnx, публикувано –emarketer.com
Така че трябва да признаем, че за момента „Big Data“ е голям потенциал, от който все още трябва да се възползваме. Между другото, това може да е причината Big Data да губи ореола си на „модна тенденция“, както се вижда от проучване, проведено от компанията Econsultancy, за което вече споменахме.
Най-значимите тенденции в дигиталния маркетинг 2013-2014

Източник: Econsultancy и Adobe
На тяхно място идва друг цар – контент маркетинга. Колко дълго?
Не може да се каже, че Big Data е някакво фундаментално ново явление. Големи източници на данни съществуват от много години: бази данни за покупки на клиенти, кредитна история, начин на живот. И години наред учените използват тези данни, за да помогнат на компаниите да оценят риска и да предскажат бъдещите нужди на клиентите. Днес обаче ситуацията се е променила в два аспекта:
Появиха се по-сложни инструменти и техники за анализиране и комбиниране на различни набори от данни;
Тези аналитични инструменти се допълват от лавина от нови източници на данни, водени от цифровизацията на почти всички методи за събиране на данни и измерване.
Обхватът на наличната информация е едновременно вдъхновяващ и плашещ за изследователите, израснали в структурирана изследователска среда. Настроенията на потребителите се улавят от уебсайтове и всякакви социални медии. Фактът на гледане на реклама се записва не само декодери, но също и с помощта на цифрови тагове и мобилни устройствакомуникация с телевизора.
Данните за поведението (като обем на разговорите, навици за пазаруване и покупки) вече са достъпни в реално време. По този начин голяма част от това, което преди можеше да бъде получено чрез изследване, сега може да се научи с помощта на големи източници на данни. И всички тези информационни активи се генерират постоянно, независимо от каквито и да е изследователски процеси. Тези промени ни карат да се чудим дали големите данни могат да заменят класическото пазарно проучване.
Не става въпрос за данните, а за въпросите и отговорите.
Преди да осъдим класическото изследване, трябва да си напомним, че не наличието на определени активи от данни е критично, а нещо друго. Какво точно? Способността ни да отговаряме на въпроси, ето какво. Едно забавно нещо в новия свят на големите данни е, че резултатите, получени от нови активи от данни, водят до още повече въпроси и тези въпроси обикновено намират най-добър отговор от традиционните изследвания. По този начин, с нарастването на големите данни, виждаме паралелно увеличаване на наличността и нуждата от „малки данни“, които могат да дадат отговори на въпроси от света на големите данни.
Помислете за ситуацията: голям рекламодател непрекъснато следи трафика на магазина и обемите на продажбите в реално време. Съществуващите изследователски методологии (при които анкетираме участниците в панелите относно техните мотивации за покупка и поведение на място за продажба) ни помагат да се насочваме по-добре към специфични сегменти на купувачите. Тези техники могат да бъдат разширени, за да включат по-широк набор от активи с големи данни, до точката, в която големите данни се превръщат в средство за пасивно наблюдение, а изследването се превръща в метод за текущо, тясно фокусирано разследване на промени или събития, които изискват проучване. Ето как големите данни могат да освободят изследванията от ненужната рутина. Първичните изследвания вече не трябва да се фокусират върху случващото се (големите данни ще направят това). Вместо това първичните изследвания могат да се фокусират върху обяснението защо наблюдаваме определени тенденции или отклонения от тенденциите. Изследователят ще може да мисли по-малко за получаване на данни и повече за това как да ги анализира и използва.
В същото време виждаме, че големите данни могат да решат един от най-големите ни проблеми: проблемът с прекалено дългите проучвания. Проверката на самите проучвания показа, че прекалено раздутите изследователски инструменти имат отрицателно въздействие върху качеството на данните. Въпреки че много експерти отдавна са признали този проблем, те неизменно отговарят с фразата „Но имам нужда от тази информация за висшето ръководство“ и дългите интервюта продължават.
В света на големите данни, където количествените показатели могат да бъдат получени чрез пасивно наблюдение, този въпрос става спорен. Отново, нека помислим за всички тези проучвания относно консумацията. Ако големите данни ни дават представа за потреблението чрез пасивно наблюдение, тогава първичните проучвания вече не трябва да събират този вид информация и най-накрая можем да подкрепим нашата визия за кратки проучвания с нещо повече от пожелателно мислене.
