Analys av stora datamängder. Maskin för Big Data. Skalning och nivåindelning
Enligt forskning och trender
Big Data, "Big Data" har blivit det vanliga i IT- och marknadsföringspressen sedan flera år tillbaka. Och det är klart: digital teknik har genomsyrat livet modern man, "allt är skrivet." Datamängden om olika aspekter av livet växer och samtidigt växer möjligheterna att lagra information.
Globala teknologier för informationslagring
Källa: Hilbert och Lopez, "Världens tekniska kapacitet att lagra, kommunicera och beräkna information," Science, 2011 Global.
De flesta experter är överens om att accelererande datatillväxt är en objektiv realitet. Sociala nätverk, mobila enheter, data från mätenheter, företagsinformation är bara några typer av källor som kan generera enorma mängder information. Enligt forskning IDCDigitalt universum, publicerad 2012, de kommande 8 åren kommer mängden data i världen att nå 40 Zb (zettabyte), vilket motsvarar 5200 GB per invånare på planeten.
Tillväxt av insamlad digital information i USA

Källa: IDC
En betydande del av informationen skapas inte av människor, utan av robotar som interagerar både med varandra och med andra datanätverk, som till exempel sensorer och smarta enheter. Med denna tillväxttakt kommer mängden data i världen, enligt forskare, att fördubblas varje år. Antal virtuella och fysiska servrar i världen kommer att tiofaldigas på grund av utbyggnaden och skapandet av nya datacenter. I detta avseende finns det ett växande behov av effektiv användning och intäktsgenerering av dessa data. Eftersom användningen av Big Data i företag kräver avsevärda investeringar är det nödvändigt att tydligt förstå situationen. Och det är i grunden enkelt: du kan öka verksamhetens effektivitet genom att minska kostnaderna och/eller öka försäljningen.
Vad är Big Data till för?
Big Data-paradigmet definierar tre huvudtyper av uppgifter.
- Lagring och hantering av hundratals terabyte eller petabyte data som konventionella relationsdatabaser inte kan använda effektivt.
- Organisering av ostrukturerad information bestående av texter, bilder, videor och andra typer av data.
- Big Data-analys, som väcker frågan om hur man arbetar med ostrukturerad information, generering av analytiska rapporter och implementering av prediktiva modeller.
Big Data-projektmarknaden korsar marknaden för business intelligence (BA), vars volym i världen, enligt experter, 2012 uppgick till cirka 100 miljarder dollar. Det inkluderar komponenter av nätverksteknik, servrar, programvara och tekniska tjänster.
Användningen av Big Data-teknik är också relevant för lösningar i inkomstförsäkringsklass (RA) utformade för att automatisera företagens aktiviteter. Moderna inkomstgarantisystem inkluderar verktyg för att upptäcka inkonsekvenser och djupgående dataanalyser som möjliggör snabb upptäckt av eventuella förluster eller förvrängning av information som kan leda till lägre ekonomiska resultat. Mot denna bakgrund noterar ryska företag, som bekräftar efterfrågan på Big Data-teknik på den inhemska marknaden, att de faktorer som stimulerar utvecklingen av Big Data i Ryssland är tillväxten av data, accelerationen av ledningsbeslut och förbättringen av deras kvalitet.
Vad hindrar arbetet med Big Data
Idag analyseras endast 0,5 % av den ackumulerade digitala datan, trots att det objektivt sett finns branschgemensamma uppgifter som skulle kunna lösas med hjälp av analytiska lösningar Big data klass. Utvecklade IT-marknader har redan resultat som kan användas för att utvärdera förväntningarna i samband med ackumulering och bearbetning av big data.
En av de viktigaste faktorerna som bromsar implementeringen av Big Data-projekt, förutom höga kostnader, är problemet med att välja vilka uppgifter som ska behandlas: det vill säga definitionen av vilka data som ska extraheras, lagras och analyseras, och vilka som inte ska beaktas.
Många företagsrepresentanter noterar att svårigheterna med att implementera Big Data-projekt är förknippade med bristen på specialister - marknadsförare och analytiker. Avkastningen på investeringar i Big Data beror direkt på kvaliteten på arbetet hos anställda som är involverade i djup och prediktiv analys. Den enorma potentialen för data som redan finns i en organisation kan ofta inte effektivt utnyttjas av marknadsförare själva på grund av föråldrade affärsprocesser eller interna regler. Därför upplevs Big Data-projekt ofta av företag som svåra, inte bara i genomförandet, utan också för att utvärdera resultaten: värdet av den insamlade datan. Det specifika med att arbeta med data kräver att marknadsförare och analytiker flyttar sin uppmärksamhet från teknik och rapportering till att lösa specifika affärsproblem.
På grund av den stora volymen och hög hastighet dataflöde, processen för att samla in dem involverar ETL-procedurer i realtid. Som referens:ETL - frånengelskExtrahera, Omvandla, ladda- bokstavligen "extraktion, transformation, lastning") - en av huvudprocesserna i förvaltningen datalager, vilket inkluderar: extrahera data från Externa källor, deras förvandling och städning för att möta behov ETL ska ses inte bara som en process för att överföra data från en applikation till en annan, utan också som ett verktyg för att förbereda data för analys.
Och då bör frågorna om att säkerställa säkerheten för data som kommer från externa källor ha lösningar som motsvarar mängden information som samlas in. Eftersom Big Data-analysmetoder hittills utvecklas först efter att datavolymen har ökat, spelar analytiska plattformars förmåga att använda nya metoder för att förbereda och aggregera data en viktig roll. Detta tyder på att till exempel data om potentiella köpare eller ett massivt datalager med en historik av klick på webbbutikers sajter kan vara intressanta för att lösa olika problem.
Svårigheterna slutar inte
Trots alla svårigheter med implementeringen av Big Data avser verksamheten att öka investeringarna inom detta område. Enligt Gartners data, 2013, har 64 % av världens största företag redan investerat eller har planer på att investera i att implementera Big Data-teknik för sin verksamhet, medan det 2012 fanns 58 % av sådana företag. Enligt en Gartner-studie är ledarna för branscher som investerar i Big Data medieföretag, telekom, banksektorn och tjänsteföretag. Framgångsrika resultat av Big Data-implementering har redan uppnåtts av många stora aktörer inom detaljhandeln när det gäller att använda data som erhållits med RFID-verktyg, logistik och omlokaliseringssystem (från engelska. påfyllning- ackumulering, påfyllning - R&T), samt från lojalitetsprogram. Framgångsrik detaljhandelserfarenhet stimulerar andra marknadssektorer att hitta nya. effektiva sätt monetarisering av big data för att göra sin analys till en resurs som fungerar för affärsutveckling. Tack vare detta, enligt experter, under perioden fram till 2020 kommer investeringar i hantering och lagring att minska för varje gigabyte data från $2 till $0,2, men för studier och analys av de tekniska egenskaperna hos Big Data kommer att växa med endast 40 %.
