Analýza veľkých objemov údajov. Stroj na veľké dáta. Škálovanie a vrstvenie
Podľa výskumu a trendov
Big Data, „Big Data“ sa v IT a marketingovej tlači hovorí už niekoľko rokov. A je to jasné: digitálne technológie prenikli do života moderný človek, "všetko je napísané." Rastie objem údajov o rôznych aspektoch života a zároveň rastú aj možnosti uchovávania informácií.
Globálne technológie na ukladanie informácií
Zdroj: Hilbert a Lopez, „Svetová technologická kapacita na ukladanie, komunikáciu a výpočet informácií“, Science, 2011 Global.
Väčšina odborníkov súhlasí s tým, že zrýchlenie rastu dát je objektívnou realitou. Sociálne siete, mobilné zariadenia, údaje z meracích zariadení, obchodné informácie sú len niekoľkými typmi zdrojov, ktoré dokážu generovať obrovské množstvo informácií. Podľa výskumu IDCDigitálny vesmír, zverejnenej v roku 2012, bude v nasledujúcich 8 rokoch množstvo dát na svete dosahovať 40 Zb (zettabajtov), čo je ekvivalent 5200 GB na obyvateľa planéty.
Rast zhromaždených digitálnych informácií v USA

Zdroj: IDC
Značnú časť informácií nevytvárajú ľudia, ale roboty interagujúce medzi sebou a s inými dátovými sieťami, ako sú napríklad senzory a inteligentné zariadenia. Pri tomto tempe rastu sa množstvo údajov vo svete podľa výskumníkov každý rok zdvojnásobí. Počet virtuálnych a fyzické servery na svete desaťnásobne narastie vďaka rozširovaniu a vytváraniu nových dátových centier. V tejto súvislosti narastá potreba efektívneho využívania a speňažovania týchto údajov. Keďže využitie Big Data v biznise si vyžaduje nemalé investície, je potrebné jasne pochopiť situáciu. A je to v podstate jednoduché: efektivitu podnikania môžete zvýšiť znížením nákladov a/alebo zvýšením predaja.
Na čo slúžia veľké dáta?
Paradigma veľkých dát definuje tri hlavné typy úloh.
- Ukladanie a správa stoviek terabajtov alebo petabajtov údajov, ktoré konvenčné relačné databázy nedokážu efektívne využiť.
- Organizácia neštruktúrovaných informácií pozostávajúcich z textov, obrázkov, videí a iných typov údajov.
- Big Data analýza, ktorá nastoľuje otázku, ako pracovať s neštruktúrovanými informáciami, generovanie analytických správ a implementácia prediktívnych modelov.
Trh projektov Big Data sa prelína s trhom business intelligence (BA), ktorého objem vo svete podľa odborníkov v roku 2012 predstavoval približne 100 miliárd dolárov. Zahŕňa komponenty sieťových technológií, servery, softvér a technické služby.
Používanie technológií veľkých dát je relevantné aj pre riešenia triedy zabezpečenia príjmu (RA), ktoré sú určené na automatizáciu činností spoločností. Moderné systémy garancie príjmu zahŕňajú nástroje na odhaľovanie nezrovnalostí a hĺbkovú analýzu dát, ktoré umožňujú včas odhaliť možné straty alebo skreslenie informácií, ktoré môžu viesť k nižším finančným výsledkom. Na tomto pozadí ruské spoločnosti, ktoré potvrdzujú dopyt po technológiách veľkých dát na domácom trhu, poznamenávajú, že faktory, ktoré stimulujú rozvoj veľkých dát v Rusku, sú rast dát, zrýchlenie manažérskeho rozhodovania a zlepšenie ich kvalitu.
Čo bráni práci s veľkými dátami
Dnes sa analyzuje iba 0,5 % nahromadených digitálnych údajov, napriek tomu, že objektívne existujú celoodvetvové úlohy, ktoré by bolo možné vyriešiť pomocou analytické riešenia Veľká dátová trieda. Rozvinuté IT trhy už majú výsledky, ktoré sa dajú použiť na vyhodnotenie očakávaní spojených s akumuláciou a spracovaním veľkých dát.
Jedným z hlavných faktorov, ktorý okrem vysokých nákladov spomaľuje implementáciu Big Data projektov, je problém výberu údajov na spracovanie: to je definícia toho, aké údaje by sa mali extrahovať, uchovávať a analyzovať a ktoré by sa nemali brať do úvahy.
Mnohí obchodní zástupcovia poznamenávajú, že ťažkosti pri implementácii projektov veľkých dát sú spojené s nedostatkom špecialistov - obchodníkov a analytikov. Miera návratnosti investícií do veľkých dát priamo závisí od kvality práce zamestnancov zapojených do hĺbkovej a prediktívnej analýzy. Obrovský potenciál dát, ktoré už v organizácii existujú, často nedokážu efektívne využiť samotní marketéri z dôvodu zastaraných obchodných procesov alebo interných predpisov. Preto sú projekty Big Data často vnímané podnikmi ako náročné nielen pri implementácii, ale aj pri vyhodnocovaní výsledkov: hodnoty zozbieraných dát. Špecifiká práce s údajmi si vyžadujú, aby obchodníci a analytici presunuli svoju pozornosť z technológie a výkazníctva na riešenie konkrétnych obchodných problémov.