Big Data се нуждае от вашата помощ
И накрая, „голям“ е само една характеристика на големите данни. Характеристиката „голям“ се отнася до размера и мащаба на данните. Разбира се, това е основната характеристика, тъй като обемът на тези данни надхвърля всичко, с което сме работили преди. Но други характеристики на тези нови потоци от данни също са важни: те често са лошо форматирани, неструктурирани (или в най-добрия случай частично структурирани) и пълни с несигурност. Нововъзникваща област на управление на данни, уместно наречена анализ на обекти, се занимава с проблема с пресичането на шума в големите данни. Неговата работа е да анализира тези набори от данни и да разбере колко наблюдения се отнасят за едно и също лице, кои наблюдения са текущи и кои са използваеми.
Този тип почистване на данни е необходимо за премахване на шум или грешни данни при работа с големи или малки активи от данни, но не е достатъчно. Трябва също така да създадем контекст около активите с големи данни въз основа на нашия предишен опит, анализи и знания за категориите. Всъщност много анализатори посочват способността за управление на несигурността, присъща на големите данни, като източник на конкурентно предимство, тъй като позволява вземането на по-добри решения.
Това е мястото, където първичните изследвания не само се оказват освободени от големите данни, но също така допринасят за създаването и анализа на съдържание в големите данни.
Основен пример за това е приложението на нашата нова фундаментално различна рамка за капитал на марката към социалните медии (говорим за разработен вМилуърд кафявонов подход за измерване на капитала на маркатаThe Смислено Различен рамка– „Парадигмата на значимата разлика“ –Р & T ). Моделът е поведенчески тестван в рамките на конкретни пазари, внедрен на стандартна основа и може лесно да се приложи към други маркетингови вертикали и информационни системи за подпомагане на вземането на решения. С други думи, нашият модел на капитала на марката, базиран на (макар и не изключително въз основа) на проучване, има всички характеристики, необходими за преодоляване на неструктурирания, несвързан и несигурен характер на големите данни.
Помислете за данните за потребителските настроения, предоставени от социалните медии. В необработена форма пиковете и спадовете в потребителските настроения много често са минимално свързани с офлайн измерванията на капитала и поведението на марката: просто има твърде много шум в данните. Но ние можем да намалим този шум, като приложим нашите модели за потребителско значение, диференциация на марката, динамика и отличителност към необработени данни за потребителските настроения – начин за обработка и агрегиране на данни от социалните медии по тези измерения.
След като данните са организирани според нашата рамка, идентифицираните тенденции обикновено се привеждат в съответствие с офлайн стойността на марката и поведенческите мерки. По същество данните от социалните медии не могат да говорят сами за себе си. Използването им за тази цел изисква нашия опит и модели, изградени около марки. Когато социалните медии ни предоставят уникална информация, изразена на езика, който потребителите използват, за да опишат марките, ние трябва да използваме този език, когато създаваме нашите изследвания, за да направим първичните изследвания много по-ефективни.
Предимства на освободените изследвания
Това ни връща към това как големите данни не толкова заместват изследванията, колкото ги освобождават. Изследователите ще бъдат освободени от необходимостта да създават ново проучване за всеки нов случай. Постоянно растящите активи с големи данни могат да се използват за различни изследователски теми, което позволява последващи първични изследвания да навлязат по-дълбоко в темата и да запълнят съществуващите пропуски. Изследователите ще бъдат освободени от необходимостта да разчитат на прекалено завишени проучвания. Вместо това те могат да използват кратки анкети и да се фокусират върху най-важните параметри, което подобрява качеството на данните.
С това освобождаване изследователите ще могат да използват установените си принципи и идеи, за да добавят прецизност и значение на активите с големи данни, което води до нови области за проучвания. Този цикъл трябва да доведе до по-добро разбиране на редица стратегически въпроси и, в крайна сметка, движение към това, което винаги трябва да бъде нашата основна цел - да информираме и да подобрим качеството на марката и комуникационните решения.
