استفاده ترکیبی از تنظیم کننده pid و فیلتر کالمن. استفاده از فیلتر کالمن برای پردازش توالی مختصات GPS. ماتریس کوواریانس نویز اندازه گیری
Random Forest یکی از الگوریتم های داده کاوی مورد علاقه من است. اولاً، فوق العاده همه کاره است، می توان از آن برای حل مشکلات رگرسیون و طبقه بندی استفاده کرد. جستجو برای ناهنجاری ها و انتخاب پیش بینی کننده ها. ثانیاً، این یک الگوریتم است که اعمال نادرست آن واقعاً دشوار است. صرفاً به این دلیل که برخلاف سایر الگوریتمها، پارامترهای قابل تنظیم کمی دارد. و با این حال در ذات خود به طرز شگفت آوری ساده است. در عین حال، دقت قابل توجهی دارد.
ایده چنین الگوریتم شگفت انگیزی چیست؟ ایده ساده است: فرض کنید الگوریتم بسیار ضعیفی داریم. اگر با استفاده از این الگوریتم ضعیف تعداد زیادی مدل مختلف بسازیم و نتیجه پیشبینیهای آنها را میانگینگیری کنیم، نتیجه نهایی بسیار بهتر خواهد بود. این به اصطلاح یادگیری گروهی در عمل است. بنابراین الگوریتم جنگل تصادفی "جنگل تصادفی" نامیده می شود، برای داده های دریافتی، درخت های تصمیم گیری زیادی ایجاد می کند و سپس نتیجه پیش بینی های آنها را میانگین می کند. نکته مهم در اینجا عنصر تصادفی بودن در ایجاد هر درخت است. به هر حال، واضح است که اگر تعداد زیادی درخت یکسان ایجاد کنیم، نتیجه میانگین گیری آنها دقت یک درخت را خواهد داشت.
او چگونه کار می کند؟ فرض کنید مقداری داده ورودی داریم. هر ستون مربوط به برخی از پارامترها، هر ردیف مربوط به برخی از عناصر داده است.
میتوانیم بهطور تصادفی تعدادی ستون و ردیف از کل مجموعه داده انتخاب کنیم و از آنها یک درخت تصمیم بسازیم.

پنجشنبه 10 می 2012
پنجشنبه 12 ژانویه 2012

این در واقع تمام است. پرواز 17 ساعته تمام شده است، روسیه در خارج از کشور باقی مانده است. و از پنجره یک آپارتمان دنج 2 خوابه، سانفرانسیسکو، دره معروف سیلیکون، کالیفرنیا، ایالات متحده آمریکا به ما نگاه می کند. بله، به همین دلیل است که اخیراً زیاد ننوشتم. ما حرکت کردیم.
همه چیز در آوریل 2011 زمانی که من یک مصاحبه تلفنی با Zynga داشتم شروع شد. سپس همه چیز شبیه نوعی بازی به نظر می رسید که هیچ ربطی به واقعیت نداشت و من حتی نمی توانستم تصور کنم که به چه چیزی منجر می شود. در ژوئن 2011، زینگا وارد مسکو شد و یک سری مصاحبه انجام داد، حدود 60 کاندیدایی که مصاحبه تلفنی را پشت سر گذاشتند در نظر گرفته شدند و حدود 15 نفر از بین آنها انتخاب شدند (تعداد دقیق را نمی دانم، بعداً یک نفر نظر خود را تغییر داد. کسی بلافاصله امتناع کرد). مصاحبه به طرز شگفت آوری ساده بود. هیچ کار برنامه نویسی برای شما، هیچ سؤال پیچیده ای در مورد شکل دریچه ها، عمدتاً توانایی چت آزمایش شد. و دانش، به نظر من، فقط سطحی ارزیابی شد.
و سپس دزدی شروع شد. ابتدا منتظر نتایج، سپس پیشنهاد، سپس تایید LCA، سپس تایید دادخواست برای ویزا، سپس مدارک از ایالات متحده، سپس خط سفارت، سپس بررسی اضافی، سپس ویزا گاهی به نظرم رسید که حاضرم همه چیز را رها کنم و گل بزنم. گاهی شک داشتم که آیا ما به این آمریکا نیاز داریم، زیرا روسیه هم بد نیست. کل فرآیند حدود نیم سال طول کشید، در نهایت در اواسط دسامبر، ویزا دریافت کردیم و شروع به آماده سازی برای خروج کردیم.
دوشنبه اولین روز من در کار جدید بود. این دفتر همه شرایط را دارد که نه تنها برای کار، بلکه برای زندگی نیز وجود دارد. صبحانه، ناهار و شام از سرآشپزهای خودمان، انبوهی از غذاهای متنوع در گوشه و کنار، سالن بدنسازی، ماساژ و حتی آرایشگاه. همه اینها برای کارمندان کاملا رایگان است. بسیاری از آنها با دوچرخه سر کار می آیند و چندین اتاق برای نگهداری وسایل نقلیه مجهز شده است. به طور کلی، من هرگز چنین چیزی را در روسیه ندیده ام. با این حال، هر چیزی قیمت خود را دارد، بلافاصله به ما هشدار داده شد که باید زیاد کار کنیم. آنچه که "خیلی" است، با معیارهای آنها، برای من خیلی روشن نیست.
با این حال، امیدوارم با وجود حجم زیاد کار، در آینده ای قابل پیش بینی بتوانم وبلاگ نویسی را از سر بگیرم و شاید چیزی در مورد زندگی آمریکایی و کار به عنوان برنامه نویس در آمریکا بگویم. صبر کن و ببین. در ضمن، کریسمس و سال نو را به همه شما تبریک می گویم و به زودی شما را می بینم!
برای مثال، بازده سود تقسیمی را چاپ کنید شرکت های روسی. به عنوان قیمت پایه، قیمت پایانی سهم را در روز بسته شدن ثبت در نظر می گیریم. به دلایلی، این اطلاعات در وب سایت Troika در دسترس نیست و بسیار جالب تر از مقادیر مطلق سود سهام است.
توجه! اجرای کد زمان زیادی می برد، زیرا برای هر سهم، باید از سرورهای فینام درخواست بدهید و ارزش آن را دریافت کنید.
نتیجه<- NULL for(i in (1:length(divs[,1]))){ d <- divs if (d$Divs>0) (امتحان (( نقل قول<- getSymbols(d$Symbol, src="Finam", from="2010-01-01", auto.assign=FALSE) if (!is.nan(quotes)){ price <- Cl(quotes) if (length(price)>0) (dd<- d$Divs result <- rbind(result, data.frame(d$Symbol, d$Name, d$RegistryDate, as.numeric(dd)/as.numeric(price), stringsAsFactors=FALSE)) } } }, silent=TRUE) } } colnames(result) <- c("Symbol", "Name", "RegistryDate", "Divs") result

به طور مشابه، می توانید آمار سال های گذشته را بسازید.
رونوشت
1 # 09، سپتامبر 2015 UDC استفاده از فیلتر کالمن برای پردازش توالی مختصات GPS Listerenko R.R., Bachelor Russia, Moscow, MSTU im. N.E. باومن، بخش " نرم افزارکامپیوتر و فناوری اطلاعات» سرپرست: Bekasov D.E.، دستیار روسیه، مسکو، MSTU im. N.E. باومن، دپارتمان نرم افزار کامپیوتر و فناوری اطلاعات وظیفه فیلتر کردن مختصات GPS در حال حاضر از خدمات ردیابی GPS به طور گسترده استفاده می شود که وظیفه آن ردیابی مسیرهای اشیاء مشاهده شده به منظور ذخیره آنها و تکثیر و تجزیه و تحلیل بیشتر آنها است. اما به دلیل خطای سنسور GPS به دلایلی مانند از دست دادن سیگنال از ماهواره، تغییر هندسه مکان ماهواره ها، بازتاب سیگنال، خطاهای محاسباتی و خطاهای گرد کردن، نتیجه نهایی نمی شود. دقیقاً با مسیر شی مطابقت دارد. هم انحرافات جزئی (در 100 متر) وجود دارد که مانع درک اطلاعات بصری در مورد مسیر و تجزیه و تحلیل آن نمی شود و هم انحرافات بسیار قابل توجه (تا 1 کیلومتر، در صورت از دست دادن سیگنال ماهواره ای و استفاده از ایستگاه های پایه بالا). تا چند ده کیلومتر). برای نشان دادن نتیجه الگوریتم ارائه شده در مقاله، مسیری حاوی انحرافات از مکان واقعی بیش از چندین کیلومتر استفاده شده است. به منظور تصحیح چنین خطاهایی، الگوریتمی توسعه یافته است که تبدیل یک دنباله از مختصات را انجام می دهد. داده های ورودی برای الگوریتم دنباله ای از مختصات GPS است. هر مختصات حاوی اطلاعات زیر است که از حسگر دریافت می شود: عرض جغرافیایی طول جغرافیایی آزیموت بر حسب درجه سرعت لحظه ای جسم در نقطه داده شده بر حسب متر بر ثانیه
2 انحراف احتمالی مختصات جسم از مقدار واقعی بر حسب متر زمان دریافت مختصات توسط سنسور نتیجه الگوریتم دنباله ای از مختصات با طول و عرض جغرافیایی اصلاح شده است. به عنوان پایه ای برای ساخت الگوریتم، تصمیم گرفته شد از فیلتر کالمن استفاده شود، زیرا به شما امکان می دهد به طور جداگانه خطاهای اندازه گیری و خطاهای یک فرآیند تصادفی را در نظر بگیرید و همچنین از سرعت شی دریافت شده از سنسور استفاده کنید. ساختمان مدل ریاضیاستفاده از فیلتر کالمن برای استفاده از فیلتر کالمن، لازم است که فرآیند مورد مطالعه به صورت زیر شرح داده شود: = + + (1) = + (2) به یک حالت. بردار اقدامات کنترلی روی فرآیند را توصیف می کند. ماتریس B با ابعاد n l بردار اقدامات کنترلی u را در یک تغییر حالت s ترسیم می کند. یک متغیر تصادفی است که خطاهای فرآیند مورد مطالعه را توصیف می کند، و ~0، که در آن Q ماتریس کوواریانس خطاهای فرآیند است. فرمول (2) اندازه گیری یک فرآیند تصادفی را توصیف می کند. - بردار حالت اندازه گیری شده فرآیند، ماتریس H با ابعاد m n وضعیت فرآیند را به اندازه گیری فرآیند ترسیم می کند. - یک متغیر تصادفی که خطاهای اندازه گیری را مشخص می کند، و ~0، که در آن P ماتریس کوواریانس خطاهای اندازه گیری است. از آنجایی که روند حرکت یک جسم در حال بررسی است، معادله حالت بر اساس معادله حرکت جسم = + +!" #$ % & " جمع آوری می شود. علاوه بر این، هیچ اطلاعات اضافی در مورد فرآیند حرکت وجود ندارد، بنابراین فرض می شود که عمل کنترل 0 است. بردار = + () *، - به عنوان وضعیت فرآیند در نظر گرفته می شود. +، که در آن x، y - مختصات جسم، - پیش بینی سرعت جسم. بنابراین، برای فرآیند مورد بررسی، معادله (1) به شکل زیر است: = + /!، (3)