De kostnader som presenteras i olika investeringsprojekt inom området Big Data är av olika karaktär. Kostnadsposter beror på vilka typer av produkter som väljs utifrån vissa beslut. Den största delen av kostnaderna i investeringsprojekt faller enligt experter på produkter relaterade till insamling, strukturering av data, städning och informationshantering.
Hur det är gjort
Det finns många kombinationer av mjukvara och hårdvara som låter dig skapa effektiva lösningar Big Data för olika affärsdiscipliner: från sociala medier och mobilapplikationer, innan intellektuell analys och visualisering av kommersiell data. En viktig fördel med Big Data är nya verktygs kompatibilitet med databaser som används i stor utsträckning i näringslivet, vilket är särskilt viktigt när man arbetar med tvärvetenskapliga projekt, som att organisera flerkanalsförsäljning och kundsupport.
Sekvensen av att arbeta med Big Data består av att samla in data, strukturera den mottagna informationen med hjälp av rapporter och dashboards (dashboard), skapa insikter och sammanhang samt formulera rekommendationer för åtgärder. Eftersom arbetet med Big Data innebär höga kostnader för att samla in data, vars bearbetningsresultat inte är känt i förväg, är huvuduppgiften att tydligt förstå vad data är till för, och inte hur mycket av det som finns tillgängligt. I det här fallet förvandlas datainsamling till en process för att få information som är extremt nödvändig för att lösa specifika problem.
Till exempel samlar telekommunikationsleverantörer en enorm mängd data, inklusive geolokalisering, som ständigt uppdateras. Denna information kan vara av kommersiellt intresse för reklambyråer, som kan använda den för att visa riktad och lokaliserad reklam, såväl som för återförsäljare och banker. Sådan information kan spela en viktig roll för att besluta om man ska öppna en butik på en viss plats baserat på data om närvaron av ett kraftfullt riktat flöde av människor. Det finns ett exempel på att mäta effektiviteten av reklam på utomhusreklamtavlor i London. Nu kan täckningen av sådan reklam endast mätas genom att placera människor nära reklamstrukturer med en speciell enhet som räknar förbipasserande. Jämfört med denna typ av mätning av reklameffektivitet, Mobil operatör mycket fler möjligheter - han vet exakt var sina prenumeranter befinner sig, han känner till deras demografiska egenskaper, kön, ålder, civilstånd etc.
Baserat på sådana uppgifter, i framtiden, öppnar utsikterna för att ändra innehållet i reklammeddelandet, med hjälp av preferenserna för en viss person som passerar skylten. Om uppgifterna visar att personen som passerar förbi reser mycket, kan de få en annons för resorten. Arrangörerna av en fotbollsmatch kan bara uppskatta antalet fans när de kommer till matchen. Men om de hade möjlighet att fråga operatören cellulär kommunikation information om var besökarna befann sig en timme, en dag eller en månad innan match, detta skulle ge arrangörerna möjlighet att planera platser för att annonsera nästa matcher.
Ett annat exempel är hur banker kan använda Big Data för att förhindra bedrägerier. Om kunden rapporterar förlusten av kortet, och när banken gör ett köp med det, ser banken i realtid platsen för kundens telefon i köpområdet där transaktionen äger rum, kan banken kontrollera informationen på kundens ansökan , om han försökte lura honom. Eller den motsatta situationen, när en kund gör ett köp i en butik, banken ser att kortet som transaktionen sker på och kundens telefon finns på samma plats, kan banken dra slutsatsen att dess ägare använder kortet. Tack vare dessa fördelar med Big Data utvidgas de gränser som traditionella datalager är utrustade med.
För ett framgångsrikt beslut att implementera Big Data-lösningar behöver ett företag räkna ut ett investeringscase, och detta orsakar stora svårigheter på grund av många okända komponenter. Paradoxen med analys i sådana fall är att förutsäga framtiden utifrån det förflutna, information om vilket ofta saknas. I det här fallet är en viktig faktor den tydliga planeringen av dina första åtgärder:
- För det första är det nödvändigt att bestämma ett specifikt affärsproblem, för vilket Big Data-teknik kommer att användas, denna uppgift kommer att bli kärnan för att bestämma riktigheten av det valda konceptet. Du måste fokusera på att samla in data relaterad till just denna uppgift, och under proof of concept kommer du att kunna använda olika verktyg, processer och hanteringsmetoder som gör att du kan fatta mer välgrundade beslut i framtiden.
- För det andra är det osannolikt att ett företag utan kompetens och erfarenhet av dataanalys kommer att kunna genomföra ett Big Data-projekt framgångsrikt. Den nödvändiga kunskapen kommer alltid från tidigare erfarenhet av analys, vilket är den viktigaste faktorn som påverkar kvaliteten på arbetet med data. En viktig roll spelas av kulturen att använda data, eftersom analysen av information ofta öppnas hård sanning om affärer, och för att acceptera och arbeta med denna sanning behövs utvecklade metoder för att arbeta med data.
- För det tredje ligger värdet av Big Data-teknik i att ge insikter. Bra analytiker är fortfarande en bristvara på marknaden. De kallas specialister som har en djup förståelse för den kommersiella innebörden av data och vet hur man tillämpar dem korrekt. Dataanalys är ett sätt att uppnå affärsmål, och för att förstå värdet av Big Data behöver du en lämplig beteendemodell och förståelse för dina handlingar. I det här fallet kommer big data att ge mycket användbar information om konsumenter, på grundval av vilka du kan fatta användbara affärsbeslut.
Trots att den ryska Big Data-marknaden precis börjar ta form, genomförs vissa projekt inom detta område redan ganska framgångsrikt. Några av dem är framgångsrika inom datainsamling, såsom projekt för Federal Tax Service och Tinkoff Credit Systems, andra när det gäller dataanalys och praktisk tillämpning av dess resultat: detta är Synqera-projektet.
Tinkoff Credit Systems Bank genomförde ett projekt för att implementera EMC2 Greenplum-plattformen, som är ett verktyg för massivt parallell beräkning. Under de senaste åren har banken ökat kraven på hastigheten för att bearbeta ackumulerad information och realtidsdataanalys, orsakat av höga tillväxttakt i antalet användare kreditkort. Banken tillkännagav planer på att utöka användningen av Big Data-teknik, särskilt för att bearbeta ostrukturerad data och arbeta med företagsinformation hämtade från olika källor.