Обикновено, когато говорят за сериозна аналитична обработка, особено ако използват термина Data Mining, те имат предвид, че има огромно количество данни. Като цяло това не е така, тъй като доста често трябва да обработвате малки набори от данни и намирането на модели в тях не е по-лесно, отколкото в стотици милиони записи. Въпреки че няма съмнение, че необходимостта от търсене на модели в големи бази данни усложнява и без това нетривиалната задача на анализа.
Тази ситуация е особено типична за бизнеса, свързан с търговия на дребно, телекомуникации, банки, интернет. Техните бази данни натрупват огромно количество информация, свързана с транзакции: чекове, плащания, обаждания, регистрационни файлове и др.
Няма универсални методи за анализ или алгоритми, подходящи за всички случаи и всякакво количество информация. Методите за анализ на данни се различават значително по производителност, качество на резултатите, лекота на използване и изисквания към данните. Оптимизацията може да се извърши на различни нива: оборудване, бази данни, аналитична платформа, подготовка на изходни данни, специализирани алгоритми. Анализът на голям обем данни изисква специален подход, тъй като... технически е трудно да се обработват само с " груба сила“, т.е. използване на по-мощно оборудване.
Разбира се, възможно е да се увеличи скоростта на обработка на данни поради по-ефективен хардуер, особено след като съвременните сървъри и работни станции използват многоядрени процесори, RAMзначителен размер и мощен дискови масиви. Има обаче много други начини за обработка на големи количества данни, които позволяват повишена мащабируемост и не изискват безкрайно обновяванеоборудване.
Възможности на СУБД
Съвременните бази данни включват различни механизми, чието използване значително ще увеличи скоростта на аналитичната обработка:
- Изчисление на предварителни данни. Информацията, която най-често се използва за анализ, може да бъде изчислена предварително (например през нощта) и съхранена във форма, подготвена за обработка на сървъра на базата данни под формата на многомерни кубове, материализирани изгледи и специални таблици.
- Кеширане на таблици в RAM. Данни, които заемат малко място, но често са достъпни по време на процеса на анализ, например директории, могат да бъдат кеширани в RAM с помощта на инструменти за бази данни. Това намалява многократно извикванията към по-бавната дискова подсистема.
- Разделяне на таблици на дялове и таблични пространства. Можете да поставите данни, индекси и помощни таблици на отделни дискове. Това ще позволи на СУБД да чете и записва информация на дискове паралелно. Освен това таблиците могат да бъдат разделени на дялове, така че при достъп до данни да има минимален брой дискови операции. Например, ако най-често анализираме данни за последния месец, тогава можем логично да използваме една таблица с исторически данни, но физически да я разделим на няколко дяла, така че при достъп до месечните данни да се чете малък дял и да няма достъпи към всички исторически данни.
Това е само част от възможностите, които съвременните СУБД предоставят. Можете да увеличите скоростта на извличане на информация от база данни по дузина други начини: рационално индексиране, изграждане на планове за заявки, паралелна обработка на SQL заявки, използване на клъстери, подготовка на анализирани данни с помощта на съхранени процедури и тригери от страна на сървъра на база данни и т.н. . Нещо повече, много от тези механизми могат да се използват, като се използват не само „тежки“ СУБД, но също така безплатни бази данниданни.
Комбиниране на модели
Възможностите за увеличаване на скоростта не се ограничават до оптимизиране на производителността на базата данни, много може да се направи чрез комбиниране на различни модели. Известно е, че скоростта на обработка е значително свързана със сложността на използвания математически апарат. Колкото по-опростени механизми за анализ се използват, толкова по-бързо се анализират данните.
Възможно е да се конструира сценарий за обработка на данни по такъв начин, че данните да бъдат „прекарани“ през сито от модели. Тук се прилага проста идея: не губете време да обработвате това, което не е необходимо да анализирате.
Първо се използват най-простите алгоритми. Част от данните, които могат да бъдат обработени с помощта на такива алгоритми и които е безсмислено да се обработват с повече комплексни методи, се анализира и изключва от по-нататъшна обработка. Останалите данни се прехвърлят към следващия етап на обработка, където се използват по-сложни алгоритми и така нататък по веригата. В последния възел на скрипта за обработка се използват най-сложните алгоритми, но обемът на анализираните данни е многократно по-малък от първоначалната извадка. В резултат на това общото време, необходимо за обработка на всички данни, намалява с порядъци.