3 کجا = ! = 3! + 7 " 0 ; 6 2: 6 " / = : 6 0: 6 2: 6 0: , (4)!,4, (5) (6) در این مدل شتاب یک جسم به صورت تصادفی در نظر گرفته می شود. خطای فرآیند مفروضات زیر مطرح می شود: الف) شتاب ها در امتداد محورهای مختلف متغیرهای تصادفی مستقل هستند.)* ب)
4 = AB = C. C E. = C/!!. /. = /C!!. /. از آنجایی که اجزای بردار ak (5) متغیرهای تصادفی مستقل هستند، پس C!!. = " 0 " G. بنابراین فرمول (7) شکل زیر را به خود می گیرد: = / " (8) بردار اندازه گیری zk برای این مسئله به صورت زیر نمایش داده می شود: H I = 0 + J, J (7) 2, (9) که در آن H، I - مختصات جسم دریافت شده از سنسور، J +،J، - سرعت جسم دریافتی از حسگر ماتریس H در فرمول (2) برابر با ماتریس هویت با ابعاد 4 4 در نظر گرفته شده است، زیرا در داخل در چارچوب این کار در نظر گرفته می شود که اندازه گیری یک بردار حالت ترکیبی خطی و برخی خطاهای تصادفی است. ماتریس کوواریانس خطای اندازه گیری R فرض شده است. گزینه هامحاسبه آن استفاده از داده ها در مورد دقت تخمینی اندازه گیری دریافت شده از سنسور است. اعمال فیلتر کالمن در مدل ساخته شده برای اعمال فیلتر، مفاهیم زیر باید معرفی شوند: - تخمین پسینی از وضعیت جسم در زمان k که از نتایج مشاهدات تا و شامل زمان k به دست می آید. L تخمین پسینی تصحیح نشده وضعیت جسم در زمان k است. - یک ماتریس کوواریانس خطای پسینی، که تخمین صحت تخمین بردار حالت به دست آمده را مشخص می کند و شامل برآوردی از واریانس های خطای حالت محاسبه شده و کوواریانس است که روابط شناسایی شده بین پارامترهای حالت سیستم را نشان می دهد. L ماتریس کوواریانس خطای خلفی تعدیل نشده است. ماتریس P0 روی صفر تنظیم می شود، زیرا فرض می شود که موقعیت اولیه شی مشخص است. بولتن علمی و فنی جوانان مجلس فدرال، ISSN
5 یک تکرار فیلتر کالمن شامل دو مرحله است: برون یابی و تصحیح. الف) در مرحله برون یابی، برآورد L از تخمین بردار حالت L و ماتریس کوواریانس خطا L طبق فرمول های زیر محاسبه می شود: L =، (10) L =. +، (11) جایی که ماتریس Ak از فرمول (4) شناخته می شود، ماتریس Qk از فرمول (8) محاسبه می شود. ب) در مرحله تصحیح، ماتریس بهره Kk بر اساس فرمول زیر محاسبه می شود: M = L. L. + (12) که در آن R, H شناخته شده فرض می شود. Kk برای تصحیح تخمین وضعیت شی L و ماتریس کوواریانس خطا L به شرح زیر استفاده می شود: = L + M L، (13) = N M L، (14) که در آن I ماتریس هویت است. لازم به ذکر است که برای استفاده از نسبت های فوق، لازم است که واحدهای اندازه گیری پارامترهای شی درگیر در محاسبات با هم سازگار باشند. با این حال، در داده های اصلی، طول و عرض جغرافیایی در مختصات زاویه ای و سرعت در متریک آورده شده است. علاوه بر این، تعیین شتاب برای محاسبه خطای فرآیند در واحدهای متریک نیز راحت تر است. برای تبدیل سرعت و شتاب به واحدهای زاویه ای از فرمول های وینسنتی استفاده می شود. نتیجه فیلتر در شکل. 1 نمونه ای از یک مسیر را قبل از پردازش نشان می دهد. مشاهده می شود که در این مثالچندین مختصات با درجه خطای بالا وجود دارد که در حضور "قله" مختصات که به طور قابل توجهی از مسیر اصلی حذف شده اند بیان می شود. روی انجیر شکل 2 نتیجه عملیات فیلتر را با این مسیر نشان می دهد.

6 شکل 1. مسیر شی شکل 2. مسیر جسم پس از اعمال فیلتر در نتیجه، عملا هیچ "قله ای" وجود ندارد، به جز بزرگترین آنها که به طور محسوسی کاهش یافت و بقیه مسیر هموار شد. بدین ترتیب با کمک الگوریتم فوق، امکان کاهش میزان اعوجاج مسیر و بهبود کیفیت بصری آن فراهم شد. نتیجه گیری در این مقاله، رویکردی برای تصحیح مختصات GPS با استفاده از فیلتر کالمن در نظر گرفته ایم. با استفاده از الگوریتم فوق، می توان محسوس ترین اعوجاج مسیر را حذف کرد که کاربرد این روش را برای مشکل هموارسازی مسیر و حذف پیک نشان می دهد. با این حال، به منظور بهبود بیشتر کیفیت الگوریتم، پردازش اضافی توالی مختصات به منظور بهبود کیفیت الگوریتم مورد نیاز است.
7 حذف نقاط زائد ناشی از عدم حرکت جسم مشاهده شده. منابع 1. Yadav J., Giri R., Meena L. Error handling in GPS data processing // Mausam Vol. 62. خیر. 1. P Kalman R. E. A New Approach to Linear Filtering and Prediction Problems // Transactions of the ASME Journal of Basic Engineering Vol. 82. خیر. سری D. P.P. Welch G., Bishop G. An Introduction to the Kalman Filter: Tech. هرزه. TR موجود در: دسترسی به Vincenty T. Direct and Inverse Solutions of Geodesics on the Ellipsoid with application of nested equations // Survey Review apr. جلد 23. بدون PP
الگوریتم UDC 519.711.2 برای تخمین پارامترهای وضعیت فضاپیما با استفاده از فیلتر کالمن DI Galkin 1 1 MSTU im. N.E. باومن، مسکو، 155، روسیه شرح ساخت فیلتر کالمن داده شده است
آژانس فدرال برای مقررات فنی و اندازهشناسی استاندارد ملی فدراسیون روسیه GOST R 53608-2009 سیستم ماهوارهای ناوبری جهانی روشها و فنآوریهای اجرا
پیشبینی سری زمان بیزی بر اساس مدلهای فضای ایالتی V I Lobach Belarusian State University Minsk Belarus E-mail: [ایمیل محافظت شده]روش پیش بینی در نظر گرفته شده است
UDC 681.5(07) شناسایی اشیاء دینامیک غیرخطی در حوزه زمان ویاتچنیکوف، وی. کوزوبوتسکی، A.A. نوسنکو، N.V. Plotnikova اطلاعات ناکافی در مورد اشیاء هنگام توسعه آنها
سر. 0.200. شماره. 4 بولتن فرآیندهای کنترل دانشگاه سنت پترزبورگ UDC 539.3 VV کارلین عملکردهای جریمه در مسئله کنترل فرآیند مشاهده. مقدمه. مقاله به مشکل اختصاص داده شده است
UDC 63.1/.7 الگوریتم های پردازش ثانویه اطلاعات در یک ایستگاه رادار با انواع مختلف ماتریس محاسبه مجدد دینامیک در تعیین مختصات زاویه ارتفاع آسمانی A.АLE. مدیر علمی
Udk 5979 + 5933 A از عمروفان همان، ذیل [ایمیل محافظت شده]مدل حرکتی آماری
مقدمه ای بر رباتیک سخنرانی 12. قسمت 2. ناوبری و نقشه برداری. SLAM SLAM همزمان محلی سازی و نقشه برداری (محلی سازی و نقشه برداری همزمان) وظیفه SLAM یکی از
چکیده سخنرانی “سیستم های دینامیکی خطی. فیلتر کالمن در درس تخصصی "روش های ساختاری تحلیل تصویر و سیگنال" 211 لیکبز: برخی از خواص توزیع نرمال. اجازه دهید x R d توزیع شود
سیستم محلی سازی ربات بر اساس دوربین نیمکره ای الکساندر اوچینیکوف، گروه هوآفان رادیو الکترونیک دانشگاه دولتی تولا، تولا، روسیه [ایمیل محافظت شده], [ایمیل محافظت شده]
مجموعه مقالات MAI شماره 84 UDC 57:5198 wwwmairu/science/trudy/ تعیین خطاهای یک سیستم ناوبری اینرسی بدون گیمبال در حالت تاکسی و شتاب Vavilova NB* Golovan AA Kalchenko AO** Moskovsky
# 08، آگوست 2016 UDC 004.93"1 عادی سازی داده های دوربین سه بعدی با استفاده از روش مؤلفه اصلی برای حل مشکل تشخیص وضعیت ها و رفتار کاربران خانه هوشمند Malykh D.A.، دانشجوی روسیه،
دانشگاه فنی ملی اوکراین "موسسه پلی تکنیک کیف" بخش ابزارها و سیستم های جهت یابی و دستورالعمل های ناوبری برای کار آزمایشگاهیرشته "ناوبری
UDC 629.78.018:621.397.13 روش فاصله های جفت در مسئله تنظیم پرواز سنسورهای ASTRO سیستم جهت گیری وسایل نقلیه فضایی B.M. Sukhovilov به عنوان دقت و قابلیت اطمینان نجومی
UDC 629.05 حل مشکل ناوبری با استفاده از یک سیستم ناوبری اینرسیال پایین و یک سیستم سیگنال هوایی Mkrtchyan V.I.، دانشجو، بخش "ابزار و سیستم های جهت گیری، تثبیت و ناوبری"
مدل سیستم بصری یک اپراتور انسانی در تشخیص تصویر شی Yu.S. گلینا، وی.یا. کولیوچکین لومونوسوف دانشگاه فنی دولتی مسکو N.E. باومن، ریاضی
راکت و فضایی ابزار و سیستم های اطلاعاتی 2015، جلد 2، شماره 3، ص. 79 83 UDC 681.3.06 تجزیه و تحلیل سیستم، کنترل فضاپیما، پردازش اطلاعات و سیستم های تله متری
سیستم های دینامیکی خطی فیلتر کالمن Likbez: برخی از خواص توزیع نرمال چگالی توزیع.4.3.. -4 x b.5 x b =.7 5 p(x a x b =.7) - x p(x a,x b) p(x a) 4 3 - - -3 x .5
UDC 621.396.671 O. S. Litvinov, A. A. Gilyazov ارزیابی تأثیر گروههای تداخل بر دریافت سیگنال مفید توسط یک همفاصله خطی تطبیقدهنده ایالات متحده
UDC 681.5.15.44 FORECASTING OF PIECE-Stationary Processes E.Yu. آلکسیف فرآیندهای تصادفی گسسته حاوی پارامترهایی که به طور ناگهانی در زمانهای تصادفی تغییر میکنند در نظر گرفته میشوند. برای
UDC 63966 فیلتر خطی بهینه برای نویز غیر سفید GF Savinov در این مقاله، یک الگوریتم فیلتر بهینه برای مواردی که اقدامات ورودی و نویزها تصادفی گاوسی هستند به دست میآید.