Den federala skattetjänsten i Ryssland skapar för närvarande ett analytiskt lager av det federala datalagret. Baserat på det, en enhetlig informationsutrymme och skattedataåtkomstteknik för statistisk och analytisk bearbetning. Under genomförandet av projektet pågår ett arbete med att centralisera analytisk information med mer än 1200 källor från IFTS:s lokala nivå.
Annan intressant exempel analys av big data i realtid är den ryska startupen Synqera, som utvecklade Simplate-plattformen. Lösningen bygger på bearbetning av stora datamatriser, programmet analyserar information om kunder, deras köphistorik, ålder, kön och till och med humör. Vid kassorna i nätverket av kosmetiska butiker installerades pekskärmar med sensorer som känner igen kundernas känslor. Programmet bestämmer humöret hos en person, analyserar information om honom, bestämmer tiden på dagen och skannar rabattdatabasen i butiken, varefter det skickar riktade meddelanden till köparen om kampanjer och specialerbjudanden. Denna lösning förbättrar kundlojaliteten och ökar återförsäljarförsäljningen.
Om vi pratar om utländska framgångsrika fall, så är erfarenheten av att använda Big Data-teknik på Dunkin` Donuts, som använder realtidsdata för att sälja produkter, intressant i detta avseende. Digitala displayer i butiker visar erbjudanden som ändras varje minut, beroende på tid på dygnet och produkttillgänglighet. Enligt kassakvitton får företaget uppgifter om vilka erbjudanden som fått störst respons från köparna. Denna databehandlingsmetod gjorde det möjligt att öka vinsten och omsättningen av varor i lagret.
Som erfarenheten av att implementera Big Data-projekt visar är detta område utformat för att framgångsrikt lösa moderna affärsproblem. Samtidigt är en viktig faktor för att uppnå affärsmål när man arbetar med big data valet av rätt strategi, vilket inkluderar analyser som identifierar konsumentförfrågningar, samt användning av innovativa tekniker inom området Big Data.
Enligt en global undersökning som genomförs årligen av Econsultancy och Adobe sedan 2012 bland marknadsförare av företag kan "big data", som kännetecknar människors handlingar på Internet, göra mycket. De kan optimera offline affärsprocesser, hjälpa till att förstå hur mobila enhetsägare använder dem för att söka information eller helt enkelt "göra marknadsföring bättre", dvs. mer effektiv. Dessutom blir den sista funktionen mer populär från år till år, enligt vårt diagram.
De huvudsakliga arbetsområdena för Internetmarknadsförare när det gäller kundrelationer

Källa: Econsultancy och Adobe, publicerademarketer.com
Observera att respondenternas nationalitet Av stor betydelse har inte. Enligt en undersökning som KPMG gjorde 2013 är andelen "optimister", d.v.s. av dem som använder Big Data när de utvecklar en affärsstrategi är 56 %, och fluktuationerna från region till region är små: från 63 % i nordamerikanska länder till 50 % i EMEA.
Användning av Big Data i olika regioner i världen

Källa: KPMG, publicerademarketer.com
Samtidigt påminner marknadsförares attityd till sådana "modetrender" något om en välkänd anekdot:
Säg mig, Vano, gillar du tomater?
– Jag gillar att äta, men det gör jag inte.
Trots det faktum att marknadsförare säger att de "älskar" Big Data och till och med verkar använda det, är "allt komplicerat" i själva verket när de skriver om sina hjärtliga anknytningar i sociala nätverk.
Enligt en undersökning gjord av Circle Research i januari 2014 bland europeiska marknadsförare använder 4 av 5 tillfrågade inte Big Data (trots att de såklart ”älskar” det). Orsakerna är olika. Det finns få inbitna skeptiker - 17% och exakt samma antal som deras antipoder, d.v.s. de som självsäkert svarar "Ja". Resten tvekar och tvivlar, "träsket". De undviker ett direkt svar under rimliga ursäkter som "inte än, men snart" eller "vi väntar på att de andra ska börja."
Användning av Big Data av marknadsförare, Europa, januari 2014

Källa:dnx, publicerade -emarketer.com
Vad förvirrar dem? Rent nonsens. Vissa (exakt hälften av dem) tror helt enkelt inte på dessa uppgifter. Andra (det finns också en hel del av dem - 55%) har svårt att korrelera uppsättningarna "data" och "användare" sinsemellan. Någon har bara (låt oss uttrycka det politiskt korrekt) en intern företagsröra: data går ägarlöst mellan marknadsavdelningar och IT-strukturer. För andra kan programvaran inte klara av tillströmningen av arbete. Och så vidare. Eftersom de totala andelarna ligger långt över 100 % är det tydligt att situationen med "multipelbarriärer" inte är ovanlig.
Barriärer som hindrar användningen av Big Data i marknadsföring

Källa:dnx, publicerade -emarketer.com
Därför måste vi konstatera att "Big Data" än så länge är en stor potential som fortfarande behöver användas. Detta kan förresten vara anledningen till att Big Data tappar sin "modetrend"-gloria, vilket framgår av undersökningsdata som utförts av Econsultancy-företaget som vi redan har nämnt.
De viktigaste trenderna inom digital marknadsföring 2013-2014

Källa: Konsultverksamhet och Adobe
De ersätts av en annan kung – content marketing. Hur länge?
Det kan inte sägas att Big Data är något fundamentalt nytt fenomen. Stora datakällor har funnits i flera år: databaser över kundköp, kredithistorik, livsstilar. Och i åratal har forskare använt dessa data för att hjälpa företag att bedöma risker och förutsäga framtida kundbehov. Men idag har situationen förändrats i två aspekter:
Mer sofistikerade verktyg och metoder har dykt upp för att analysera och kombinera olika datamängder;
Dessa analysverktyg kompletteras av en lavin av nya datakällor som drivs av digitaliseringen av praktiskt taget alla datainsamlings- och mätmetoder.
Informationsutbudet är både inspirerande och skrämmande för forskare som växt upp i en strukturerad forskningsmiljö. Konsumentsentiment fångas av webbplatser och alla möjliga sociala medier. Faktumet att titta på annonser registreras inte bara set-top boxar, men också med digitala taggar och Mobil enheter kommunicera med TV.