Vzhľadom na veľký objem a vysoká rýchlosť tok údajov, proces ich zberu zahŕňa procedúry ETL v reálnom čase. Pre informáciu:ETL - odAngličtinaExtrakt, Transformovať, naložiť- doslova "extrakcia, transformácia, načítanie") - jeden z hlavných procesov v manažmente dátových skladov, čo zahŕňa: extrakciu údajov z externých zdrojov, ich transformácia a čistenie podľa potrieb ETL by sa malo vnímať nielen ako proces prenosu údajov z jednej aplikácie do druhej, ale aj ako nástroj na prípravu údajov na analýzu.
A potom otázky zaistenia bezpečnosti údajov pochádzajúcich z externých zdrojov by mali mať riešenia, ktoré zodpovedajú objemu zozbieraných informácií. Keďže metódy analýzy veľkých dát sa zatiaľ rozvíjajú až po raste objemu dát, dôležitú úlohu zohráva schopnosť analytických platforiem využívať nové metódy prípravy a agregácie dát. To naznačuje, že na riešenie rôznych problémov môžu byť zaujímavé napríklad údaje o potenciálnych kupcoch alebo masívny dátový sklad s históriou preklikov na stránkach internetového obchodu.
Ťažkosti neustávajú
Napriek všetkým ťažkostiam s implementáciou Big Data má biznis v úmysle zvýšiť investície do tejto oblasti. Podľa údajov Gartneru v roku 2013 už 64 % najväčších svetových spoločností investovalo alebo plánuje investovať do nasadenia Big Data technológií pre svoje podnikanie, pričom v roku 2012 to bolo 58 % takýchto spoločností. Podľa štúdie spoločnosti Gartner sú lídrami v odvetviach investujúcich do veľkých dát mediálne spoločnosti, telekomunikácie, bankový sektor a spoločnosti poskytujúce služby. Úspešné výsledky implementácie Big Data už dosiahli mnohí významní hráči v maloobchode, pokiaľ ide o využitie dát získaných pomocou RFID nástrojov, logistických a relokačných systémov (z angl. doplnenie- akumulácia, doplňovanie - R&T), ako aj z vernostných programov. Úspešné maloobchodné skúsenosti stimulujú ostatné sektory trhu, aby našli nové. efektívnymi spôsobmi monetizácia veľkých dát, aby sa ich analýza zmenila na zdroj, ktorý funguje pre rozvoj podnikania. Vďaka tomu sa podľa odborníkov v období do roku 2020 znížia investície do správy a úložiska na každý gigabajt dát z 2 dolára na 0,2 dolára, no na štúdium a analýzu technologických vlastností veľkých dát vzrastú len o 40 %.
Náklady prezentované v rôznych investičných projektoch v oblasti Big Data sú rôzneho charakteru. Nákladové položky závisia od typov produktov, ktoré sa vyberajú na základe určitých rozhodnutí. Najväčšia časť nákladov pri investičných projektoch pripadá podľa odborníkov na produkty súvisiace so zberom, štruktúrovaním dát, upratovaním a správou informácií.
Ako sa to robí
Existuje mnoho kombinácií softvéru a hardvér ktoré vám umožňujú vytvárať efektívne riešenia Big Data pre rôzne obchodné disciplíny: zo sociálnych médií a mobilných aplikácií, predtým intelektuálna analýza a vizualizácia obchodných údajov. Dôležitou výhodou Big Data je kompatibilita nových nástrojov s databázami široko používanými v podnikaní, čo je obzvlášť dôležité pri práci s medziodborovými projektmi, ako je organizovanie viackanálového predaja a zákaznícka podpora.
Postupnosť práce s veľkými údajmi pozostáva zo zberu údajov, štruktúrovania prijatých informácií pomocou zostáv a dashboardov (dashboard), vytvárania prehľadov a kontextov a formulovania odporúčaní na akciu. Keďže práca s veľkými údajmi znamená vysoké náklady na zber údajov, ktorých výsledok nie je vopred známy, hlavnou úlohou je jasne pochopiť, na čo sú údaje určené, a nie koľko z nich je k dispozícii. V tomto prípade sa zber dát mení na proces získavania informácií, ktoré sú mimoriadne potrebné pre riešenie konkrétnych problémov.
Napríklad poskytovatelia telekomunikačných služieb zhromažďujú obrovské množstvo údajov vrátane geolokácie, ktoré sa neustále aktualizujú. Tieto informácie môžu byť komerčne zaujímavé pre reklamné agentúry, ktoré ich môžu použiť na poskytovanie cielenej a lokalizovanej reklamy, ako aj pre maloobchodníkov a banky. Takéto údaje môžu hrať dôležitú úlohu pri rozhodovaní, či otvoriť maloobchodnú predajňu v konkrétnom mieste na základe údajov o prítomnosti silného cieleného toku ľudí. Existuje príklad merania účinnosti reklamy na vonkajších billboardoch v Londýne. Teraz je možné pokrytie takejto reklamy merať iba umiestnením ľudí v blízkosti reklamných stavieb pomocou špeciálneho zariadenia, ktoré počíta okoloidúcich. V porovnaní s týmto typom merania účinnosti reklamy mobilného operátora oveľa viac príležitostí - presne pozná polohu svojich predplatiteľov, pozná ich demografické charakteristiky, pohlavie, vek, rodinný stav atď.