تعیین حرکات نوسانی عناصر ماهواره ای غیر صلب با استفاده از پردازش تصویر ویدئویی D.O. ناظر موسسه فیزیک و فناوری لازارف مسکو، کاندیدای علوم فیزیک و ریاضی: D.S. ایوانف، موسسه
UDC 004 در مورد روشهای ردیابی و ردیابی یک شی در یک جریان ویدیویی همانطور که در یک سیستم تجزیه و تحلیل ویدیویی برای جمعآوری و تجزیه و تحلیل دادههای بازاریابی اعمال میشود Chezganov D.A., Serikov. ایالت روسیه جنوبی
مجله الکترونیکی"مجموعه مقالات MAI". شماره 66 www.ma.u/scence/tud/ UDC 69.78 الگوریتم ناوبری اصلاح شده برای تعیین موقعیت ماهواره با استفاده از سیگنال های GS/GLONASS Kurshin A.V.
UDC 621.396.96 بررسی الگوریتم پیوند و تأیید مسیرها با توجه به معیار M out of N Chernova TS، دانشجوی گروه "سیستم ها و دستگاه های رادیو الکترونیکی"، روسیه، 105005، مسکو N.E.
تئوری و عملی دستگاه ها و سیستم های ناوبری
سخنرانی 6 ویژگی های پورتفولیو در سخنرانی های قبلی بارها از عبارت "پورتفولیو" استفاده می شد.
شناسایی سریهای زمانی شکاف بر اساس مدلهای فضای ایالتی R. I. Merkulov V. I. Lobach Belarusian State University Minsk Belarus پست الکترونیک: [ایمیل محافظت شده] [ایمیل محافظت شده]
دستگاه ها و سیستم های کنترل خودکار
مجموعه مقالات MAI. شماره 89 UDC 629.051 www.mai.ru/science/trudy/ کالیبراسیون یک سیستم ناوبری اینرسی strapdown هنگام چرخش محور عمودیماتاسف A.I.*، Tikhomirov V.V.** Moskovsky
هندسه تحلیلی ماژول 1 جبر ماتریسی جبر برداری متن 4 ( مطالعه مستقل) چکیده وابستگی خطی بردارها معیارهای وابستگی خطی بردارهای دو، سه و چهار
UDC 62.396.26 L.A. Podkolzina, K. Drugov الگوریتم های پردازش اطلاعات در سیستم های ناوبری اجسام متحرک زمین برای کانال تعیین مختصات موقعیت برای تعیین مختصات و پارامترها
تجزیه و تحلیل آماری سریهای زمانی پارامتری شکاف بر اساس مدلهای فضای حالت SV Lobach Belarusian State University Minsk, Belarus پست الکترونیکی: [ایمیل محافظت شده]
روش های ریاضی پردازش داده ها UDC 6.39 S. Ya. Zhuk.. Kozheshkurt.. Yuzefovich National Technical University of Ukraine "KP" ave. Pobedy 37 356 کیف اوکراین موسسه مشکلات ثبت اطلاعات NAS
ساخت استاتیک MM اشیاء تکنولوژیک هنگام مطالعه استاتیک اشیاء تکنولوژیک، اشیایی با انواع بلوک دیاگرام های زیر بیشتر مواجه می شوند (شکل: O با یک ورودی x و یک
برآورد پارامترهای نگرش فضاپیما با استفاده از فیلتر کالمن Student, Department of Automatic Control Systems: D.I. مشاور علمی گالکین: A.A. کارپونین، دکتری، دانشیار
5. Meleshko V.V. سیستم های ناوبری اینرسی Strapdown: کتاب درسی. کمک هزینه / V.V. ملشکو، O.I. نسترنکو. Kirovograd: POLYMED-Service, 211. 172 p. آخرین مهلت برای تحریریه 17 آوریل 212 Kostyuk
UDC 004.896 کاربرد تبدیلهای هندسی برای آنالیز کردن تصویر Kanev AI، متخصص روسیه، 105005، مسکو، MSTU im. N.E. باومن، گروه پردازش اطلاعات و سیستم های کنترل
4. روشهای مونت کارلو 1 4. روشهای مونت کارلو برای شبیه سازی اثرات مختلف فیزیکی، اقتصادی و غیره، روشهایی به نام روشهای مونت کارلو به طور گسترده استفاده می شود. نام خود را مدیون هستند
فیلترینگ باند 1 فیلترینگ باند گذر در قسمت های قبل فیلتر کردن تغییرات سیگنال سریع (صاف کردن) و تغییرات سیگنال آهسته (دترندینگ) در نظر گرفته شد. گاهی لازم است برجسته سازی کنید
[یادداشت ها] با توضیح مبانی فیلتر کالمن با استفاده از مشتق ساده و شهودی رمزی فراهر، این مقاله یک مشتق ساده و شهودی از فیلتر کالمن را به منظور آموزش آن ارائه می کند.
UDC 004.932 الگوریتم طبقهبندی اثر انگشت D.S. Lomov، دانشجو روسیه، 105005، مسکو، MSTU im. N.E. باومن، بخش "نرم افزار کامپیوتر و فناوری اطلاعات" ناظر:
سخنرانی ویژگی های عددی یک سیستم از دو متغیر تصادفی - بردار تصادفی بعدی هدف سخنرانی: تعیین ویژگی های عددی یک سیستم از دو متغیر تصادفی: گشتاورهای اولیه و مرکزی، کوواریانس
پویایی نرخ زاد و ولد در جمهوری چوواش
IN 1990-5548 الکترونیک و سیستم های کنترل. 2011. 4(30) 73 UDC656.7.052.002.5:681.32(045) V. M. Sineglazov، دکترای مهندسی. Sci., Prof., Sh. I. Askerov پردازش داده های پیچیده در ناوبری بهینه
UDC 004.896 ویژگی های اجرای الگوریتم برای نمایش نتایج آنامورفیزاسیون Kanev AI، متخصص روسیه، 105005، مسکو، MSTU im. N.E. باومن، بخش "سیستم های پردازش اطلاعات و
177 UDC 658.310.8: 519.876.2 استفاده از دقت برآورد هنگام رزرو سنسورهای L.I. Luzina این مقاله یک رویکرد ممکن را برای به دست آوردن یک طرح اضافی حسگر جدید در نظر می گیرد. سنتی
مجموعه آثار علمی NSTU. 28.4 (54). 37 44 UDC 59.24 ON COMPLEX OF PROGRAMS FOR SOLVE THE PROBLEM OF IDENTIFICATION OF LINEAR DYNAMIC Discrete Stationary Objects G.V. تروشینا مجموعه ای از برنامه ها در نظر گرفته شد
UDC 625.1:519.222:528.4 S.I. Dolganyuk S.I. Dolganyuk، 2010 افزایش دقت راه حل ناوبری در موقعیت یابی لوکوموتیوهای SHUNTER از طریق استفاده از مدل های توسعه مسیر دیجیتال
UDC 531.1 سازگاری فیلتر KALMAN برای استفاده با سیستم های ناوبری محلی و جهانی A.N. Zabegaev ( [ایمیل محافظت شده]) V.E. Pavlovsky ( [ایمیل محافظت شده]) موسسه ریاضیات کاربردی.
اتوماسیون و کنترل UDC 68.58.3 AG Shpektorov، VT Fam V. I. Ulyanova (Lenina) تجزیه و تحلیل کاربرد میکرومکانیکی
مبانی تحلیل رگرسیون مفهوم همبستگی و تحلیل رگرسیونی برای حل مشکلات تحلیل و پیش بینی اقتصادی، اغلب از آمار، گزارش یا قابل مشاهده استفاده می شود.
سخنرانی 4. حل سیستم های معادلات خطی با تکرارهای ساده. اگر سیستم دارای ابعاد بزرگ (6 معادله) باشد یا ماتریس سیستم پراکنده باشد، روش های تکراری غیرمستقیم برای حل موثرتر هستند.