Beteendedata (som antal samtal, köpvanor och köp) är nu tillgänglig i realtid. Således kan mycket av det som tidigare kunde läras genom forskning nu läras genom stora datakällor. Och alla dessa informationstillgångar genereras ständigt, oavsett forskningsprocesser. Dessa förändringar får oss att undra om big data kan ersätta klassisk marknadsundersökning.
Det handlar inte om data, det handlar om frågor och svar
Innan vi beordrar en dödsstöt för klassisk forskning måste vi påminna oss om att det inte är förekomsten av en eller annan datatillgång, utan något annat som är avgörande. Vad exakt? Vår förmåga att svara på frågor, det är vad. En rolig sak med den nya världen av big data är att resultat från nya datatillgångar leder till ännu fler frågor, och de frågorna brukar bäst besvaras av traditionell forskning. Allteftersom big data växer ser vi en parallell ökning av tillgängligheten och efterfrågan på ”small data” som kan ge svar på frågor från big data-världen.
Låt oss överväga en situation: en stor annonsör övervakar ständigt trafik i butiker och försäljningsvolymer i realtid. Befintliga forskningsmetoder (där vi frågar deltagare i forskningspaneler om deras köpmotiv och beteende vid försäljningsstället) hjälper oss att bättre rikta in oss på specifika kundsegment. Dessa metoder kan utökas till att inkludera ett bredare utbud av stora datatillgångar, till den punkt där big data blir ett passivt observationsverktyg och forskar om en metod för pågående, snävt fokuserad undersökning av förändringar eller händelser som behöver studeras. Så här kan big data befria forskning från onödig rutin. Primärforskning ska inte längre fokusera på vad som händer (big data kommer). Istället kan primärforskning fokusera på att förklara varför vi ser vissa trender eller avvikelser från trender. Forskaren kommer att kunna tänka mindre på att få data och mer på hur man analyserar och använder den.
Samtidigt ser vi att big data löser ett av våra största problem, problemet med alltför långa studier. Att granska själva studierna har visat att alltför uppblåsta forskningsverktyg har en negativ inverkan på datakvaliteten. Även om många experter erkände detta problem under lång tid, svarade de undantagslöst med frasen: "Men jag behöver den här informationen för ledningen", och långa intervjuer fortsatte.
I en värld av big data, där kvantitativa indikatorer kan erhållas genom passiv observation, blir denna fråga aktuell. Återigen, låt oss tänka tillbaka på all denna konsumtionsforskning. Om big data ger oss insikter om konsumtion genom passiv observation, behöver primärforskning i form av undersökningar inte längre samla in den här typen av information, och vi kan äntligen backa upp vår vision om korta undersökningar inte bara med lyckönskningar, utan också med något verkligt.
Big Data behöver din hjälp
Slutligen är "big" bara en av egenskaperna hos big data. Karakteristiken "stor" hänvisar till storleken och skalan på data. Naturligtvis är detta huvudegenskapen, eftersom volymen av dessa data ligger utanför omfattningen av allt som vi har arbetat med tidigare. Men andra egenskaper hos dessa nya dataströmmar är också viktiga: de är ofta dåligt formaterade, ostrukturerade (eller i bästa fall delvis strukturerade) och fulla av osäkerhet. Det framväxande området för datahantering, passande namnet "entity analytics", syftar till att lösa problemet med att övervinna brus i big data. Dess uppgift är att analysera dessa datamängder och ta reda på hur många observationer som är för samma person, vilka observationer som är aktuella och vilka av dem som är användbara.
Denna typ av datarensning är nödvändig för att ta bort brus eller felaktig data när man arbetar med stora eller små datatillgångar, men det räcker inte. Vi behöver också skapa sammanhang kring stora datatillgångar baserat på vår tidigare erfarenhet, analys och kategorikunskap. Faktum är att många analytiker pekar på förmågan att hantera den osäkerhet som är inneboende i big data som en källa till konkurrensfördelar, eftersom det möjliggör bättre beslutsfattande.
Och det är här primärforskningen inte bara frigörs från rutin tack vare big data, utan också bidrar till innehållsskapande och analys inom big data.
Ett utmärkt exempel på detta är tillämpningen av vårt helt nya ramverk för varumärkeskapital på sociala medier. (vi pratar om den som utvecklades iMillward Brunett nytt sätt att mäta varumärkesvärdeDe Meningsfullt Annorlunda Ramverk- "Paradigmet för betydande skillnader" -R & T ). Denna modell är beteendetestad inom specifika marknader, implementerad på standardbasis och kan lätt appliceras på andra marknadsföringsdiscipliner och beslutsstödjande informationssystem. Med andra ord, vår modell för varumärkeskapital, baserad på (men inte enbart) enkätundersökningar, har alla egenskaper som behövs för att övervinna big datas ostrukturerade, osammanhängande och osäkra natur.
Tänk på konsumenternas sentimentdata från sociala medier. I sin råa form är toppar och dalar i konsumenternas sentiment väldigt ofta minimalt korrelerade med offlinemått på varumärkeskapital och beteende: det är helt enkelt för mycket brus i data. Men vi kan minska detta brus genom att tillämpa våra modeller för konsumenternas mening, varumärkesdifferentiering, dynamik och identitet på rå konsumentsentimentdata, vilket är ett sätt att bearbeta och aggregera sociala mediers data längs dessa dimensioner.
När informationen väl är organiserad enligt vår rammodell, matchar de identifierade trenderna vanligtvis varumärkets aktier och beteendemätningar som erhålls offline. Faktum är att data från sociala medier inte kan tala för sig själv. För att använda dem för detta ändamål krävs vår erfarenhet och modeller byggda kring varumärken. När sociala medier ger oss unik information uttryckt på det språk som konsumenter använder för att beskriva varumärken, måste vi använda det språket när vi skapar vår forskning för att göra primärforskningen mycket mer effektiv.
Fördelar med undantagna studier
Detta för oss tillbaka till det faktum att big data inte så mycket ersätter forskning utan frigör den. Forskare kommer att vara lättade över att behöva skapa en ny studie för varje nytt fall. De ständigt växande tillgångarna med big data kan användas för olika forskningsämnen, vilket gör att efterföljande primärforskning kan fördjupa sig djupare i ämnet och fylla i luckorna. Forskare kommer att befrias från att behöva förlita sig på alltför uppblåsta undersökningar. Istället kommer de att kunna använda sig av korta undersökningar och fokusera på de viktigaste parametrarna, vilket förbättrar kvaliteten på datan.