Na základe takýchto údajov sa v budúcnosti záujemca otvára na zmenu obsahu reklamného posolstva s využitím preferencií konkrétnej osoby prechádzajúcej okolo billboardu. Ak údaje ukazujú, že okoloidúci veľa cestuje, môže sa mu zobraziť reklama na rezort. Organizátori futbalového zápasu môžu počet fanúšikov len odhadovať, keď prídu na zápas. Ale keby mali možnosť opýtať sa operátora celulárna komunikácia informácie o tom, kde boli návštevníci hodinu, deň alebo mesiac pred zápasom, by organizátorom umožnili naplánovať si miesta, kde budú propagovať ďalšie zápasy.
Ďalším príkladom je, ako môžu banky použiť Big Data na zabránenie podvodom. Ak klient nahlási stratu karty a pri nákupe s ňou banka vidí v reálnom čase polohu telefónu klienta v nákupnej oblasti, kde sa transakcia uskutočňuje, banka si môže tieto informácie skontrolovať v aplikácii klienta , či sa ho pokúsil oklamať. Alebo v opačnej situácii, keď klient nakúpi v obchode, banka vidí, že karta, na ktorej transakcia prebieha, a telefón klienta sú na tom istom mieste, banka môže usúdiť, že kartu používa jej majiteľ. Vďaka týmto výhodám Big Data sa rozširujú hranice, ktorými sú tradičné dátové sklady obdarené.
Pre úspešné rozhodnutie implementovať Big Data riešenia potrebuje spoločnosť vypočítať investičný prípad, čo spôsobuje veľké ťažkosti kvôli mnohým neznámym komponentom. Paradoxom analytiky v takýchto prípadoch je predpovedať budúcnosť na základe minulosti, o ktorej informácie často chýbajú. V tomto prípade je dôležitým faktorom jasné plánovanie vašich počiatočných akcií:
- V prvom rade je potrebné určiť jeden konkrétny biznis problém, na ktorý budú použité technológie Big Data, táto úloha sa stane jadrom určenia správnosti zvoleného konceptu. Musíte sa zamerať na zber údajov súvisiacich s touto konkrétnou úlohou a počas proof of concept budete môcť využívať rôzne nástroje, procesy a metódy riadenia, ktoré vám v budúcnosti umožnia robiť informovanejšie rozhodnutia.
- Po druhé, je nepravdepodobné, že spoločnosť bez zručností a skúseností v oblasti dátovej analýzy bude schopná úspešne implementovať projekt veľkých dát. Potrebné znalosti vždy vychádzajú z predchádzajúcich skúseností v analytike, ktorá je hlavným faktorom ovplyvňujúcim kvalitu práce s dátami. Dôležitú úlohu zohráva kultúra používania údajov, pretože často sa otvára analýza informácií krutá pravda o podnikaní a na prijatie a prácu s touto pravdou sú potrebné vyvinuté metódy práce s dátami.
- Po tretie, hodnota Big Data technológií spočíva v poskytovaní prehľadov. Dobrých analytikov je na trhu stále nedostatok. Hovorí sa im špecialisti, ktorí hlboko rozumejú komerčnému významu údajov a vedia ich správne aplikovať. Analýza údajov je prostriedkom na dosiahnutie obchodných cieľov a aby ste pochopili hodnotu veľkých údajov, potrebujete vhodný model správania a pochopenie svojich činností. V tomto prípade veľké dáta dajú veľa užitočná informácia o spotrebiteľoch, na základe ktorých môžete robiť užitočné obchodné rozhodnutia.
Napriek tomu, že ruský Big Data market sa len začína formovať, niektoré projekty v tejto oblasti sa už pomerne úspešne realizujú. Niektoré z nich sú úspešné v oblasti zberu údajov, ako napríklad projekty pre Federálnu daňovú službu a Tinkoff Credit Systems, iné v oblasti analýzy údajov a praktickej aplikácie jej výsledkov: ide o projekt Synqera.
Tinkoff Credit Systems Bank realizovala projekt implementácie platformy EMC2 Greenplum, ktorá je nástrojom pre masívne paralelné výpočty. V posledných rokoch banka zvýšila požiadavky na rýchlosť spracovania nahromadených informácií a analýzu dát v reálnom čase, čo je spôsobené vysokými mierami rastu počtu používateľov. kreditné karty. Banka oznámila plány na rozšírenie využívania technológií Big Data, najmä na spracovanie neštruktúrovaných dát a prácu s nimi firemné informácie získané z rôznych zdrojov.
Federálna daňová služba Ruska v súčasnosti vytvára analytickú vrstvu federálneho dátového skladu. Na jej základe jednotný informačný priestor a technológia prístupu k daňovým údajom na štatistické a analytické spracovanie. Počas realizácie projektu prebiehajú práce na centralizácii analytické informácie s viac ako 1200 zdrojmi miestnej úrovne IFTS.