Да дадем практически примеризползвайки този подход. При решаването на проблема с прогнозирането на търсенето първоначално се препоръчва да се извърши XYZ анализ, който ви позволява да определите колко стабилно е търсенето на различни стоки. Продуктите от група X се продават доста последователно, така че прилагането на алгоритми за прогнозиране към тях ни позволява да получим висококачествена прогноза. Продуктите от група Y се продават по-малко последователно, може би си струва да се изградят модели за тях не за всяка статия, а за групата, това ви позволява да изгладите времевите редове и да осигурите работата на алгоритъма за прогнозиране. Продуктите от група Z се продават хаотично, така че изобщо не е необходимо да се изграждат прогнозни модели за тях; необходимостта от тях трябва да се изчислява въз основа на прости формули, например средни месечни продажби.
Според статистиката около 70% от асортимента се състои от продукти от група Z. Други около 25% са продукти от група Y, а само около 5% са продукти от група X. Така конструирането и приложението на сложни модели е актуално за максимум 30% от продуктите. Следователно използването на описания по-горе подход ще намали времето за анализ и прогнозиране 5-10 пъти.
Паралелна обработка
Друга ефективна стратегия за обработка на големи количества данни е да се разделят данните на сегменти и да се изградят модели за всеки сегмент поотделно, след което да се комбинират резултатите. Най-често в големи обеми от данни могат да бъдат идентифицирани няколко подмножества, които се различават едно от друго. Това могат да бъдат например групи клиенти, продукти, които се държат по подобен начин и за които е препоръчително да се изгради един модел.
В този случай, вместо да изграждате един сложен модел за всеки, можете да изградите няколко прости за всеки сегмент. Този подход ви позволява да увеличите скоростта на анализа и да намалите изискванията за памет чрез обработка на по-малки количества данни с едно преминаване. Освен това в този случай аналитичната обработка може да бъде успоредна, което също има положителен ефект върху изразходваното време. Освен това различни анализатори могат да изграждат модели за всеки сегмент.
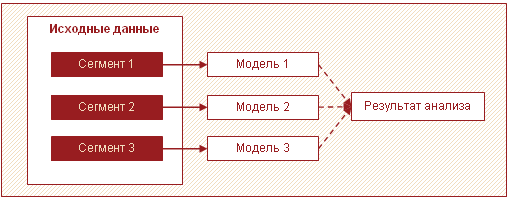
В допълнение към увеличаването на скоростта, този подход има още едно важно предимство - няколко относително прости модела поотделно са по-лесни за създаване и поддръжка от един голям. Можете да изпълнявате модели на етапи, като по този начин получавате първите резултати за възможно най-кратко време.
Представителни проби
Ако са налични големи обеми данни, не цялата информация може да се използва за изграждане на модел, а определено подмножество - представителна извадка. Правилно подготвената представителна проба съдържа необходимата информация за изграждане на висококачествен модел.
Процесът на аналитична обработка е разделен на 2 части: изграждане на модел и прилагане на конструирания модел към нови данни. Изграждането на сложен модел е ресурсоемък процес. В зависимост от използвания алгоритъм, данните се кешират, сканират се хиляди пъти, изчисляват се много помощни параметри и т.н. Прилагането на вече изграден модел към нови данни изисква десетки и стотици пъти по-малко ресурси. Много често това се свежда до изчисляване на няколко прости функции.
По този начин, ако моделът е изграден върху относително малки набори и впоследствие приложен към целия набор от данни, тогава времето за получаване на резултата ще бъде намалено с порядъци в сравнение с опит за пълна обработка на целия съществуващ набор от данни.

За получаване на представителни проби има специални методи, например вземане на проби. Използването им дава възможност да се увеличи скоростта на аналитичната обработка, без да се жертва качеството на анализа.
Резюме
Описаните подходи са само малка част от методите, които ви позволяват да анализирате огромни количества данни. Има и други методи, например използването на специални мащабируеми алгоритми, йерархични модели, обучение на прозорци и др.