Med den här versionen kommer forskare att kunna använda sina etablerade principer och insikter för att lägga till precision och mening till stora datatillgångar, vilket leder till nya områden för enkätforskning. Denna cykel bör leda till en djupare förståelse för en rad strategiska frågor och i slutändan ett steg mot det som alltid bör vara vårt huvudmål - att informera och förbättra kvaliteten på varumärkes- och kommunikationsbeslut.
Vanligtvis, när de pratar om seriös analytisk bearbetning, speciellt om de använder termen Data Mining, menar de att det finns en enorm mängd data. I det allmänna fallet är detta inte fallet, för ganska ofta måste du bearbeta små datamängder, och det är inte lättare att hitta mönster i dem än i hundratals miljoner poster. Även om det inte råder någon tvekan om att behovet av att söka efter mönster i stora databaser komplicerar den redan icke-triviala uppgiften att analysera.
Denna situation är särskilt typisk för företag relaterade till detaljhandeln, telekommunikation, banker, internet. Deras databaser samlar en enorm mängd information relaterad till transaktioner: checkar, betalningar, samtal, loggar, etc.
Det finns inga universella analysmetoder eller algoritmer som är lämpliga för alla fall och vilken mängd information som helst. Dataanalysmetoder skiljer sig markant från varandra när det gäller prestanda, resultatkvalitet, användarvänlighet och datakrav. Optimering kan utföras på olika nivåer: utrustning, databaser, analytisk plattform, initial dataförberedelse, specialiserade algoritmer. Analysen av en stor mängd data kräver ett speciellt tillvägagångssätt, eftersom det är tekniskt svårt att bearbeta dem med endast " råstyrka", det vill säga att använda kraftfullare utrustning.
Naturligtvis kan du öka hastigheten på databehandlingen tack vare mer produktiv utrustning, särskilt eftersom moderna servrar och arbetsstationer använder flerkärniga processorer, Bagge betydande storlek och kraftfulla diskarrayer. Det finns dock många andra sätt att bearbeta stora mängder data som gör att du kan öka skalbarheten och inte kräver oändlig uppdatering Utrustning.
DBMS-funktioner
Moderna databaser inkluderar olika mekanismer, vars användning kommer att avsevärt öka hastigheten på analytisk bearbetning:
- Preliminär beräkning av data. Information som oftast används för analys kan beräknas i förväg (till exempel nattetid) och lagras i en form förberedd för bearbetning på databasservern i form av flerdimensionella kuber, materialiserade vyer, speciella tabeller.
- Tabellcache i RAM. Data som tar lite plats, men som ofta nås under analysen, till exempel kataloger, kan cachas i RAM med hjälp av databasverktygen. På så sätt reduceras anrop till det långsammare diskundersystemet många gånger om.
- Partitionera tabeller i partitioner och tabellutrymmen. Du kan placera data, index, hjälptabeller på separata diskar. Detta gör att DBMS kan läsa och skriva information till diskar parallellt. Dessutom kan tabeller delas in i sektioner (partition) på ett sådant sätt att det finns ett minsta antal diskoperationer vid åtkomst till data. Om vi till exempel oftast analyserar data för den senaste månaden, så kan vi logiskt använda en tabell med historiska data, men fysiskt dela upp den i flera sektioner, så att ett litet avsnitt läses och det finns inga åtkomster när vi får åtkomst till månadsdata till alla historiska data.
Detta är bara en del av de möjligheter som moderna DBMS ger. Du kan öka hastigheten för att extrahera information från databasen på ett dussin andra sätt: rationell indexering, bygga frågeplaner, parallell bearbetning av SQL-frågor, använda kluster, förbereda analyserad data med hjälp av lagrade procedurer och triggers på databasserversidan, etc. Dessutom kan många av dessa mekanismer användas med inte bara "tunga" DBMS, utan även gratis databaser.
Kombination av modeller
Möjligheterna att förbättra hastigheten är inte begränsade till databasoptimering, mycket kan göras genom att kombinera olika modeller. Det är känt att bearbetningshastigheten är väsentligt relaterad till komplexiteten hos den använda matematiska apparaten. Ju enklare analysmekanismer som används, desto snabbare analyseras data.
Det är möjligt att bygga ett databehandlingsscenario på ett sådant sätt att datan "drivs" genom sållen av modeller. En enkel idé gäller här: slösa inte tid på att bearbeta det du inte kan analysera.
De enklaste algoritmerna används först. En del av den data som kan bearbetas med hjälp av sådana algoritmer och som är meningslös att bearbeta med mer komplexa metoder, analyseras och exkluderas från vidare bearbetning. Återstående data förs vidare till nästa steg av bearbetningen, där mer komplexa algoritmer används, och så vidare i kedjan. Vid den sista noden av bearbetningsscenariot används de mest komplexa algoritmerna, men mängden analyserad data är många gånger mindre än det ursprungliga provet. Som ett resultat reduceras den totala tiden som krävs för att bearbeta all data i storleksordningar.
Låt oss ta praktiskt exempel med detta tillvägagångssätt. När du löser problemet med efterfrågeprognoser rekommenderas det initialt att göra en XYZ-analys, som låter dig bestämma hur stabil efterfrågan på olika varor är. Produkter i grupp X säljs ganska stabilt, så användningen av prognosalgoritmer för dem gör att du kan få en högkvalitativ prognos. Grupp Y-produkter säljs mindre stabilt, kanske för dem är det värt att bygga modeller inte för varje artikel, men för gruppen låter detta dig jämna ut tidsserien och säkerställa driften av prognosalgoritmen. Grupp Z-produkter säljs slumpmässigt, så du bör inte bygga prediktiva modeller för dem alls, behovet av dem bör beräknas utifrån enkla formler, till exempel genomsnittlig månadsförsäljning.
Enligt statistiken består cirka 70 % av sortimentet av varor i grupp Z. Ytterligare 25 % är varor i grupp Y, och endast cirka 5 % är varor i grupp X. Således är konstruktion och tillämpning av komplexa modeller relevant för en maximalt 30 % av varorna. Därför kommer tillämpningen av tillvägagångssättet som beskrivs ovan att minska tiden för analys och prognoser med 5-10 gånger.
Parallell bearbetning
En annan effektiv strategi för att bearbeta stora mängder data är att dela upp data i segment och bygga modeller för varje segment separat, med ytterligare sammanslagning av resultaten. Oftast, i stora datamängder, kan flera distinkta delmängder särskiljas från varandra. Det kan till exempel vara grupper av kunder, varor som beter sig på liknande sätt och som det är lämpligt att bygga en modell för.