Ďalší zaujímavý príklad analýzou veľkých dát v reálnom čase je ruský startup Synqera, ktorý vyvinul platformu Simplate. Riešenie je založené na spracovaní veľkých dátových polí, program analyzuje informácie o zákazníkoch, históriu ich nákupov, vek, pohlavie a dokonca aj náladu. Na pokladniach v sieti kozmetických predajní boli nainštalované dotykové obrazovky so senzormi, ktoré rozpoznávajú emócie zákazníkov. Program určuje náladu človeka, analyzuje informácie o ňom, určuje dennú dobu a skenuje databázu zliav v obchode, potom odošle kupujúcemu cielené správy o akciách a akciách. špeciálne ponuky. Toto riešenie zlepšuje lojalitu zákazníkov a zvyšuje predaj maloobchodníkov.
Ak hovoríme o zahraničných úspešných prípadoch, tak v tomto smere sú zaujímavé skúsenosti s využívaním Big Data technológií v Dunkin` Donuts, ktorá využíva dáta v reálnom čase na predaj produktov. Digitálne displeje v predajniach zobrazujú ponuky, ktoré sa menia každú minútu v závislosti od dennej doby a dostupnosti produktov. Podľa pokladničných dokladov spoločnosť dostáva údaje o tom, ktoré ponuky zaznamenali najväčšiu odozvu u kupujúcich. Tento prístup spracovania dát umožnil zvýšiť zisky a obrat tovaru v sklade.
Ako ukazujú skúsenosti s implementáciou Big Data projektov, táto oblasť je navrhnutá tak, aby úspešne riešila moderné obchodné problémy. Zároveň je dôležitým faktorom pri dosahovaní obchodných cieľov pri práci s veľkými dátami výber správnej stratégie, ktorá zahŕňa analytiku, ktorá identifikuje požiadavky spotrebiteľov, ako aj využitie inovatívne technológie v oblasti Big Data.
Podľa celosvetového prieskumu, ktorý každoročne od roku 2012 medzi obchodníkmi spoločností Econsultancy a Adobe uskutočňujú, „veľké dáta“, ktoré charakterizujú konanie ľudí na internete, dokážu veľa. Sú schopní optimalizovať offline obchodné procesy, pomôcť pochopiť, ako ich majitelia mobilných zariadení používajú na vyhľadávanie informácií, alebo jednoducho „vylepšiť marketing“, t.j. viac efektívny. Navyše, posledná funkcia je z roka na rok populárnejšia, ako vyplýva z nášho diagramu.
Hlavné oblasti práce internetových marketérov z hľadiska vzťahov so zákazníkmi

Zdroj: Econsultancy a Adobe, publikovanéemarketer.com
Všimnite si, že národnosť respondentov veľký význam nemá. Podľa prieskumu spoločnosti KPMG z roku 2013 je podiel „optimistov“, t.j. z tých, ktorí pri vývoji obchodnej stratégie využívajú veľké dáta, je 56 % a výkyvy medzi regiónmi sú malé: od 63 % v krajinách Severnej Ameriky po 50 % v regióne EMEA.
Používanie veľkých dát v rôznych regiónoch sveta

Zdroj: KPMG, publikovanéemarketer.com
Medzitým postoj obchodníkov k takýmto „módnym trendom“ trochu pripomína známu anekdotu:
Povedz, Vano, máš rád paradajky?
- Rád jem, ale nie.
Napriek tomu, že marketéri tvrdia, že „milujú“ veľké dáta a dokonca sa zdá, že ich aj používajú, v skutočnosti je „všetko komplikované“, ako píšu o svojich úprimných vzťahoch na sociálnych sieťach.
Podľa prieskumu, ktorý uskutočnila spoločnosť Circle Research v januári 2014 medzi európskymi marketérmi, 4 z 5 respondentov nepoužívajú Big Data (napriek tomu, že ich, samozrejme, „milujú“). Dôvody sú rôzne. Zarytých skeptikov je málo – 17 % a presne rovnaký počet ako ich protinožcov, t.j. tí, ktorí s istotou odpovedajú „Áno“. Zvyšok váha a pochybuje, „bažina“. Priamej odpovedi sa vyhýbajú pod hodnovernými výhovorkami typu „ešte nie, ale čoskoro“ alebo „počkáme, kým začnú ostatní“.
Používanie veľkých dát obchodníkmi, Európa, január 2014

Zdroj:dnx, uverejnený -emarketer.com
Čo ich mätie? Čistý nezmysel. Niektorí (presne polovica z nich) týmto údajom jednoducho neverí. Iní (takých je pomerne veľa – 55 %) len ťažko korelujú súbory „údajov“ a „používateľov“ medzi sebou. Niekto má jednoducho (povedzme to politicky korektne) vnútorný korporátny neporiadok: dáta bez vlastníka chodia medzi marketingovými oddeleniami a IT štruktúrami. Iným zase softvér nápor práce nezvládne. A tak ďalej. Keďže celkové podiely sú vysoko nad 100 %, je zrejmé, že situácia „viacnásobných prekážok“ nie je nezvyčajná.