Анализ огромни базиУправлението на данни е нетривиална задача, която в повечето случаи не може да бъде разрешена директно, но съвременните бази данни и аналитични платформи предлагат много методи за решаване на този проблем. Когато се използват разумно, системите са способни да обработват терабайти данни с приемлива скорост.
Колона от преподаватели по HSE за митове и случаи на работа с големи данни
Към отметки
Преподавателите в Училището по нови медии към Националния изследователски университет Висше училище по икономика Константин Романов и Александър Пятигорски, който е и директор на дигиталната трансформация в Beeline, написаха колона за сайта за основните погрешни схващания за големите данни - примери за използване технологията и инструментите. Авторите предполагат, че изданието ще помогне на мениджърите на компаниите да разберат тази концепция.
Митове и погрешни схващания за големите данни
Големите данни не са маркетинг
Терминът Big Data стана много модерен – използва се в милиони ситуации и със стотици различни интерпретации, често несвързани с това какво представлява. Понятията често се подменят в главите на хората и Big Data се бърка с маркетингов продукт. Освен това в някои компании Big Data е част от маркетинговия отдел. Резултатът от анализа на големи данни наистина може да бъде източник за маркетингова дейност, но нищо повече. Нека да видим как работи.
Ако идентифицирахме списък с тези, които са закупили стоки на стойност над три хиляди рубли в нашия магазин преди два месеца и след това изпратиха на тези потребители някаква оферта, тогава това е типичен маркетинг. Ние извличаме ясен модел от структурните данни и го използваме за увеличаване на продажбите.
Въпреки това, ако комбинираме CRM данни с поточна информация от, например, Instagram, и я анализираме, откриваме модел: човек, който е намалил активността си в сряда вечерта и чиято последна снимка показва котенца, трябва да направи определена оферта. Това вече ще е Big Data. Намерихме тригер, предадохме го на търговците и те го използваха за собствените си цели.
От това следва, че технологията обикновено работи с неструктурирани данни и дори данните да са структурирани, системата продължава да търси скрити модели в тях, което маркетингът не прави.
Големите данни не са ИТ
Втората крайност на тази история: Големите данни често се бъркат с ИТ. Това се дължи на факта, че в руски компанииПо правило ИТ специалистите са двигателите на всички технологии, включително големите данни. Следователно, ако всичко се случва в този отдел, компанията като цяло остава с впечатлението, че това е някаква ИТ дейност.
Всъщност тук има фундаментална разлика: Big Data е дейност, насочена към получаване на конкретен продукт, който изобщо не е свързан с ИТ, въпреки че технологията не може да съществува без него.
Big Data не винаги е събиране и анализ на информация
Има още едно погрешно схващане за големите данни. Всеки разбира, че тази технология включва големи количества данни, но не винаги е ясно какъв вид данни има предвид. Всеки може да събира и използва информация; сега това е възможно не само във филми за, но и във всяка, дори много малка компания. Единственият въпрос е какво точно да съберете и как да го използвате в своя полза.
Но трябва да се разбере, че Голяма технологияДанните няма да представляват събиране и анализ на абсолютно всякаква информация. Например, ако събирате данни за конкретен човек в социалните мрежи, това няма да е Big Data.
Какво всъщност е Big Data?
Big Data се състои от три елемента:
- данни;
- анализи;
- технологии.
Big Data не е само един от тези компоненти, а комбинация от трите елемента. Хората често заместват понятията: някои вярват, че Big Data са само данни, други смятат, че това са технологии. Но всъщност, без значение колко данни събирате, не можете да направите нищо с тях необходими технологиии анализатори. Ако има добри анализи, но няма данни, е още по-лошо.
Ако говорим за данни, това не са само текстове, но и всички снимки, публикувани в Instagram, и като цяло всичко, което може да се анализира и използва за различни цели и задачи. С други думи, Data се отнася до огромни обеми вътрешни и външни данни от различни структури.
Нужен е и анализ, защото задачата на Big Data е да изгради някакви модели. Тоест анализът е идентифициране на скрити зависимости и търсене на нови въпроси и отговори въз основа на анализа на целия обем от разнородни данни. Освен това Big Data поставя въпроси, които не могат да бъдат директно извлечени от тези данни.