I det här fallet, istället för att bygga en komplex modell för alla, kan du bygga flera enkla modeller för varje segment. Detta tillvägagångssätt förbättrar analyshastigheten och minskar minneskraven genom att bearbeta mindre mängder data i ett enda pass. Dessutom kan analytisk bearbetning i detta fall parallelliseras, vilket också har en positiv effekt på tidsåtgången. Dessutom kan modeller för varje segment byggas av olika analytiker.
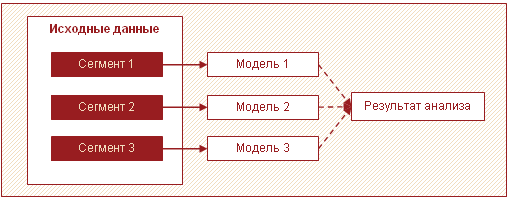
Förutom att öka hastigheten har detta tillvägagångssätt en annan viktig fördel - flera relativt enkla modeller individuellt är lättare att skapa och underhålla än en stor. Du kan köra modellerna i etapper och på så sätt få de första resultaten på kortast möjliga tid.
Representativa prover
I närvaro av stora mängder data är det möjligt att inte använda all information för att bygga en modell, utan en delmängd - ett representativt urval. Ett korrekt förberett representativt prov innehåller den information som behövs för att bygga en kvalitetsmodell.
Processen för analytisk bearbetning är uppdelad i 2 delar: bygga en modell och tillämpa den byggda modellen på ny data. Att bygga en komplex modell är en resurskrävande process. Beroende på vilken algoritm som används, cachelagras data, skannas tusentals gånger, många hjälpparametrar beräknas etc. Tillämpningen av den redan konstruerade modellen på ny data kräver resurser tiotals och hundratals gånger mindre. Mycket ofta handlar det om att beräkna några enkla funktioner.
Således, om modellen byggs på relativt små uppsättningar och därefter appliceras på hela datamängden, kommer tiden för att erhålla resultatet att reduceras med storleksordningar jämfört med ett försök att helt omarbeta hela den befintliga datamängden.

För att få representativa prover finns speciella metoder, till exempel provtagning. Deras användning gör att du kan öka hastigheten på analytisk bearbetning utan att offra kvaliteten på analysen.
Sammanfattning
De beskrivna tillvägagångssätten är bara en liten del av metoderna som låter dig analysera enorma mängder data. Det finns andra sätt, till exempel användning av speciella skalbara algoritmer, hierarkiska modeller, fönsterinlärning och så vidare.
Analys enorma baser data är en icke-trivial uppgift, som i de flesta fall inte kan lösas "head on", dock erbjuder moderna databaser och analytiska plattformar många metoder för att lösa detta problem. När de används på ett klokt sätt kan system behandla terabyte data i en rimlig takt.
Kolumn med HSE-lärare om myter och fall av arbete med big data
Till bokmärken
HSE School of New Media-föreläsarna Konstantin Romanov och Alexander Pyatigorsky, som också är chef för digital transformation på Beeline, skrev en krönika för sajten om de viktigaste missuppfattningarna om big data – exempel på teknikanvändning och verktyg. Författarna föreslår att publikationen kommer att hjälpa företagsledare att förstå detta koncept.
Myter och missuppfattningar om Big Data
Big Data är inte marknadsföring
Begreppet Big Data har blivit väldigt modernt – det används i miljontals situationer och i hundratals olika tolkningar, ofta inte relaterat till vad det är. Ofta i människors medvetande sker en ersättning av begrepp, och Big Data förväxlas med en marknadsföringsprodukt. Dessutom är Big Data i vissa företag en del av marknadsföringsdivisionen. Resultatet av big data-analys kan verkligen vara en källa för marknadsföringsaktivitet, men inget mer. Låt oss se hur det fungerar.
Om vi identifierade en lista över dem som köpte varor värda mer än tre tusen rubel i vår butik för två månader sedan och sedan skickade någon form av erbjudande till dessa användare, så är detta typisk marknadsföring. Vi härleder ett tydligt mönster från strukturdata och använder det för att öka försäljningen.
Men om vi kombinerar CRM-data med strömmande information, till exempel från Instagram, och analyserar den, hittar vi ett mönster: en person som har minskat sin aktivitet på onsdagskvällen och vars sista bild visar kattungar bör göra ett visst förslag. Det blir redan Big Data. Vi hittade triggern, gav den till marknadsförare och de använde den för sina egna syften.
Av detta följer att tekniken oftast arbetar med ostrukturerad data och om datan är strukturerad fortsätter systemet ändå att leta efter dolda mönster i dem, vilket marknadsföring inte gör.
Big Data är inte IT
Den andra ytterligheten av denna historia: Big Data förväxlas ofta med IT. Detta beror på det faktum att i ryska företag Som regel är det IT-specialister som är drivkrafterna för all teknologi, inklusive big data. Därför, om allt händer på den här avdelningen, för företaget som helhet verkar det som att detta är någon slags IT-aktivitet.
Det finns faktiskt en grundläggande skillnad här: Big Data är en aktivitet som syftar till att skaffa en viss produkt, som inte alls gäller IT, även om teknik inte kan existera utan dem.
Big Data är inte alltid insamling och analys av information
Det finns en annan missuppfattning om Big Data. Alla förstår att denna teknik är förknippad med stora datamängder, men vilken typ av data som avses är inte alltid klart. Alla kan samla in och använda information, nu är det möjligt inte bara i filmer om, utan också i vilket som helst, till och med ett mycket litet företag. Frågan är bara vad man ska samla in och hur man använder det till din fördel.
Men det bör förstås att Big Data-teknik inte kommer att vara insamling och analys av absolut all information. Om du till exempel samlar in data om en specifik person på sociala nätverk kommer det inte att vara Big Data.
Vad är Big Data egentligen
Big Data består av tre delar:
- data;
- analys;
- teknologi.
Big Data är inte bara en av dessa komponenter, utan en kombination av alla tre element. Ofta ersätter människor begrepp: någon tror att Big Data bara är data, någon tror att det är teknik. Men faktiskt, oavsett hur mycket data du samlar in, kan du inte göra något med den utan nödvändig teknik och analyser. Om det finns bra analyser, men ingen data, desto mer dålig.
Om vi pratar om data, så är detta inte bara texter, utan också alla bilder som läggs upp på Instagram, och i allmänhet allt som kan analyseras och användas för olika ändamål och uppgifter. Med andra ord, Data hänvisar till enorma mängder intern och extern data av olika strukturer.