Bariéry brániace využitiu Big Data v marketingu

Zdroj:dnx, uverejnený -emarketer.com
Musíme teda konštatovať, že zatiaľ sú „Big Data“ veľkým potenciálom, ktorý treba ešte využiť. Mimochodom, to môže byť dôvod, prečo Big Data strácajú svoje „módne trendy“ haló, o čom svedčia aj údaje z prieskumu spoločnosti Econsultancy, ktoré sme už spomínali.
Najvýznamnejšie trendy v digitálnom marketingu 2013-2014

Zdroj: Poradenstvo a Adobe
Nahrádza ich iný kráľ – content marketing. Ako dlho?
Nedá sa povedať, že veľké dáta sú nejakým zásadne novým fenoménom. Veľké zdroje údajov existujú už roky: databázy nákupov zákazníkov, úverová história, životný štýl. A už roky vedci využívajú tieto údaje, aby pomohli spoločnostiam posúdiť riziká a predpovedať budúce potreby zákazníkov. Dnes sa však situácia zmenila v dvoch aspektoch:
Objavili sa sofistikovanejšie nástroje a metódy na analýzu a kombinovanie rôznych súborov údajov;
Tieto analytické nástroje sú doplnené o lavínu nových dátových zdrojov poháňaných digitalizáciou prakticky každej metódy zberu dát a merania.
Rozsah dostupných informácií je pre výskumníkov, ktorí vyrastali v štruktúrovanom výskumnom prostredí, inšpirujúci aj zastrašujúci. Spotrebiteľský sentiment zachytávajú webové stránky a všetky druhy sociálnych médií. Skutočnosť prezerania reklám je zaznamenaná nielen set-top boxy, ale aj s digitálnymi značkami a mobilné zariadenia komunikácia s TV.
Údaje o správaní (napríklad počet hovorov, nákupné návyky a nákupy) sú teraz dostupné v reálnom čase. Veľa z toho, čo sa predtým dalo naučiť prostredníctvom výskumu, sa teraz dá naučiť prostredníctvom veľkých dátových zdrojov. A všetky tieto informačné aktíva sa neustále vytvárajú bez ohľadu na akékoľvek výskumné procesy. Tieto zmeny nás nútia premýšľať, či veľké dáta môžu nahradiť klasický prieskum trhu.
Nie je to o údajoch, ale o otázkach a odpovediach
Pred objednaním umieráčika na klasický výskum si musíme pripomenúť, že nie je rozhodujúca prítomnosť toho či onoho dátového aktíva, ale niečo iné. Čo presne? Naša schopnosť odpovedať na otázky, to je ono. Zábavné na novom svete veľkých dát je, že výsledky z nových dátových aktív vedú k ešte viac otázkam a tieto otázky zvyčajne najlepšie odpovie tradičný výskum. Ako teda veľké dáta rastú, vidíme paralelný nárast dostupnosti a dopytu po “malých dátach”, ktoré môžu poskytnúť odpovede na otázky zo sveta veľkých dát.
Zoberme si situáciu: veľký inzerent neustále monitoruje návštevnosť v obchodoch a objemy predaja v reálnom čase. Existujúce metodológie výskumu (v rámci ktorých sa účastníkov prieskumných panelov pýtame na ich nákupnú motiváciu a správanie v mieste predaja) nám pomáhajú lepšie zacieliť na konkrétne segmenty zákazníkov. Tieto metodológie môžu byť rozšírené tak, aby zahŕňali širšiu škálu veľkých dátových aktív až do bodu, kedy sa veľké dáta stávajú pasívnym nástrojom na pozorovanie a skúmajú metódu pokračujúceho, úzko zameraného skúmania zmien alebo udalostí, ktoré je potrebné študovať. Takto môžu veľké dáta oslobodiť výskum od zbytočnej rutiny. Primárny výskum by sa už nemal zameriavať na to, čo sa deje (veľké dáta budú). Namiesto toho sa primárny výskum môže zamerať na vysvetlenie, prečo vidíme určité trendy alebo odchýlky od trendov. Výskumník bude môcť menej myslieť na získavanie údajov a viac na to, ako ich analyzovať a použiť.
Zároveň vidíme, že veľké dáta riešia jeden z našich najväčších problémov, problém príliš dlhých štúdií. Skúmanie samotných štúdií ukázalo, že príliš nafúknuté výskumné nástroje majú negatívny vplyv na kvalitu dát. Hoci mnohí odborníci tento problém dlho uznávali, vždy odpovedali vetou: „Ale potrebujem tieto informácie pre vyšší manažment,“ a dlhé rozhovory pokračovali.
Vo svete veľkých dát, kde je možné kvantitatívne ukazovatele získať pasívnym pozorovaním, sa tento problém stáva diskutabilným. Opäť si spomeňme na celý tento výskum spotreby. Ak nám veľké dáta dávajú pohľady na spotrebu prostredníctvom pasívneho pozorovania, potom primárny výskum vo forme prieskumov už nemusí zbierať tento druh informácií a konečne môžeme podporiť našu víziu krátkych prieskumov nielen želaním dobrého, ale aj niečo skutočné.