Когато става въпрос за изображения, фактът, че публикувате снимка, на която сте облечени със синя тениска, не означава нищо. Но ако използвате фотография за моделиране на големи данни, може да се окаже, че точно сега трябва да предложите заем, защото във вашата социална група подобно поведение показва определено явление в действие. Следователно „голи“ данни без анализи, без идентифициране на скрити и неочевидни зависимости не са Big Data.
Така че имаме големи данни. Масивът им е огромен. Имаме и анализатор. Но как можем да сме сигурни, че от тези необработени данни ще стигнем до конкретно решение? За целта се нуждаем от технологии, които ни позволяват не само да ги съхраняваме (а това беше невъзможно преди), но и да ги анализираме.
Просто казано, ако имате много данни, ще ви трябват технологии, например Hadoop, които правят възможно съхраняването на цялата информация в оригиналната й форма за по-късен анализ. Този вид технология възникна в интернет гигантите, тъй като те бяха първите, които се сблъскаха с проблема със съхраняването на голямо количество данни и анализирането им за последваща монетизация.
В допълнение към инструментите за оптимизирано и евтино съхранение на данни, имате нужда от аналитични инструменти, както и добавки към използваната платформа. Например, цяла екосистема от свързани проекти и технологии вече се е формирала около Hadoop. Ето някои от тях:
- Pig е декларативен език за анализ на данни.
- Hive - анализ на данни с помощта на език, подобен на SQL.
- Oozie - работен процес на Hadoop.
- Hbase е база данни (нерелационна), подобна на Google Big Table.
- Mahout - машинно обучение.
- Sqoop - прехвърляне на данни от RSDB към Hadoop и обратно.
- Flume - прехвърляне на регистрационни файлове към HDFS.
- Zookeeper, MRUnit, Avro, Giraph, Ambari, Cassandra, HCatalog, Fuse-DFS и т.н.
Всички тези инструменти са достъпни за всички безплатно, но има и редица платени добавки.
Освен това са необходими специалисти: разработчик и анализатор (т.нар. Data Scientist). Необходим е и мениджър, който да разбере как да приложи този анализ за решаване на конкретен проблем, защото сам по себе си той е напълно безсмислен, ако не е интегриран в бизнес процесите.
И тримата служители трябва да работят в екип. Мениджър, който дава на специалист по Data Science задачата да намери определен модел, трябва да разбере, че не винаги ще намери точно това, от което се нуждае. В този случай мениджърът трябва да слуша внимателно какво е открил Data Scientist, тъй като често неговите открития се оказват по-интересни и полезни за бизнеса. Вашата работа е да приложите това към бизнес и да направите продукт от него.
Въпреки факта, че сега има много различни видове машини и технологии, крайното решение винаги остава за човека. За да направите това, информацията трябва да бъде визуализирана по някакъв начин. Има доста инструменти за това.
Най-показателният пример са геоаналитичните доклади. Компанията Beeline работи много с правителствата на различни градове и региони. Много често тези организации поръчват доклади като „Задръстване на определено място“.
Ясно е, че такъв доклад трябва да достигне до държавните органи в проста и разбираема форма. Ако им предоставим огромна и напълно неразбираема таблица (т.е. информация във вида, в който я получаваме), те едва ли ще купят такъв отчет - той ще бъде напълно безполезен, те няма да получат от него знанието, че искаха да получат.
Следователно, колкото и добри да са специалистите по данни и каквито и модели да открият, вие няма да можете да работите с тези данни без добри инструменти за визуализация.
Източници на данни
Масивът от получени данни е много голям, така че може да се раздели на няколко групи.
Вътрешни фирмени данни
Въпреки че 80% от събраните данни принадлежат към тази група, този източник не винаги се използва. Често това са данни, които на пръв поглед изобщо не са необходими на никого, например регистрационни файлове. Но ако ги погледнете от различен ъгъл, понякога можете да откриете неочаквани модели в тях.
Shareware източници
Това включва данни социални мрежи, интернет и всичко, където можете да влезете безплатно. Защо е безплатна за споделяне? От една страна, тези данни са достъпни за всеки, но ако сте голяма компания, тогава получаването им в размер на абонатна база от десетки хиляди, стотици или милиони клиенти вече не е лесна задача. Следователно има платени услугида предостави тези данни.