58 کنفرانس علمیمؤسسه فیزیک و فناوری مسکو بخش دینامیک فضاپیما و سیستم کنترل حرکت برای تعیین حرکت مدل های سیستم کنترل روی میز آیرودینامیک با استفاده از دوربین فیلمبرداری
سخنرانی 3 5. روش های تقریب توابع فرمول بندی مسئله توابع جدول شبکه ای [ab] y 5 تعریف شده در گره های شبکه Ω در نظر گرفته می شوند. هر مش با مراحل h غیر یکنواخت یا h مشخص می شود
1. روش های عددی برای حل معادلات 1. سیستم های معادلات خطی. 1.1. روش های مستقیم 1.2. روش های تکراری 2. معادلات غیر خطی. 2.1. معادلات با یک مجهول. 2.2. سیستم های معادلات یکی
UDC 621.396 بررسی الگوریتمهای پردازش ثانویه اطلاعات سیستم رادار چندگانه برای کانال زاویه ارتفاع Borisov AN, Glinchenko VA, Nazarov AA, Islamov RV, Suchkov PV. علمی
موضوع روش های عددی جبر خطی - موضوع روش های عددی جبر خطی طبقه بندی چهار بخش اصلی جبر خطی وجود دارد: حل سیستم های معادلات جبری خطی (SLAE)
UDC 004.352.242 بازسازی تصاویر لکه دار با حل یک معادله انتگرالی از نوع پیچیدگی Ivannikova IA, student Russia, 105005, Moscow, MSTU im. N.E. باومن، بخش "سیستم های خودکار
بررسی هواشناسی در حالت عملکرد GPS استاندارد Mogilevsky V.Ye. JSC "GNPP "Aerogeofizika"
تجزیه و تحلیل سیگنال های صوتی بر اساس روش فیلتر کالمن گوروف، پی.جی. ژیگانوف، A.M. Ozersky ویژگی های پردازش دینامیکی سیگنال های تصادفی با استفاده از گسسته
UDK AA Minko شناسایی یک شی خطی با پاسخ به یک سیگنال هارمونیک
سخنرانی. تخمین دامنه پیچیده سیگنال. تخمین زمان تاخیر سیگنال تخمین فرکانس سیگنال با فاز تصادفی تخمین مشترک زمان تاخیر و فرکانس یک سیگنال با فاز تصادفی.
فن آوری های محاسباتی جلد 18، 1، 2013 شناسایی پارامترهای فرآیند انتشار غیرعادی بر اساس معادلات تفاوت AS Ovsienko Samara State Technical University, روسیه ایمیل:
1 پیش بینی شرایط بازار شرکت های پتروشیمی Kordunov D.Yu., Bityutsky S.Ya. مقدمه. در شرایط اقتصادی مدرن، که با توسعه سریع یکپارچگی جهانی مشخص می شود
وظیفه محلی سازی و نقشه برداری همزمان (SLAM) Robot School-2014 Andrey Antonov robotosha.ru 10 اکتبر 2014 Plan 1 SLAM Basics 2 RGB-D SLAM 3 Robot Andrey Antonov (robotosha.ru) SLAM task
UDC 004.021 T. N. Romanova، A. V. Sidorin، V. N. Solyakov، و K. V. Kozl o v SINTEZ OF A MONOCHROME Image FROM a Multi-range Palette Construction با استفاده از راه حل معادله سم
دانشگاه فنی ملی اوکراین "موسسه پلی تکنیک کیف" گروه ابزار و سیستم های جهت یابی و ناوبری دستورالعمل های کار آزمایشگاهی در رشته "ناوبری"
پردازش سیگنال دیجیتال /9 UDC 69.78 روش تحلیلی محاسبه خطاهای تعیین جهت زاویه ای از سیگنال های سیستم های ناوبری رادیویی ماهواره ای Aleshechkin А.М. حالت تعریف مقدمه
ویژگی های تشکیل یک مدل رایانه ای از یک سیستم نوری-الکترونیک دینامیک Pozdnyakova N.S., Torshina I.P. دانشکده اطلاعات نوری دانشگاه دولتی ژئودزی و کارتوگرافی مسکو
مجموعه مقالات ISA RAS 009. T. 46 III. مسائل کاربردی محاسبات توزیع شده حالت های ساکن در مدل غیرخطی انتقال بار در DNA * حالت های ساکن در مدل غیرخطی انتقال بار در DNA
این فیلتر در زمینه های مختلف - از مهندسی رادیو گرفته تا اقتصاد - استفاده می شود. در اینجا ما ایده اصلی، معنی، ماهیت این فیلتر را مورد بحث قرار خواهیم داد. به ساده ترین زبان ممکن ارائه خواهد شد.
بیایید فرض کنیم که ما نیاز به اندازه گیری مقداری از یک شی داریم. در مهندسی رادیو، اغلب آنها با اندازه گیری ولتاژ در خروجی یک دستگاه خاص (سنسور، آنتن و غیره) سروکار دارند. در مثال با یک الکتروکاردیوگراف (نگاه کنید به)، ما با اندازه گیری پتانسیل های زیستی در بدن انسان سروکار داریم. به عنوان مثال، در اقتصاد، ارزش اندازه گیری شده می تواند نرخ ارز باشد. هر روز نرخ ارز متفاوت است، یعنی. هر روز "اندازه گیری های او" ارزش متفاوتی به ما می دهد. و برای تعمیم، می توان گفت که بیشتر فعالیت های انسان (اگر نه همه) به اندازه گیری های ثابت - مقایسه کمیت های خاص (به کتاب مراجعه کنید) منتهی می شود.
بنابراین بیایید بگوییم که همیشه چیزی را اندازه می گیریم. بیایید همچنین فرض کنیم که اندازه گیری های ما همیشه با مقداری خطا همراه است - این قابل درک است، زیرا هیچ ابزار اندازه گیری ایده آلی وجود ندارد و همه با یک خطا نتیجه می دهند. در سادهترین حالت، موارد توصیفشده را میتوان به عبارت زیر کاهش داد: z=x+y، که در آن x مقدار واقعی است که میخواهیم اندازهگیری کنیم و اگر یک دستگاه اندازهگیری ایدهآل داشته باشیم، اندازهگیری میشود، y خطای اندازهگیری است. معرفی شده توسط دستگاه اندازه گیریو z مقداری است که اندازه گیری کردیم. بنابراین وظیفه فیلتر کالمن این است که هنوز حدس بزند (تعیین کند) از z که اندازه گیری کردیم، زمانی که z خود را به دست آوردیم، مقدار واقعی x چقدر بود (که در آن مقدار واقعی و خطای اندازه گیری "sit" بود). لازم است مقدار واقعی x را از z فیلتر کنید (خارج کنید) - نویز تحریف کننده y را از z حذف کنید. یعنی فقط با داشتن مبلغ در دست، باید حدس بزنیم که کدام شرایط این مقدار را داده است.
با توجه به موارد فوق، اکنون همه چیز را به صورت زیر فرموله می کنیم. بگذارید فقط دو عدد تصادفی وجود داشته باشد. فقط مجموع آنها به ما داده می شود و ما باید از این مبلغ مشخص کنیم که شرایط چیست. مثلاً عدد 12 را به ما دادند و می گویند: 12 مجموع اعداد x و y است، سؤال این است که x و y با چه چیزی برابر است. برای پاسخ به این سوال، معادله x+y=12 را میسازیم. ما یک معادله با دو مجهول به دست آوردیم، بنابراین، به طور دقیق، نمی توان دو عدد را پیدا کرد که این مجموع را بدهد. اما هنوز هم می توانیم در مورد این اعداد چیزی بگوییم. می توان گفت که یا اعداد 1 و 11 یا 2 و 10 یا 3 و 9 یا 4 و 8 و غیره بوده است، همچنین یا 13 و 1- است یا 14 و 2- یا 15 و - 3 و غیره یعنی با مجموع (در مثال ما 12) می توانیم مجموعه ای از گزینه های ممکن را تعیین کنیم که در مجموع دقیقاً 12 می دهد. یکی از این گزینه ها جفت مورد نظر ما است که در واقع همین الان 12 داده است. همچنین ارزش دارد. با توجه به اینکه همه انواع جفت اعدادی که در مجموع 12 به دست میآیند یک خط مستقیم را تشکیل میدهند که در شکل 1 نشان داده شده است، که با معادله x+y=12 (y=-x+12) به دست میآید.