Big Data potrebujú vašu pomoc
Napokon, „veľký“ je len jednou z charakteristík veľkých dát. Charakteristika "veľký" sa vzťahuje na veľkosť a rozsah údajov. Samozrejme, toto je hlavná charakteristika, keďže objem týchto údajov presahuje rámec všetkého, s čím sme doteraz pracovali. Dôležité sú však aj ďalšie charakteristiky týchto nových dátových tokov: často sú zle naformátované, neštruktúrované (alebo prinajlepšom čiastočne štruktúrované) a plné neistoty. Vznikajúca oblasť správy údajov s príznačným názvom „analytika entít“ má za cieľ vyriešiť problém prekonania šumu vo veľkých údajoch. Jeho úlohou je analyzovať tieto datasety a zistiť, koľko pozorovaní je pre tú istú osobu, ktoré pozorovania sú aktuálne a ktoré z nich sú použiteľné.
Tento druh čistenia dát je potrebný na odstránenie šumu alebo chybných dát pri práci s veľkými alebo malými dátovými aktívami, ale nestačí. Musíme tiež vytvoriť kontext okolo veľkých dátových aktív na základe našich predchádzajúcich skúseností, analýz a znalostí kategórií. V skutočnosti mnohí analytici poukazujú na schopnosť riadiť neistotu obsiahnutú vo veľkých dátach ako na zdroj konkurenčnej výhody, pretože umožňuje lepšie rozhodovanie.
A tu sa primárny výskum nielen oslobodzuje od rutiny vďaka veľkým dátam, ale prispieva aj k tvorbe a analýze obsahu v rámci veľkých dát.
Skvelým príkladom toho je aplikácia nášho úplne nového rámca hodnoty značky na sociálne médiá. (hovoríme o tej vyvinutej vMillward Hnedánový prístup k meraniu hodnoty značkyThe Zmysluplne Rôzne Rámec- "Paradigma významných rozdielov" -R & T ). Tento model je testovaný na konkrétnych trhoch, implementuje sa na štandardnom základe a možno ho jednoducho aplikovať na iné marketingové disciplíny a informačné systémy na podporu rozhodovania. Inými slovami, náš model hodnoty značky, založený na (aj keď nie výlučne) prieskumnom prieskume, má všetky vlastnosti potrebné na prekonanie neštruktúrovaného, nesúrodého a neistého charakteru veľkých dát.
Zvážte údaje o nálade spotrebiteľov poskytované sociálnymi médiami. Vo svojej surovej forme vrcholy a poklesy spotrebiteľského sentimentu veľmi často minimálne korelujú s offline meraniami hodnoty značky a správania: v údajoch je jednoducho príliš veľa šumu. Tento hluk však môžeme znížiť aplikáciou našich modelov spotrebiteľského významu, diferenciácie značky, dynamiky a identity na nespracované údaje o spotrebiteľskom sentimente, čo je spôsob spracovania a agregácie údajov sociálnych médií v týchto dimenziách.
Keď sú údaje usporiadané podľa nášho rámcového modelu, identifikované trendy sa zvyčajne zhodujú s meraniami hodnoty značky a správania získanými offline. Údaje zo sociálnych médií v skutočnosti nemôžu hovoriť samé za seba. Ich použitie na tento účel si vyžaduje naše skúsenosti a modely postavené na značkách. Keď nám sociálne médiá poskytujú jedinečné informácie vyjadrené v jazyku, ktorý spotrebitelia používajú na opis značiek, musíme tento jazyk použiť pri vytváraní nášho výskumu, aby bol primárny výskum oveľa efektívnejší.
Výhody vyňatých štúdií
To nás privádza späť k skutočnosti, že veľké dáta ani tak nenahrádzajú výskum, ako skôr ho uvoľňujú. Výskumníci budú odbremenení od nutnosti vytvárať novú štúdiu pre každý nový prípad. Neustále rastúce aktíva veľkých dát možno použiť na rôzne výskumné témy, čo umožňuje následnému primárnemu výskumu hlbšie sa ponoriť do témy a vyplniť medzery. Výskumníci sa nebudú musieť spoliehať na príliš nafúknuté prieskumy. Namiesto toho budú môcť využívať krátke prieskumy a zamerať sa na najdôležitejšie parametre, čo zvyšuje kvalitu dát.
Vďaka tejto verzii budú môcť výskumníci využiť svoje zavedené princípy a poznatky na pridanie presnosti a významu do veľkých dátových aktív, čo povedie k novým oblastiam prieskumu. Tento cyklus by mal viesť k hlbšiemu pochopeniu radu strategických otázok a v konečnom dôsledku k posunu smerom k tomu, čo by malo byť vždy naším hlavným cieľom – informovať a zlepšovať kvalitu rozhodnutí o značke a komunikácii.
Zvyčajne, keď hovoria o serióznom analytickom spracovaní, najmä ak používajú termín dolovanie údajov, znamenajú, že existuje obrovské množstvo údajov. Vo všeobecnom prípade to tak nie je, pretože pomerne často musíte spracovávať malé súbory údajov a nájsť v nich vzory nie je o nič jednoduchšie ako v stovkách miliónov záznamov. Hoci niet pochýb o tom, že potreba hľadania vzorov vo veľkých databázach komplikuje už aj tak netriviálnu úlohu analýzy.
Táto situácia je typická najmä pre podniky súvisiace s maloobchod, telekomunikácie, banky, internet. Ich databázy zhromažďujú obrovské množstvo informácií súvisiacich s transakciami: šeky, platby, hovory, protokoly atď.