Платени източници
Това включва компании, които продават данни за пари. Това може да са телекоми, DMP, интернет компании, кредитни бюра и агрегатори. В Русия телекомите не продават данни. Първо, това е икономически неизгодно, и второ, това е забранено от закона. Следователно те продават резултатите от тяхната обработка, например геоаналитични доклади.
Отворени данни
Държавата се съобразява с бизнеса и му дава възможност да използва данните, които събира. Това е развито в по-голяма степен на Запад, но Русия в това отношение също е в крак с времето. Например, има Портал за отворени данни на правителството на Москва, където се публикува информация за различни съоръжения на градската инфраструктура.
За жителите и гостите на Москва данните се представят в таблична и картографска форма, а за разработчиците - в специални машинночетими формати. Докато проектът работи в ограничен режим, той се развива, което означава, че е и източник на данни, които можете да използвате за вашите бизнес задачи.
Проучване
Както вече беше отбелязано, задачата на Big Data е да намери модел. Често изследванията, проведени по света, могат да се превърнат в опорна точка за намиране на конкретен модел - можете да получите конкретен резултат и да се опитате да приложите подобна логика за вашите собствени цели.
Големите данни са област, в която не са приложими всички закони на математиката. Например „1“ + „1“ не е „2“, а много повече, защото чрез смесване на източници на данни ефектът може значително да се засили.
Примери за продукти
Много хора са запознати с услугата за избор на музика Spotify. Страхотен е, защото не пита потребителите какво е настроението им днес, а по-скоро го изчислява въз основа на източниците, с които разполага. Той винаги знае какво ви трябва сега - джаз или хард рок. Това е ключовата разлика, която му осигурява фенове и го отличава от другите услуги.

Такива продукти обикновено се наричат сетивни продукти – такива, които усещат своите клиенти.
Технологията Big Data се използва и в автомобилната индустрия. Например Tesla прави това - в техните последен моделима автопилот. Компанията се стреми да създаде кола, която сама ще отведе пътника там, където трябва. Без Big Data това е невъзможно, защото ако използваме само данните, които получаваме директно, както прави човек, тогава колата няма да може да се подобри.

Когато сами караме кола, ние използваме нашите неврони, за да вземаме решения въз основа на много фактори, които дори не забелязваме. Например, може да не осъзнаваме защо сме решили да не ускоряваме веднага на зелен светофар, но след това се оказва, че решението е било правилно - кола е профучала покрай вас с бясна скорост и сте избегнали инцидент.
Можете също така да дадете пример за използване на Big Data в спорта. През 2002 г. генералният мениджър на бейзболния отбор на Оукланд Атлетикс, Били Бийн, решава да разчупи парадигмата как да набира спортисти - той подбира и обучава играчи "по числа".
Обикновено мениджърите гледат на успеха на играчите, но в този случай всичко беше различно - за да постигне резултати, мениджърът проучи какви комбинации от спортисти са му необходими, като обърна внимание на индивидуалните характеристики. Освен това той избра спортисти, които сами по себе си нямаха голям потенциал, но отборът като цяло се оказа толкова успешен, че спечели двадесет мача подред.

Режисьорът Бенет Милър впоследствие направи филм, посветен на тази история - „Човекът, който промени всичко“ с участието на Брад Пит.
Технологията Big Data е полезна и във финансовия сектор. Нито един човек в света не може самостоятелно и точно да определи дали си струва да даде заем на някого. За да се вземе решение, се извършва скоринг, тоест изгражда се вероятностен модел, от който може да се разбере дали този човек ще върне парите или не. Освен това точкуването се прилага на всички етапи: можете например да изчислите, че в определен момент дадено лице ще спре да плаща.
Големите данни ви позволяват не само да печелите пари, но и да ги спестявате. По-специално тази технология помогна на германското министерство на труда да намали разходите за обезщетения за безработица с 10 милиарда евро, тъй като след анализ на информацията стана ясно, че 20% от обезщетенията са изплатени незаслужено.