Det behövs också analys, eftersom Big Datas uppgift är att bygga några mönster. Det vill säga, analys är identifieringen av dolda beroenden och sökandet efter nya frågor och svar baserat på analysen av hela volymen heterogen data. Dessutom väcker Big Data frågor som inte är direkt härledda från dessa data.
När det kommer till bilder säger det ingenting att du lagt upp ett foto på dig själv i en blå T-shirt. Men om du använder ett foto för Big Data-modellering, kan det visa sig att du just nu borde erbjuda ett lån, för i din sociala grupp indikerar detta beteende ett visst fenomen i handlingar. Därför är "bar" data utan analys, utan att avslöja dolda och icke-uppenbara beroenden, inte Big Data.
Så vi har big data. Deras utbud är enormt. Vi har också en analytiker. Men hur kan vi se till att en specifik lösning föds ur denna rådata? För att göra detta behöver vi teknologier som tillåter oss att inte bara lagra dem (och detta var omöjligt tidigare), utan också att analysera dem.
Enkelt uttryckt, om du har mycket data behöver du teknologier som Hadoop, som gör det möjligt att spara all information i sin ursprungliga form för senare analys. Sådan teknik uppstod i internetjättarna, eftersom de var de första att möta problemet med att lagra en stor mängd data och analysera den för efterföljande monetarisering.
Förutom verktyg för optimerad och billig datalagring behövs analytiska verktyg, samt tillägg till den plattform som används. Till exempel har ett helt ekosystem av relaterade projekt och teknologier redan bildats runt Hadoop. Här är några av dem:
- Gris är ett deklarativt dataanalysspråk.
- Hive - dataanalys med ett språk nära SQL.
- Oozie är ett arbetsflöde i Hadoop.
- Hbase - databas (icke-relationell), analog med Google Big Table.
- Mahout - maskininlärning.
- Sqoop - dataöverföring från RSDDB till Hadoop och vice versa.
- Flume - överföring av stockar till HDFS.
- Zookeeper, MRUnit, Avro, Giraph, Ambari, Cassandra, HCatalog, Fuse-DFS och så vidare.
Alla dessa verktyg är tillgängliga för alla gratis, men det finns också en uppsättning betalda tillägg.
Dessutom behövs specialister: det här är en utvecklare och en analytiker (den så kallade Data Scientist). Du behöver också en chef som kan förstå hur man tillämpar denna analys på en specifik uppgift, eftersom det i sig är helt meningslöst om det inte är inbyggt i affärsprocesser.
Alla tre anställda ska arbeta som ett team. En chef som ger en Data Scientist i uppdrag att hitta ett visst mönster måste förstå att det inte alltid går att hitta exakt det han behöver. I det här fallet bör chefen lyssna noga på vad datavetaren har hittat, eftersom hans resultat ofta visar sig vara mer intressanta och användbara för verksamheten. Din uppgift är att tillämpa det på företag och göra en produkt av det.
Trots att det nu finns många olika typer av maskiner och teknologier, ligger det slutliga beslutet alltid hos personen. För att göra detta måste informationen visualiseras på något sätt. Det finns en hel del verktyg för detta.
Det mest belysande exemplet är geoanalytiska rapporter. Beeline-företaget arbetar mycket med regeringarna i olika städer och regioner. Mycket ofta beställer dessa organisationer rapporter som "Trafikbelastning på en specifik plats."
Det är tydligt att en sådan anmälan ska nå statliga myndigheter i en enkel och begriplig form. Om vi förser dem med en enorm och helt obegriplig tabell (det vill säga information i den form vi tar emot den), är det osannolikt att de kommer att köpa en sådan rapport - det kommer att vara helt värdelöst, de kommer inte att få ut kunskapen ur det som de ville ta emot.
Därför, oavsett hur bra datavetare är och oavsett vilka mönster de hittar, kommer du inte att kunna arbeta med denna data utan kvalitetsvisualiseringsverktyg.
Datakällor
Uppsättningen av mottagna data är mycket stor, så den kan delas in i några grupper.
Företagets interna data
Även om 80 % av de insamlade uppgifterna tillhör denna grupp, används inte alltid denna källa. Ofta är detta data som, verkar det som, ingen behöver alls, till exempel loggar. Men om man tittar på dem från en annan vinkel kan man ibland hitta oväntade mönster i dem.
Shareware-källor
Detta inkluderar data sociala nätverk, Internet och allt där du kan komma in gratis. Varför shareware? Å ena sidan är denna data tillgänglig för alla, men om du är ett stort företag är det inte längre en lätt uppgift att få den i storleken på en abonnentbas på tiotusentals, hundratals eller miljoner kunder. Därför har marknaden betaltjänster att tillhandahålla dessa uppgifter.
Betalda källor
Detta inkluderar företag som säljer data för pengar. Dessa kan vara telekom, DMP:er, internetföretag, kreditbyråer och aggregatorer. I Ryssland säljer inte telekom data. För det första är det ekonomiskt olönsamt, och för det andra är det förbjudet enligt lag. Därför säljer de resultatet av sin bearbetning, till exempel geoanalytiska rapporter.
öppna data
Staten möter näringslivets behov och gör det möjligt att använda den data de samlar in. I större utsträckning utvecklas detta i västvärlden, men även Ryssland hänger med i tiden i detta avseende. Till exempel finns det Open Data Portal från Moskvas regering, som publicerar information om olika objekt i urban infrastruktur.
För invånare och gäster i Moskva presenteras data i tabellform och kartografi, och för utvecklare - i speciella maskinläsbara format. Medan projektet arbetar i ett begränsat läge, men utvecklas, vilket innebär att det också är en datakälla som du kan använda för dina affärsuppgifter.
Forskning
Som redan nämnts är Big Datas uppgift att hitta ett mönster. Ofta kan studier runt om i världen bli en referenspunkt för att hitta ett visst mönster – du kan få ett specifikt resultat och försöka tillämpa en liknande logik på dina mål.
Big Data är ett område där inte alla matematiska lagar fungerar. Till exempel är "1" + "1" inte "2", utan mycket mer, för när man blandar datakällor kan effekten förstärkas avsevärt.
Produktexempel
Många människor är bekanta med Spotifys musikvalstjänst. Det fina med det är att det inte frågar användarna vad deras humör är idag, utan i stället beräknar det baserat på de tillgängliga källorna. Han vet alltid vad du behöver nu – jazz eller hårdrock. Detta är den viktigaste skillnaden som ger honom fans och som skiljer honom från andra tjänster.

Sådana produkter brukar kallas sense-produkter - de som känner sin kund.