Neexistujú žiadne univerzálne metódy analýzy alebo algoritmy vhodné pre akékoľvek prípady a akékoľvek množstvo informácií. Metódy analýzy údajov sa navzájom výrazne líšia z hľadiska výkonu, kvality výsledkov, jednoduchosti použitia a požiadaviek na údaje. Optimalizácia môže byť vykonaná na rôznych úrovniach: vybavenie, databázy, analytická platforma, počiatočná príprava dát, špecializované algoritmy. Analýza veľkého množstva údajov si vyžaduje špeciálny prístup, pretože je technicky náročné ich spracovať iba pomocou „ hrubou silou“, teda s použitím výkonnejších zariadení.
Samozrejme, môžete zvýšiť rýchlosť spracovania dát vďaka produktívnejšiemu vybaveniu, najmä preto, že moderné servery a pracovné stanice používajú viacjadrové procesory, RAM značná veľkosť a výkonné diskové polia. Existuje však mnoho iných spôsobov spracovania veľkého množstva údajov, ktoré vám umožňujú zvýšiť škálovateľnosť a nevyžadujú nekonečná aktualizácia zariadení.
schopnosti DBMS
Moderné databázy obsahujú rôzne mechanizmy, ktorých použitie výrazne zvýši rýchlosť analytického spracovania:
- Predbežný výpočet údajov. Informácie, ktoré sa najčastejšie používajú na analýzu, je možné vopred vypočítať (napríklad v noci) a uložiť vo forme pripravenej na spracovanie na databázovom serveri vo forme viacrozmerných kociek, materializovaných pohľadov, špeciálnych tabuliek.
- Ukladanie tabuľky do vyrovnávacej pamäte v RAM. Údaje, ktoré zaberajú málo miesta, ale ku ktorým sa často pristupuje počas analýzy, napríklad adresáre, je možné uložiť do pamäte RAM pomocou databázových nástrojov. Týmto spôsobom sa mnohonásobne znížia volania na pomalší diskový subsystém.
- Rozdelenie tabuliek na oddiely a tabuľkové priestory. Dáta, indexy, pomocné tabuľky môžete umiestniť na samostatné disky. To umožní DBMS čítať a zapisovať informácie na disky paralelne. Okrem toho je možné tabuľky rozdeliť do sekcií (partícií) tak, že pri prístupe k údajom je minimálny počet diskových operácií. Ak napríklad najčastejšie analyzujeme údaje za posledný mesiac, môžeme logicky použiť jednu tabuľku s historickými údajmi, ale fyzicky ju rozdeliť na niekoľko častí, takže pri prístupe k mesačným údajom sa načítava malá časť a neexistujú žiadne prístupy na všetky historické údaje.
Toto je len časť možností, ktoré moderné DBMS poskytujú. Rýchlosť extrahovania informácií z databázy môžete zvýšiť tuctom ďalších spôsobov: racionálne indexovanie, vytváranie plánov dotazov, paralelné spracovanie SQL dotazov, používanie klastrov, príprava analyzovaných údajov pomocou uložených procedúr a spúšťačov na strane databázového servera atď. Navyše, mnohé z týchto mechanizmov možno použiť nielen pomocou „ťažkých“ DBMS, ale aj voľných databáz.
Kombinácia modelov
Príležitosti na zvýšenie rýchlosti nie sú obmedzené na optimalizáciu databázy, veľa sa dá urobiť kombináciou rôznych modelov. Je známe, že rýchlosť spracovania výrazne súvisí so zložitosťou použitého matematického aparátu. Čím jednoduchšie sa používajú analytické mechanizmy, tým rýchlejšie sa údaje analyzujú.
Scenár spracovania údajov je možné zostaviť tak, že sa údaje „preženú“ cez sito modelov. Tu platí jednoduchá myšlienka: nestrácajte čas spracovaním toho, čo nemôžete analyzovať.
Najprv sa použijú najjednoduchšie algoritmy. Časť údajov, ktoré je možné spracovať pomocou takýchto algoritmov a ktoré nemá zmysel spracovávať pomocou viacerých komplexné metódy, je analyzovaný a vylúčený z ďalšieho spracovania. Zostávajúce údaje sa prenesú do ďalšej fázy spracovania, kde sa používajú zložitejšie algoritmy a tak ďalej v reťazci. V poslednom uzle scenára spracovania sa používajú najzložitejšie algoritmy, ale množstvo analyzovaných údajov je mnohonásobne menšie ako počiatočná vzorka. V dôsledku toho sa celkový čas potrebný na spracovanie všetkých údajov rádovo skráti.
Poďme priniesť praktický príklad pomocou tohto prístupu. Pri riešení problému predpovedania dopytu sa na začiatku odporúča vykonať analýzu XYZ, ktorá vám umožní určiť, ako stabilný je dopyt po rôznych tovaroch. Produkty skupiny X sa predávajú pomerne stabilne, takže použitie prognostických algoritmov vám umožňuje získať vysoko kvalitnú predpoveď. Produkty skupiny Y sa predávajú menej stabilne, možno pre nich stojí za to vytvárať modely nie pre každý článok, ale pre skupinu vám to umožňuje vyhladiť časové rady a zabezpečiť fungovanie prognostického algoritmu. Produkty skupiny Z sa predávajú náhodne, preto by ste pre ne nemali vôbec stavať prediktívne modely, ich potreba by sa mala vypočítať na základe jednoduchých vzorcov, napríklad priemerného mesačného predaja.