Технологии се използват и в медицината (това е особено характерно за Израел). С помощта на Big Data можете да извършите много по-точен анализ, отколкото може да направи лекар с тридесет години опит.
Всеки лекар, когато поставя диагноза, разчита само на себе си собствен опит. Когато машината прави това, то идва от опита на хиляди такива лекари и всички съществуващи истории на случаи. Той взема предвид от какъв материал е направена къщата на пациента, в кой район живее жертвата, какъв вид дим има и т.н. Тоест отчита много фактори, които лекарите не отчитат.
Пример за използването на големи данни в здравеопазването е проектът Artemis, който се изпълнява от Детската болница в Торонто. Това Информационна система, който събира и анализира данни за бебета в реално време. Машината ви позволява да анализирате 1260 здравни показателя на всяко дете всяка секунда. Този проект е насочен към прогнозиране на нестабилното състояние на детето и предотвратяване на заболявания при децата.
Големите данни също започват да се използват в Русия: например Yandex има подразделение за големи данни. Компанията, съвместно с AstraZeneca и Руското дружество по клинична онкология RUSSCO, стартира платформата RAY, предназначена за генетици и молекулярни биолози. Проектът ни позволява да подобрим методите за диагностициране на рак и идентифициране на предразположеността към рак. Платформата ще стартира през декември 2016 г.
Терминът Big Data обикновено се отнася до всяко количество структурирани, полуструктурирани и неструктурирани данни. Вторият и третият обаче могат и трябва да бъдат поръчани за последващ анализ на информацията. Големите данни не се равняват на действителен обем, но когато говорим за големи данни в повечето случаи имаме предвид терабайти, петабайти и дори екстрабайтове информация. Всеки бизнес може да натрупа това количество данни с течение на времето или, в случаите, когато компанията трябва да получи много информация, в реално време.
Анализ на големи данни
Когато говорим за анализ на Big Data, имаме предвид преди всичко събирането и съхранението на информация от различни източници. Например данни за клиенти, които са направили покупки, техните характеристики, информация за стартирани рекламни компаниии оценка на неговата ефективност, данни контактен център. Да, цялата тази информация може да бъде сравнена и анализирана. Възможно е и необходимо. Но за да направите това, трябва да настроите система, която ви позволява да събирате и трансформирате информация, без да я изкривявате, да я съхранявате и накрая да я визуализирате. Съгласете се, с големи данни таблиците, отпечатани на няколко хиляди страници, не са много полезни за вземане на бизнес решения.
1. Пристигане на големи данни
Повечето услуги, които събират информация за действията на потребителите, имат възможност за експортиране. За да се гарантира, че те пристигат в компанията в структурирана форма, се използват различни системи, например Alteryx. Този софтуер ви позволява да получавате автоматичен режиминформация, обработват я, но най-важното – превръщат я в правилния типи формата без изкривяване.
2. Съхранение и обработка на големи данни
Почти винаги при събирането на голямо количество информация възниква проблемът с нейното съхранение. От всички платформи, които проучихме, нашата компания предпочита Vertica. За разлика от други продукти, Vertica е в състояние бързо да „върне“ съхраняваната в него информация. Недостатъците включват дълъг запис, но при анализ на големи данни скоростта на връщане излиза на преден план. Например, ако говорим за компилация с помощта на петабайт информация, скоростта на качване е една от най-важните характеристики.
3. Визуализация на големи данни
И накрая, третият етап от анализа на големи обеми данни е . За да направите това, имате нужда от платформа, която може визуално да отразява цялата получена информация в удобна форма. Според нас само един софтуерен продукт може да се справи със задачата - Tableau. Със сигурност един от най-добрите на днесрешение, което може да показва визуално всяка информация, превръщайки работата на компанията в триизмерен модел, събирайки действията на всички отдели в една взаимозависима верига (можете да прочетете повече за възможностите на Tableau).
Вместо това, нека отбележим, че почти всяка компания вече може да създаде свои собствени Big Data. Анализът на големи данни вече не е сложен и скъп процес. Ръководството на компанията вече е длъжно да формулира правилно въпросите към събрана информация, докато на практика не остават невидими сиви зони.
Изтеглете Tableau