عکس. 1
بنابراین، جفت مورد نظر ما در جایی در این خط مستقیم قرار دارد. تکرار می کنم، غیرممکن است که از بین همه این گزینه ها جفتی را انتخاب کنید که در واقع وجود داشته است - که عدد 12 را می دهد، بدون داشتن هیچ سرنخ اضافی. با این حال، در شرایطی که فیلتر کالمن برای آن اختراع شد، چنین نکاتی وجود دارد. چیزی از قبل در مورد اعداد تصادفی شناخته شده است. به طور خاص، به اصطلاح هیستوگرام توزیع برای هر جفت اعداد در آنجا شناخته شده است. معمولاً پس از مشاهدات طولانی مدت حاصل از این اعداد بسیار تصادفی به دست می آید. به عنوان مثال، از روی تجربه مشخص است که در 5٪ موارد جفت x=1، y=8 معمولاً از بین می رود (این جفت را به صورت زیر نشان می دهیم: (1،8))، در 2٪ موارد جفت x=2، y=3 (2.3)، در 1% موارد یک زوج (3.1)، در 0.024% موارد یک زوج (11.1) و غیره. دوباره، این هیستوگرام تنظیم شده است برای همه زوج هااعداد، از جمله اعدادی که جمع آنها 12 می شود. بنابراین، برای هر جفتی که جمع آنها 12 می شود، می توان گفت که برای مثال، جفت (1، 11) در 0.8٪ موارد، جفت (2، 10) - در 1٪ موارد، جفت (3، 9) - در 1.5٪ موارد و غیره. بنابراین، میتوانیم از روی هیستوگرام مشخص کنیم که در چند درصد موارد مجموع عبارتهای جفت برابر با 12 است. مثلاً در 30٪ موارد حاصل جمع 12 است. و در 70٪ باقیمانده، جفتهای باقی مانده سقوط میکنند. خارج - اینها (1.8)، (2، 3)، (3،1)، و غیره هستند. - آنهایی که با اعدادی غیر از 12 جمع می شوند. علاوه بر این، اجازه دهید، برای مثال، یک جفت (7.5) در 27٪ موارد سقوط کنند، در حالی که همه جفت های دیگر که مجموعاً 12 می دهند در 0.024٪ + 0.8٪ + سقوط کنند. 1%+1.5%+…=3% موارد. بنابراین، با توجه به هیستوگرام، متوجه شدیم که اعدادی که در مجموع 12 می دهند، در 30٪ موارد سقوط می کنند. در عین حال، ما می دانیم که اگر 12 سقوط کرد، اغلب (27٪ از 30٪) دلیل این یک جفت (7.5) است. یعنی اگر قبلا، پیش از این 12 رول شده، می توان گفت که در 90٪ (27٪ از 30٪ - یا همان طور است، 27 بار از هر 30) دلیل رول 12 یک جفت است (7.5). با دانستن اینکه جفت (7.5) اغلب دلیل بدست آوردن مجموع برابر با 12 است، منطقی است که فرض کنیم، به احتمال زیاد، اکنون از بین رفته است. البته هنوز این یک واقعیت نیست که عدد 12 در واقع توسط این جفت خاص تشکیل شده است، اما دفعه بعد، اگر با 12 مواجه شدیم و دوباره یک جفت (7.5) را فرض کنیم، در 90٪ موارد ما هستیم. 100% درسته اما اگر یک جفت (2، 10) را فرض کنیم، فقط 1% از 30% مواقع درست خواهیم بود که برابر با 3.33% حدس های صحیح است در حالی که 90% هنگام حدس زدن یک جفت (7،5) است. این همه چیز است - این نکته الگوریتم فیلتر کالمن است. یعنی فیلتر کالمن تضمین نمی کند که در تعیین جمع اشتباه نمی کند، اما تضمین می کند که حداقل تعداد دفعات اشتباه را انجام دهد (احتمال خطا حداقل خواهد بود) زیرا از آمار استفاده می کند. - هیستوگرام سقوط از جفت اعداد. همچنین باید تاکید کرد که به اصطلاح چگالی توزیع احتمال (PDD) اغلب در الگوریتم فیلتر کالمن استفاده می شود. با این حال، باید درک کرد که معنای آن همان هیستوگرام است. علاوه بر این، هیستوگرام تابعی است که بر اساس PDF و تقریب آن ساخته شده است (به عنوان مثال، را ببینید).
در اصل، ما می توانیم این هیستوگرام را به عنوان تابعی از دو متغیر به تصویر بکشیم - یعنی به عنوان نوعی سطح بالای صفحه xy. در جایی که سطح بالاتر است، احتمال سقوط جفت مربوطه نیز بیشتر است. شکل 2 چنین سطحی را نشان می دهد.

شکل 2
همانطور که می بینید، بالای خط x + y = 12 (که انواع جفت هایی هستند که مجموعاً 12 می دهند)، نقاط سطحی در ارتفاعات مختلف وجود دارد و بالاترین ارتفاع در نوع با مختصات (7،5) است. و وقتی به جمعی برابر با 12 برخورد می کنیم، در 90% موارد جفت (7،5) دلیل پیدایش این جمع است. آن ها این جفت است که به 12 می رسد، بیشترین احتمال وقوع را دارد، مشروط بر اینکه مجموع آن 12 باشد.
بنابراین، ایده پشت فیلتر کالمن در اینجا توضیح داده شده است. روی آن است که انواع اصلاحات آن ساخته شده است - تکراری تک مرحله ای، چند مرحله ای و غیره. برای مطالعه عمیق تر فیلتر کالمن، من کتاب: Van Tries G. Theory of detection, estimation and modulation را توصیه می کنم.
p.s.برای کسانی که علاقه مند به توضیح مفاهیم ریاضی هستند، چیزی که "روی انگشتان" نامیده می شود، می توانیم این کتاب و به ویژه فصل های بخش ریاضیات آن را توصیه کنیم (می توانید خود کتاب یا فصل های جداگانه را از آی تی).
فیلترهای وینر برای فرآیندهای پردازش یا بخش هایی از فرآیندها به عنوان یک کل (پردازش بلوک) مناسب هستند. پردازش متوالی نیاز به تخمین فعلی سیگنال در هر چرخه، با در نظر گرفتن اطلاعات دریافتی در ورودی فیلتر در طول فرآیند مشاهده دارد.
با فیلتر وینر، هر نمونه سیگنال جدید نیاز به محاسبه مجدد وزن فیلتر دارد. در حال حاضر، فیلترهای تطبیقی به طور گسترده استفاده می شود، که در آن ورودی اطلاعات جدیدبرای تصحیح مداوم یک تخمین سیگنال قبلاً ساخته شده (ردیابی هدف در رادار، سیستم های کنترل خودکار در کنترل و غیره) استفاده می شود. فیلترهای تطبیقی از نوع بازگشتی که به عنوان فیلتر کالمن شناخته می شوند، مورد توجه خاص هستند.
این فیلترها به طور گسترده در حلقه های کنترلی در سیستم های تنظیم و کنترل خودکار استفاده می شوند. همانطور که اصطلاحات خاصی که در توصیف کارشان بهعنوان فضای دولت به کار میرود، نشان میدهد که آنها از آنجا آمدهاند.
یکی از اصلی ترین وظایفی که باید در تمرین محاسبات عصبی حل شود، به دست آوردن الگوریتم های یادگیری سریع و قابل اعتماد شبکه عصبی است. در این راستا، ممکن است استفاده از الگوریتم یادگیری فیلترهای خطی در حلقه بازخورد مفید باشد. از آنجایی که الگوریتمهای یادگیری ماهیت تکراری دارند، چنین فیلتری باید یک تخمینگر بازگشتی متوالی باشد.
مشکل تخمین پارامتر
یکی از مسائل تئوری راه حل های آماری که از اهمیت عملی بالایی برخوردار است، مسئله تخمین بردارهای حالت و پارامترهای سیستم ها است که به صورت زیر فرموله شده است. فرض کنید لازم است مقدار پارامتر برداری $X$ را تخمین بزنیم، که برای اندازه گیری مستقیم غیرقابل دسترسی است. در عوض، پارامتر دیگری $Z$ بسته به $X$ اندازه گیری می شود. وظیفه تخمین پاسخ دادن به این سوال است: در مورد X$ با توجه به $Z$ چه می توان گفت. در حالت کلی، روش تخمین بهینه بردار X$ بستگی به معیار کیفیت پذیرفته شده برای تخمین دارد.
برای مثال، رویکرد بیزی به مسئله تخمین پارامتر به اطلاعات پیشینی کاملی در مورد خواص احتمالی پارامتر برآورد شده نیاز دارد که اغلب غیرممکن است. در این موارد، فرد به روش حداقل مربعات (LSM) متوسل می شود که به اطلاعات پیشینی بسیار کمتری نیاز دارد.
اجازه دهید کاربرد حداقل مربعات را برای حالتی در نظر بگیریم که بردار مشاهداتی $Z$ با یک مدل خطی با بردار تخمین پارامتر $X$ متصل شده باشد و یک نویز $V$ در مشاهده وجود داشته باشد که با آن همبستگی ندارد. پارامتر تخمینی:
$Z = HX + V$، (1)
که در آن $H$ ماتریس تبدیل است که رابطه بین مقادیر مشاهده شده و پارامترهای برآورد شده را توصیف می کند.
تخمین X$ برای به حداقل رساندن خطای مربع به صورت زیر نوشته شده است:
$X_(ots)=(H^TR_V^(-1)H)^(-1)H^TR_V^(-1)Z$, (2)
اجازه دهید نویز $V$ همبسته نباشد، در این صورت ماتریس $R_V$ فقط ماتریس هویت است و معادله تخمین سادهتر میشود:
$X_(ots)=(H^TH)^(-1)H^TZ$, (3)
ضبط به صورت ماتریس تا حد زیادی باعث صرفه جویی در کاغذ می شود، اما ممکن است برای کسی غیرعادی باشد. مثال زیر که از مونوگراف Yu. M. Korshunov "مبانی ریاضی سایبرنتیک" گرفته شده است، همه اینها را نشان می دهد.
مدار الکتریکی زیر وجود دارد:
مقادیر مشاهده شده در این مورد، قرائت ابزار $A_1 = 1 A، A_2 = 2 A، V = 20 B$ است.
علاوه بر این، مقاومت $R = 5$ اهم مشخص است. لازم است که از نقطه نظر معیار حداقل میانگین مربعات خطا، مقادیر جریان های $I_1$ و $I_2$ را به بهترین شکل برآورد کنید. مهمترین چیز در اینجا این است که بین مقادیر مشاهده شده (خوانش ابزار) و پارامترهای برآورد شده رابطه وجود دارد. و این اطلاعات از خارج وارد می شود.
در این مورد، اینها قوانین Kirchhoff هستند، در مورد فیلتر (که بعداً مورد بحث قرار خواهد گرفت) - یک مدل سری زمانی خودبازگشت، که فرض می کند مقدار فعلی به موارد قبلی بستگی دارد.