Big Data-teknik används även inom fordonsindustrin. Till exempel gör Tesla detta - i deras Senaste Modell det finns en autopilot. Företaget strävar efter att skapa en bil som tar passageraren dit han behöver åka. Utan Big Data är detta omöjligt, för om vi bara använder den data som vi tar emot direkt, som en person gör, så kommer inte bilen att kunna förbättras.

När vi själva kör bil använder vi våra nervceller för att fatta beslut baserat på många faktorer som vi inte ens märker. Vi kanske till exempel inte inser varför vi bestämde oss för att inte genast tända grönt ljus, och då visar det sig att beslutet var korrekt – en bil svepte förbi dig i rasande fart, och du undvek en olycka.
Du kan också ge ett exempel på användningen av Big Data inom sport. År 2002 bestämde sig chefen för Oakland Athletics basebolllag, Billy Bean, för att bryta paradigmet för hur man söker efter idrottare - han valde och tränade spelare "efter siffrorna."
Vanligtvis tittar chefer på spelarnas framgång, men i det här fallet var det annorlunda - för att få resultatet studerade chefen vilka kombinationer av idrottare han behövde och uppmärksammade individuella egenskaper. Dessutom valde han idrottare som i sig inte representerade någon stor potential, men laget som helhet visade sig vara så framgångsrikt att de vann tjugo matcher i rad.

Regissören Bennett Miller gjorde därefter en film dedikerad till den här historien - "The Man Who Changed Everything" med Brad Pitt i huvudrollen.
Big Data-teknik är också användbar inom finanssektorn. Inte en enda person i världen kan självständigt och exakt avgöra om det är värt att ge någon ett lån. För att fatta ett beslut görs poängsättning, det vill säga en sannolikhetsmodell byggs upp med hjälp av vilken man kan förstå om denna person kommer att returnera pengarna eller inte. Vidare tillämpas poängsättning i alla stadier: du kan till exempel beräkna att en person vid ett visst tillfälle kommer att sluta betala.
Big data tillåter inte bara att tjäna pengar, utan också att spara dem. I synnerhet hjälpte denna teknik det tyska arbetsministeriet att minska kostnaderna för arbetslöshetsersättningen med 10 miljarder euro, eftersom det efter att ha analyserat informationen stod klart att 20 % av ersättningarna betalades ut oförtjänt.
Teknologier används också inom medicin (detta gäller särskilt för Israel). Med hjälp av Big Data kan du göra en mycket mer exakt analys än vad en läkare med trettio års erfarenhet kan göra.
Varje läkare, när han ställer en diagnos, förlitar sig endast på sin egen erfarenhet. När maskinen gör det kommer det från erfarenheten från tusentals sådana läkare och alla befintliga fallhistorier. Det tar hänsyn till vilket material patientens hus är gjort av, vilket område offret bor i, vilken rök som finns där osv. Det vill säga att den tar hänsyn till en hel del faktorer som läkare inte tar hänsyn till.
Ett exempel på användningen av Big Data inom vården är projektet Artemis, som genomfördes av Toronto Children's Hospital. Det Informationssystem, som samlar in och analyserar data om spädbarn i realtid. Maskinen låter dig analysera 1260 hälsoindikatorer för varje barn varje sekund. Detta projekt syftar till att förutsäga barnets instabila tillstånd och förebygga sjukdomar hos barn.
Big data börjar också användas i Ryssland: till exempel har Yandex en big data division. Företaget, tillsammans med AstraZeneca och Russian Society of Clinical Oncology RUSSCO, lanserade RAY-plattformen för genetiker och molekylärbiologer. Projektet förbättrar metoderna för att diagnostisera cancer och identifiera anlag för cancer. Plattformen kommer att lanseras i december 2016.
Termen Big Data syftar vanligtvis på vilken mängd strukturerad, semistrukturerad och ostrukturerad data som helst. Den andra och tredje kan och bör dock beställas för efterföljande analys av information. Big data är inte lika med någon faktisk volym, men på tal om Big Data i de flesta fall menar vi terabyte, petabyte och till och med extrabyte av information. Denna mängd data kan ackumuleras i alla företag över tiden, eller, i de fall ett företag behöver ta emot mycket information, i realtid.
Big Data Analys
På tal om analys av Big Data menar vi först och främst insamling och lagring av information från olika källor. Till exempel data om kunder som gjort köp, deras egenskaper, information om lanserade reklamföretag och utvärdering av dess effektivitet, data kontaktcenter. Ja, all denna information kan jämföras och analyseras. Det är möjligt och nödvändigt. Men för detta måste du sätta upp ett system som låter dig samla in och omvandla information utan att förvränga information, lagra den och slutligen visualisera den. Håller med, med big data kommer tabeller utskrivna på flera tusen sidor inte att hjälpa mycket för att fatta affärsbeslut.
1. Ankomsten av big data
De flesta tjänster som samlar in information om användaråtgärder har möjlighet att exportera. För att de ska komma in i företaget i en strukturerad form används olika, till exempel Alteryx. Denna programvara låter dig ta emot automatiskt läge information, bearbeta den, men viktigast av allt, omvandla den till önskad vy och formatera utan att förvränga.
2. Lagring och bearbetning av big data
Nästan alltid, när man samlar in stora mängder information, uppstår problemet med dess lagring. Av alla plattformar som vi studerade föredrar vårt företag Vertica. Till skillnad från andra produkter kan Vertica snabbt "ge" den information som lagras i den. Till nackdelarna hör en lång inspelning, men under analysen av big data kommer returhastigheten i förgrunden. Till exempel, om vi pratar om att kompilera med en petabyte av information, är uppladdningshastighet en av de viktigaste egenskaperna.
3. Visualisering av Big Data
Och slutligen är det tredje steget i analysen av stora mängder data . Detta kräver en plattform som visuellt kan återspegla all information som tas emot i en bekväm form. Enligt vår uppfattning kan endast en mjukvaruprodukt, Tableau, klara av uppgiften. Helt klart en av de bästa på i dag en lösning som visuellt kan visa vilken information som helst, förvandla företagets arbete till en tredimensionell modell, samla alla avdelningars handlingar i en enda ömsesidigt beroende kedja (du kan läsa mer om Tableaus kapacitet).
Istället för en sammanfattning noterar vi att nästan alla företag nu kan generera sin egen Big Data. Big data-analys är inte längre en komplex och dyr process. Företagsledningen är nu skyldig att korrekt formulera frågor till insamlad information, medan det praktiskt taget inte finns några osynliga gråzoner.
Ladda ner tablå