بنابراین، دانش قوانین Kirchhoff، که به هیچ وجه با تئوری تصمیمات آماری مرتبط نیست، به شما امکان می دهد بین مقادیر مشاهده شده و پارامترهای تخمین زده شده ارتباط برقرار کنید (کسانی که مهندسی برق خوانده اند می توانند بررسی کنند، بقیه باید حرفشان را قبول کن):
$$z_1 = A_1 = I_1 + \xi_1 = 1$$
$$z_2 = A_2 = I_1 + I_2 + \xi_2 = 2$$
$$z_2 = V/R = I_1 + 2 * I_2 + \xi_3 = 4$$
این به صورت برداری است:
$$\begin(vmatrix) z_1\\ z_2\\ z_3 \end(vmatrix) = \begin(vmatrix) 1 & 0\\ 1 & 1\\ 1 & 2 \end(vmatrix) \begin(vmatrix) I_1\ \ I_2 \end(vmatrix) + \begin(vmatrix) \xi_1\\ \xi_2\\ \xi_3 \end(vmatrix)$$
یا $Z = HX + V$، که در آن
$$Z= \begin(vmatrix) z_1\\ z_2\\ z_3 \end(vmatrix) = \begin(vmatrix) 1\\ 2\\ 4 \end(vmatrix) ; H= \begin(vmatrix) 1 & 0\\ 1 & 1\\ 1 & 2 \end(vmatrix) ; X= \begin(vmatrix) I_1\\ I_2 \end(vmatrix) ; V= \begin(vmatrix) \xi_1\\ \xi_2\\ \xi_3 \end(vmatrix)$$
با در نظر گرفتن مقادیر نویز به صورت نامرتبط با یکدیگر، برآورد I 1 و I 2 را با روش حداقل مربعات مطابق با فرمول 3 پیدا می کنیم:
$H^TH= \begin(vmatrix) 1 & 1& 1\\ 0 & 1&2 \end(vmatrix) \begin(vmatrix) 1 & 0\\ 1 & 1\\ 1 & 2 \end(vmatrix) = \ Begin(vmatrix) 3 & 3\\ 3 & 5 \end(vmatrix) ; (H^TH)^(-1)= \frac(1)(6) \begin(vmatrix) 5 & -3\\ -3 & 3 \end(vmatrix) $;
$H^TZ= \begin(vmatrix) 1 & 1& 1\\ 0 & 1&2 \end(vmatrix) \begin(vmatrix) 1 \\ 2\\ 4 \end(vmatrix) = \begin(vmatrix) 7\ \ 10 \end(vmatrix) ; X(vmatrix)= \frac(1)(6) \begin(vmatrix) 5 & -3\\ -3 & 3 \end(vmatrix) \begin(vmatrix) 7\\ 10 \end(vmatrix) = \frac (1)(6) \begin(vmatrix) 5\\ 9 \end(vmatrix)$;
بنابراین $I_1 = 5/6 = 0.833 A$; $I_2 = 9/6 = 1.5 دلار استرالیا.
کار فیلتر کردن
برخلاف مشکل تخمین پارامترهایی که مقادیر ثابتی دارند، در مسئله فیلتراسیون باید فرآیندها را ارزیابی کرد، یعنی تخمینهای جاری سیگنال متغیر با زمان را که توسط نویز تحریف شده و بنابراین برای اندازهگیری مستقیم غیرقابل دسترسی است، پیدا کرد. در حالت کلی، نوع الگوریتم های فیلترینگ به ویژگی های آماری سیگنال و نویز بستگی دارد.
فرض می کنیم که سیگنال مفید تابعی از زمان است که به آرامی تغییر می کند و نویز نویز نامرتبط است. ما از روش حداقل مربعات استفاده خواهیم کرد، دوباره به دلیل عدم وجود اطلاعات پیشینی در مورد ویژگی های احتمالی سیگنال و نویز.
ابتدا، تخمینی از ارزش فعلی $x_n$ را با استفاده از آخرین مقادیر $k$ سری زمانی $z_n, z_(n-1),z_(n-2)\dots z_(n-( بدست می آوریم. k-1)) دلار. مدل مشاهده مانند مسئله تخمین پارامتر است:
واضح است که $Z$ یک بردار ستونی است متشکل از مقادیر مشاهده شده سری زمانی $z_n، z_(n-1)، z_(n-2)\dots z_(n-(k-1)) $, $V $ – بردار ستون نویز $\xi _n, \xi _(n-1),\xi_(n-2)\dots \xi_(n-(k-1))$ که سیگنال واقعی را تحریف می کند. و نمادهای $H$ و $X$ به چه معنا هستند؟ به عنوان مثال، اگر تنها چیزی که لازم است تخمینی از مقدار فعلی سری زمانی باشد، می توانیم درباره چه نوع بردار ستونی X$ صحبت کنیم؟ و منظور از ماتریس تبدیل $H$ اصلا مشخص نیست.
تنها در صورتی می توان به تمام این سوالات پاسخ داد که مفهوم مدل تولید سیگنال در نظر گرفته شود. یعنی مدلی از سیگنال اصلی مورد نیاز است. این قابل درک است، در غیاب اطلاعات پیشینی در مورد ویژگی های احتمالی سیگنال و نویز، تنها به ایجاد فرضیات باقی می ماند. شما می توانید آن را فال روی تفاله قهوه بنامید، اما کارشناسان اصطلاحات متفاوتی را ترجیح می دهند. در سشوار آنها به این مدل پارامتریک می گویند.
در این مورد، پارامترهای این مدل خاص برآورد می شود. هنگام انتخاب یک مدل تولید سیگنال مناسب، به یاد داشته باشید که هر تابع تحلیلی را می توان در یک سری تیلور گسترش داد. ویژگی قابل توجه سری تیلور این است که شکل یک تابع در هر فاصله محدود $t$ از نقطه ای $x=a$ به طور منحصر به فردی توسط رفتار تابع در یک همسایگی بی نهایت کوچک از نقطه $x=a تعیین می شود. $ (در مورد مشتقات مرتبه اول و بالاتر آن صحبت می کنیم).
بنابراین وجود سری تیلور به این معنی است که تابع تحلیلی دارای ساختار درونی با اتصال بسیار قوی است. به عنوان مثال، اگر خودمان را به سه عضو سری تیلور محدود کنیم، مدل تولید سیگنال به این صورت خواهد بود:
$x_(n-i) = F_(-i)x_n$، (4)
$$X_n= \begin(vmatrix) x_n\\ x"_n\\ x""_n \end(vmatrix) ؛ F_(-i)= \begin(vmatrix) 1 & -i & i^2/2\\ 0 & 1 & -i\\ 0 & 0 & 1 \end(vmatrix) $$
یعنی فرمول 4 با ترتیب معین چند جمله ای (در مثال برابر با 2 است) بین مقدار n$-th سیگنال در توالی زمانی و $(n-i)$-th ارتباط برقرار می کند. . بنابراین، بردار حالت تخمین زده شده در این مورد، علاوه بر خود مقدار تخمینی، مشتقات اول و دوم سیگنال را نیز شامل می شود.
در تئوری کنترل خودکار، چنین فیلتری را فیلتر استاتیک مرتبه دوم می نامند. ماتریس تبدیل $H$ برای این مورد (تخمین بر اساس نمونه های فعلی و $k-1$ قبلی است) به این صورت است:
$$H= \begin(vmatrix) 1 & -k & k^2/2\\ - & - & -\\ 1 & -2 & 2\\ 1 & -1 & 0.5\\ 1 & 0 & 0 \ end(vmatrix)$$
همه این اعداد از سری تیلور به دست می آیند، با فرض اینکه فاصله زمانی بین مقادیر مشاهده شده مجاور ثابت و برابر با 1 باشد.
بنابراین، مشکل فیلتر، تحت فرضیات ما، به مشکل تخمین پارامترها کاهش یافته است. در این مورد، پارامترهای مدل تولید سیگنال اتخاذ شده توسط ما برآورد می شود. و ارزیابی مقادیر بردار حالت $X$ طبق همان فرمول 3 انجام می شود:
$$X_(ots)=(H^TH)^(-1)H^TZ$$
در واقع، ما یک فرآیند تخمین پارامتریک را بر اساس یک مدل اتورگرسیو فرآیند تولید سیگنال پیادهسازی کردهایم.
فرمول 3 به راحتی در نرم افزار پیاده سازی می شود، برای این کار باید ماتریس $H$ و ستون برداری مشاهدات $Z$ را پر کنید. چنین فیلترهایی نامیده می شوند فیلترهای حافظه محدود، زیرا آنها از آخرین مشاهدات $k$ برای بدست آوردن تخمین فعلی $X_(not)$ استفاده می کنند. در هر مرحله مشاهده جدید، مجموعه جدیدی از مشاهدات به مجموعه مشاهدات فعلی اضافه می شود و قدیمی ها کنار گذاشته می شوند. این فرآیند ارزیابی نامیده می شود پنجره کشویی.
در حال رشد فیلترهای حافظه
فیلترهای دارای حافظه محدود این عیب اصلی را دارند که پس از هر مشاهده جدید، لازم است مجدداً محاسبه مجدد کامل تمام داده های ذخیره شده در حافظه محاسبه شود. علاوه بر این، محاسبه تخمین ها را می توان تنها پس از جمع آوری نتایج اولین مشاهدات k$ شروع کرد. یعنی این فیلترها دارای مدت طولانی فرآیند گذرا هستند.
برای مقابله با این نقص، باید از فیلتری با حافظه دائمی به فیلتری با حافظه رفت حافظه در حال رشد. در چنین فیلتری، تعداد مقادیر مشاهده شده برای ارزیابی باید با عدد n مشاهده فعلی مطابقت داشته باشد. این امکان به دست آوردن تخمین هایی را می دهد که از تعداد مشاهدات برابر با تعداد اجزای بردار تخمینی X$ شروع می شود. و این با ترتیب مدل اتخاذ شده مشخص می شود، یعنی چند عبارت از سری تیلور در مدل استفاده شده است.
در عین حال، با افزایش n، خواص صاف کننده فیلتر بهبود می یابد، یعنی دقت تخمین ها افزایش می یابد. با این حال، اجرای مستقیم این رویکرد با افزایش هزینه های محاسباتی همراه است. بنابراین، فیلترهای حافظه در حال رشد به عنوان پیاده سازی می شوند عود کننده.
نکته این است که در زمان n ما قبلاً تخمین $X_((n-1)ots)$ را داریم که حاوی اطلاعاتی در مورد تمام مشاهدات قبلی $z_n, z_(n-1), z_(n-2) \dots z_ است. (n-(k-1))$. تخمین $X_(not)$ با مشاهده بعدی $z_n$ با استفاده از اطلاعات ذخیره شده در تخمین $X_((n-1))(\mbox (ot))$ بدست می آید. این روش فیلترینگ مکرر نامیده می شود و شامل موارد زیر است:
- با توجه به تخمین $X_((n-1))(\mbox (ots))$، تخمین $X_n$ با فرمول 4 برای $i = 1$ پیش بینی می شود: $X_(\mbox (noca priori)) = F_1X_((n-1 )ots)$. این یک برآورد پیشینی است.
- با توجه به نتایج مشاهدات فعلی $z_n$، این تخمین پیشینی به یک تخمین واقعی تبدیل میشود، یعنی پسین.
- این روش در هر مرحله تکرار می شود، از $r+1$ شروع می شود، جایی که $r$ ترتیب فیلتر است.
فرمول نهایی فیلتر بازگشتی به صورت زیر است:
$X_((n-1)ots) = X_(\mbox (nocapriori)) + (H^T_nH_n)^(-1)h^T_0(z_n - h_0 X_(\mbox (nocapriori)))$, (6 )
کجا برای فیلتر سفارش دوم ما:
فیلتر حافظه در حال رشد که طبق فرمول 6 کار می کند، یک مورد خاص از الگوریتم فیلتر شناخته شده به عنوان فیلتر کالمن است.
در اجرای عملی این فرمول، باید به خاطر داشت که برآورد پیشینی موجود در آن با فرمول 4 تعیین می شود و مقدار $h_0 X_(\mbox (nocapriori))$ اولین جزء بردار $X_( \mbox (nocapriori))$.
فیلتر حافظه در حال رشد یک ویژگی مهم دارد. با نگاهی به فرمول 6، امتیاز نهایی مجموع بردار امتیاز پیش بینی شده و عبارت تصحیح است. این تصحیح برای $n$ کوچک بزرگ است و با افزایش $n$ کاهش می یابد و به عنوان $n \rightarrow \infty$ به صفر می رسد. یعنی با رشد n، خواص صاف کننده فیلتر رشد می کند و مدل تعبیه شده در آن شروع به تسلط می کند. اما سیگنال واقعی فقط می تواند با مدل روشن مطابقت داشته باشد بخش های جداگانه، بنابراین دقت پیش بینی بدتر می شود.
برای مبارزه با این، با شروع از حدود $n$، ممنوعیتی برای کاهش بیشتر مدت اصلاح اعمال می شود. این معادل تغییر باند فیلتر است، یعنی برای n کوچک، فیلتر پهنای باند بیشتری دارد (اینرسی کمتر)، برای n بزرگ، اینرسی بیشتر می شود.
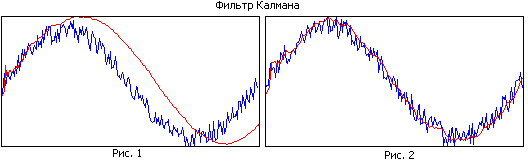
شکل 1 و شکل 2 را مقایسه کنید. در شکل اول، فیلتر دارای حافظه بزرگی است، در حالی که به خوبی صاف می شود، اما به دلیل باند باریک، مسیر تخمینی از مسیر واقعی عقب است. در شکل دوم، حافظه فیلتر کوچکتر است، بدتر هموار می شود، اما مسیر واقعی را بهتر دنبال می کند.
ادبیات
- Yu.M.Korshunov "مبانی ریاضی سایبرنتیک"
- A.V. Balakrishnan "نظریه فیلتراسیون کالمن"
- V.N. Fomin "تخمین تکراری و فیلتر تطبیقی"
- C.F.N. Cowen، P.M. اعطای "فیلترهای تطبیقی"
مطالعه ای در مورد استفاده از فیلتر کالمن در پیشرفت های مدرن پیچیده انجام شد سیستم های ناوبری. نمونه ای از ساخت یک مدل ریاضی با استفاده از فیلتر کالمن توسعه یافته برای بهبود دقت در تعیین مختصات هواپیماهای بدون سرنشین ارائه و تجزیه و تحلیل شده است. فیلتر جزئی در نظر گرفته شده است. ساخته شده است بررسی کوتاه آثار علمیاستفاده از این فیلتر برای بهبود قابلیت اطمینان و تحمل خطا در سیستم های ناوبری. این مقاله به ما امکان می دهد نتیجه بگیریم که استفاده از فیلتر کالمن در سیستم های موقعیت یابی پهپاد در بسیاری از پیشرفت های مدرن انجام می شود. تنوع و جنبه های بسیار زیادی در این استفاده وجود دارد که نتایج ملموسی را در بهبود دقت به ویژه در صورت خرابی سیستم های ناوبری ماهواره ای استاندارد می دهد. این عامل اصلی تأثیرگذاری این فناوری در زمینه های مختلف علمی مرتبط با توسعه سیستم های ناوبری دقیق و مقاوم در برابر خطا برای هواپیماهای مختلف است.
فیلتر کالمن
جهت یابی
هواپیمای بدون سرنشین (UAV)
1. Makarenko G.K., Aleshechkin A.M. بررسی الگوریتم فیلتر در تعیین مختصات یک جسم از سیگنال های سیستم های ناوبری رادیویی ماهواره ای Doklady TUSUR. - 2012. - شماره 2 (26). - ص 15-18.
2. Bar-Shalom Y., Li X. R., Kirubarajan T. Estimation with Applications
به ردیابی و ناوبری // الگوریتم ها و نرم افزارهای تئوری. - 2001. - جلد. 3. - ص 10-20.
3. Bassem I.S. ناوبری مبتنی بر دید (VBN) وسایل نقلیه هوایی بدون سرنشین (UAV) // دانشگاه کلگری. - 2012. - جلد. 1. - ص 100-127.
4. Conte G., Doherty P. یک سیستم ناوبری یکپارچه پهپاد بر اساس تطبیق تصویر هوایی // کنفرانس هوافضا. - 2008. -جلد. 1. - ص 3142-3151.
5. Guoqiang M., Drake S., Anderson B. طراحی فیلتر کالمن توسعه یافته برای محلی سازی uav // در اطلاعات، تصمیم گیری و کنترل. - 2007. - جلد. 7. - ص 224-229.
6. بهینه سازی مسیر Ponda S.S برای محلی سازی هدف با استفاده از وسایل نقلیه هوایی بدون سرنشین کوچک // موسسه فناوری ماساچوست. - 2008. - جلد. 1. - ص 64-70.
7. Wang J., Garrat M., Lambert A. ادغام سنسورهای gps/ins/vision برای هدایت وسایل نقلیه هوایی بدون سرنشین // IAPRS&SIS. - 2008. - جلد. 37. – ص 963-969.
یکی از وظایف فوری ناوبری مدرن هواپیماهای بدون سرنشین (UAV) وظیفه افزایش دقت در تعیین مختصات است. این مشکل با استفاده از گزینه های مختلف برای یکپارچه سازی سیستم های ناوبری حل می شود. یکی از انواع مدرن ادغام، ترکیب ناوبری gps/glonass با فیلتر کالمن توسعه یافته (Extended Kalmanfilter) است که به صورت بازگشتی دقت را با استفاده از اندازه گیری های ناقص و پر سر و صدا برآورد می کند. در حال حاضر، انواع مختلفی از فیلتر کالمن توسعه یافته وجود دارد و در حال توسعه است، از جمله تعداد متنوعی از متغیرهای حالت. در این کار نشان خواهیم داد که استفاده از آن تا چه حد می تواند در تحولات مدرن موثر باشد. بیایید یکی از نمایش های مشخصه چنین فیلتری را در نظر بگیریم.
ساخت یک مدل ریاضی
در این مثال، ما فقط در مورد حرکت پهپاد در صفحه افقی صحبت خواهیم کرد، در غیر این صورت، به اصطلاح مشکل محلی سازی 2d را در نظر خواهیم گرفت. در مورد ما، این با این واقعیت توجیه می شود که برای بسیاری از موقعیت های عملی، پهپاد می تواند تقریباً در همان ارتفاع باقی بماند. این فرض به طور گسترده ای برای ساده سازی مدل سازی دینامیک هواپیما استفاده می شود. مدل دینامیکی پهپاد توسط سیستم معادلات زیر ارائه می شود:
که در آن () - مختصات پهپاد در صفحه افقی به عنوان تابعی از زمان، جهت پهپاد، سرعت زاویه ای پهپاد و v سرعت زمین، عملکرد و ثابت در نظر گرفته خواهد شد. آنها متقابلا مستقل هستند، با کوواریانس های شناخته شده ![]() و به ترتیب برابر و و برای شبیه سازی تغییرات شتاب پهپاد ناشی از باد، مانورهای خلبان و غیره استفاده می شوند. مقادیر و از حداکثر سرعت زاویهای پهپاد و مقادیر تجربی تغییرات سرعت خطی پهپاد - نماد کرونکر - به دست میآیند.
و به ترتیب برابر و و برای شبیه سازی تغییرات شتاب پهپاد ناشی از باد، مانورهای خلبان و غیره استفاده می شوند. مقادیر و از حداکثر سرعت زاویهای پهپاد و مقادیر تجربی تغییرات سرعت خطی پهپاد - نماد کرونکر - به دست میآیند.
این سیستم معادلات به دلیل غیرخطی بودن در مدل و به دلیل وجود نویز تقریبی خواهد بود. ساده ترین تقریب در این مورد، تقریب اویلر است. مدل گسسته سیستم حرکت پویا پهپاد در زیر نشان داده شده است.
![]()
بردار حالت گسسته فیلتر کالمن، که امکان تقریبی مقدار یک بردار حالت پیوسته را فراهم می کند. ∆ - فاصله زمانی بین اندازه گیری k و k+1. () و () - دنباله ای از مقادیر نویز گاوسی سفید با میانگین صفر. ماتریس کوواریانس برای دنباله اول:
به طور مشابه، برای دنباله دوم:
پس از انجام جایگزینی مناسب در معادلات سیستم (2) به دست می آید:
دنباله ها و متقابل مستقل هستند. آنها همچنین توالی نویز گاوسی سفید با میانگین صفر با ماتریس کوواریانس و به ترتیب هستند. مزیت این شکل این است که تغییر در نویز گسسته بین هر اندازه گیری را نشان می دهد. در نتیجه مدل دینامیکی گسسته زیر را بدست می آوریم:
 (3)
(3)
معادله برای:
= ![]() + , (4)
+ , (4)
که در آن x و y مختصات پهپاد در نقطه k-time هستند و یک دنباله گاوسی از پارامترهای تصادفی با مقدار میانگین صفر است که برای تنظیم خطا استفاده می شود. این دنباله مستقل از () و () فرض می شود.
عبارات (3) و (4) به عنوان مبنایی برای تخمین مکان پهپاد، جایی است که مختصات k-امبا استفاده از فیلتر کالمن توسعه یافته به دست آمده است. مدل سازی خرابی سیستم های ناوبری در رابطه با این نوعفیلتر کارایی قابل توجه خود را نشان می دهد.
برای وضوح بیشتر، یک مثال کوچک ساده می آوریم. اجازه دهید برخی از پهپادها به طور یکنواخت و با مقداری شتاب ثابت پرواز کنند.
جایی که x مختصات پهپاد در زمان t است و δ مقداری متغیر تصادفی است.
فرض کنید ما یک حسگر GPS داریم که اطلاعات مربوط به موقعیت یک هواپیما را دریافت می کند. اجازه دهید نتیجه مدلسازی این فرآیند را در بسته نرم افزاری متلب ارائه کنیم.

برنج. 1. فیلتر خواندن سنسور با استفاده از فیلتر کالمن
روی انجیر 1 نشان می دهد که استفاده از فیلتر کالمن چقدر می تواند کارآمد باشد.
با این حال، در یک موقعیت واقعی، سیگنال ها اغلب دارای دینامیک غیر خطی و نویز غیرعادی هستند. در چنین مواردی است که از فیلتر کالمن توسعه یافته استفاده می شود. در صورتی که پراکندگی نویز خیلی زیاد نباشد (یعنی یک تقریب خطی کافی است)، استفاده از فیلتر کالمن توسعه یافته راه حلی برای مشکل با دقت بالا می دهد. با این حال، زمانی که نویز گاوسی نباشد، فیلتر کالمن توسعه یافته را نمی توان اعمال کرد. در این حالت معمولاً از یک فیلتر جزئی استفاده می شود که از روش های عددی برای گرفتن انتگرال بر اساس روش های مونت کارلو با زنجیره های مارکوف استفاده می کند.
فیلتر ذرات
بیایید یکی از الگوریتم هایی را تصور کنیم که ایده های فیلتر کالمن توسعه یافته را توسعه می دهد - یک فیلتر جزئی. فیلتر جزئی یک روش فیلتر زیر بهینه است که هنگام اجرای مونت کارلو با ترکیب بر روی مجموعه ای از ذرات که نشان دهنده توزیع احتمال فرآیند هستند، کار می کند. در اینجا یک ذره عنصری است که از توزیع قبلی پارامتر تخمین زده شده است. ایده اصلی فیلتر جزئی این است که می توان از تعداد زیادی ذرات برای نشان دادن تخمین توزیع استفاده کرد. هرچه تعداد ذرات استفاده شده بیشتر باشد، مجموعه ذرات با دقت بیشتری توزیع قبلی را نشان می دهد. فیلتر ذرات با قرار دادن N ذره در آن از توزیع قبلی پارامترهایی که میخواهیم تخمین بزنیم، مقداردهی اولیه میشود. الگوریتم فیلترینگ فرض می کند که این ذرات از آن عبور می کنند سیستم خاصو سپس وزن دهی با استفاده از اطلاعات به دست آمده از اندازه گیری این ذرات. ذرات حاصل و جرم های مرتبط با آن ها نشان دهنده توزیع خلفی فرآیند ارزیابی است. چرخه برای هر اندازه گیری جدید تکرار می شود و وزن ذرات برای نمایش توزیع بعدی به روز می شود. یکی از مشکلات اصلی روش سنتی فیلتر ذرات این است که نتیجه آن معمولاً چند ذره بسیار سنگین است، در مقابل بسیاری از ذرات دیگر که وزن بسیار سبکی دارند. این منجر به ناپایداری فیلتر می شود. این مشکل را می توان با معرفی یک نرخ نمونه برداری، که در آن N ذره جدید از توزیعی که از ذرات قدیمی تشکیل شده است، حل کرد. نتیجه ارزیابی با به دست آوردن نمونه ای از مقدار میانگین کثرت ذرات به دست می آید. اگر چندین نمونه مستقل داشته باشیم، میانگین نمونه تخمینی دقیق از میانگین خواهد بود و واریانس نهایی را تعریف می کند.
حتی اگر فیلتر ذرات بهینه نباشد، از آنجایی که تعداد ذرات به بی نهایت میل می کند، کارایی الگوریتم به قانون تخمین بیزی نزدیک می شود. بنابراین، داشتن ذرات تا حد امکان برای به دست آوردن مطلوب است بهترین نتیجه. متأسفانه، این منجر به افزایش شدید پیچیدگی محاسبات می شود و در نتیجه، جستجو برای مصالحه بین دقت و سرعت محاسبه را مجبور می کند. بنابراین، تعداد ذرات باید بر اساس الزامات مشکل ارزیابی دقت انتخاب شود. یکی دیگر از عوامل مهم برای عملکرد فیلتر ذرات، محدودیت در نرخ نمونه برداری است. همانطور که قبلا ذکر شد، نرخ نمونه برداری یک پارامتر مهم فیلتر ذرات است و بدون آن، الگوریتم در نهایت دچار انحطاط می شود. ایده این است که اگر وزن ها بیش از حد نابرابر توزیع شوند و آستانه نمونه برداری به زودی به دست آید، ذرات با وزن کم دور ریخته می شوند و مجموعه باقیمانده یک چگالی احتمال جدید را تشکیل می دهد که می توان نمونه های جدیدی برای آن برداشت کرد. انتخاب آستانه نرخ نمونه کار نسبتاً دشواری است، زیرا همچنین فرکانس بالاباعث می شود فیلتر بیش از حد به نویز حساس باشد و خیلی کم خطای زیادی می دهد. عامل مهم دیگر چگالی احتمال است.
به طور کلی، الگوریتم فیلتر ذرات عملکرد موقعیت یابی خوبی را برای اهداف ثابت و برای اهداف نسبتا آهسته با دینامیک شتاب ناشناخته نشان می دهد. به طور کلی، الگوریتم فیلتر ذرات پایدارتر از فیلتر کالمن توسعه یافته است و کمتر مستعد انحطاط و اشکالات شدید است. در موارد توزیع غیر خطی و غیر گاوسی این الگوریتمفیلتر کردن دقت مکان هدف بسیار خوبی را نشان می دهد، در حالی که الگوریتم فیلتر کالمن توسعه یافته تحت چنین شرایطی قابل استفاده نیست. معایب این روش شامل پیچیدگی بالاتر آن نسبت به فیلتر کالمن توسعه یافته و همچنین این واقعیت است که نحوه انتخاب پارامترهای مناسب برای این الگوریتم همیشه مشخص نیست.
تحقیقات امیدوارکننده در این زمینه
استفاده از یک مدل فیلتر کالمن مشابه مدلی که ارائه کردیم را می توان در آن مشاهده کرد که در آن برای بهبود عملکرد یک سیستم یکپارچه (GPS + مدل بینایی کامپیوتری برای تطبیق با یک پایگاه جغرافیایی) و وضعیت خرابی استفاده می شود. تجهیزات ناوبری ماهواره ای نیز شبیه سازی شده است. با کمک فیلتر کالمن، نتایج عملکرد سیستم در صورت خرابی به طور قابل توجهی بهبود یافت (به عنوان مثال، خطا در تعیین ارتفاع حدود دو برابر کاهش یافت و خطا در تعیین مختصات در محورهای مختلف کاهش یافت. تقریباً 9 برابر). استفاده مشابهی از فیلتر کالمن نیز در .
یک مشکل جالب از دیدگاه مجموعه ای از روش ها در حل شده است. همچنین از فیلتر کالمن 5 حالته استفاده می کند که تفاوت هایی در مدل سازی دارد. نتیجه به دست آمده به دلیل استفاده از ابزار اضافی ادغام (عکس و تصاویر حرارتی استفاده می شود) از نتیجه مدل ما بیشتر است. استفاده از فیلتر کالمن در این حالت امکان کاهش خطا در تعیین مختصات مکانی یک نقطه معین را به مقدار 5.5 متر می دهد.
نتیجه
در پایان خاطرنشان می کنیم که استفاده از فیلتر کالمن در سیستم های موقعیت یابی پهپاد در بسیاری از پیشرفت های مدرن انجام می شود. تنوع و جنبه های زیادی در این استفاده وجود دارد، تا استفاده همزمان از چندین فیلتر مشابه با فاکتورهای حالت متفاوت. یکی از نویدبخش ترین زمینه ها برای توسعه فیلترهای کالمن، کار بر روی ایجاد یک فیلتر اصلاح شده است که خطاهای آن با نویز رنگی نشان داده می شود که آن را برای حل مشکلات واقعی ارزشمندتر می کند. همچنین یک فیلتر جزئی که با آن می توان نویزهای غیر گاوسی را فیلتر کرد، در این هنر بسیار جالب است. این تنوع و نتایج ملموس در بهبود دقت به ویژه در صورت خرابی سیستم های ناوبری ماهواره ای استاندارد، از عوامل اصلی تأثیرگذار بر این فناوری در زمینه های مختلف علمی مرتبط با توسعه سیستم های ناوبری دقیق و مقاوم به خطا برای هواپیماهای مختلف است.
داوران:
Labunets V.G.، دکترای علوم فنی، پروفسور، استاد گروه مبانی نظریمهندسی رادیو دانشگاه فدرال اورال به نام اولین رئیس جمهور روسیه B.N. یلتسین، یکاترینبورگ؛
ایوانف V.E.، دکترای علوم فنی، پروفسور، رئیس. گروه فناوری و ارتباطات، دانشگاه فدرال اورال به نام اولین رئیس جمهور روسیه B.N. یلتسین، یکاترینبورگ
پیوند کتابشناختی
گاوریلوف A.V. استفاده از فیلتر KALMAN برای حل مشکلات پالایش مختصات پهپاد // مسائل معاصرعلم و آموزش - 2015. - شماره 1-1 .;URL: http://science-education.ru/ru/article/view?id=19453 (دسترسی: 02/01/2020). مجلات منتشر شده توسط انتشارات "آکادمی تاریخ طبیعی" را مورد توجه شما قرار می دهیم.