Podľa štatistík asi 70 % sortimentu tvorí tovar skupiny Z. Ďalších 25 % tvorí tovar skupiny Y a len asi 5 % tovar skupiny X. Konštrukcia a aplikácia zložitých modelov je teda relevantná pre maximálne 30% tovaru. Preto aplikácia vyššie opísaného prístupu skráti čas na analýzu a prognózovanie 5-10 krát.
Paralelné spracovanie
Ďalšou účinnou stratégiou na spracovanie veľkého množstva údajov je rozdelenie údajov do segmentov a zostavenie modelov pre každý segment samostatne s ďalším zlučovaním výsledkov. Vo veľkých objemoch údajov sa najčastejšie dá rozlíšiť niekoľko odlišných podmnožín. Môžu to byť napríklad skupiny zákazníkov, tovar, ktorý sa správa podobne a pre ktorý je vhodné postaviť jeden model.
V tomto prípade namiesto vytvárania jedného komplexného modelu pre všetkých môžete vytvoriť niekoľko jednoduchých modelov pre každý segment. Tento prístup zvyšuje rýchlosť analýzy a znižuje požiadavky na pamäť spracovaním menšieho množstva údajov v jednom prechode. Okrem toho je v tomto prípade možné paralelizovať analytické spracovanie, čo má tiež pozitívny vplyv na strávený čas. Okrem toho modely pre každý segment môžu zostavovať rôzni analytici.
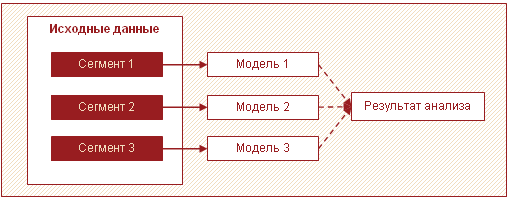
Okrem zvýšenia rýchlosti má tento prístup ešte jednu dôležitú výhodu – niekoľko relatívne jednoduchých modelov jednotlivo sa ľahšie vytvára a udržiava ako jeden veľký. Modely môžete spustiť po etapách, čím získate prvé výsledky v čo najkratšom čase.
Reprezentatívne vzorky
Za prítomnosti veľkého množstva údajov je možné na zostavenie modelu použiť nie všetky informácie, ale nejakú podmnožinu – reprezentatívnu vzorku. Správne pripravená reprezentatívna vzorka obsahuje informácie potrebné na zostavenie modelu kvality.
Proces analytického spracovania je rozdelený na 2 časti: vytvorenie modelu a aplikácia vytvoreného modelu na nové dáta. Vytvorenie komplexného modelu je proces náročný na zdroje. V závislosti od použitého algoritmu sa údaje ukladajú do vyrovnávacej pamäte, tisíckrát skenujú, počítajú sa mnohé pomocné parametre atď. Aplikácia už vytvoreného modelu na nové dáta si vyžaduje desiatky a stokrát menej zdrojov. Veľmi často ide o výpočet niekoľkých jednoduchých funkcií.
Ak je teda model postavený na relatívne malých súboroch a následne aplikovaný na celý súbor údajov, potom sa čas na získanie výsledku skráti rádovo v porovnaní s pokusom o úplné prepracovanie celého existujúceho súboru údajov.

Na získanie reprezentatívnych vzoriek existujú špeciálne metódy, napríklad odber vzoriek. Ich použitie vám umožňuje zvýšiť rýchlosť analytického spracovania bez obetovania kvality analýzy.
Zhrnutie
Opísané prístupy sú len malou časťou metód, ktoré umožňujú analyzovať obrovské množstvo údajov. Existujú aj iné spôsoby, napríklad použitie špeciálnych škálovateľných algoritmov, hierarchických modelov, učenie okien atď.
Analýza obrovské základne dáta sú netriviálnou úlohou, ktorá sa vo väčšine prípadov nedá vyriešiť „hlavou“, avšak moderné databázy a analytické platformy ponúkajú mnoho spôsobov riešenia tohto problému. Pri rozumnom používaní sú systémy schopné spracovať terabajty údajov primeranou rýchlosťou.
Stĺpec učiteľov HSE o mýtoch a prípadoch práce s veľkými dátami
Do záložiek
Lektori HSE School of New Media Konstantin Romanov a Alexander Pyatigorsky, ktorý je zároveň riaditeľom digitálnej transformácie v Beeline, napísali pre stránku stĺpček o hlavných mylných predstavách o veľkých dátach – príkladoch využitia technológií a nástrojov. Autori naznačujú, že publikácia pomôže lídrom spoločností pochopiť tento koncept.
Mýty a mylné predstavy o veľkých dátach
Big Data nie sú marketing
Výraz Big Data sa stal veľmi módnym – používa sa v miliónoch situácií a v stovkách rôznych interpretácií, často nesúvisiacich s tým, o čo ide. V mysliach ľudí často dochádza k zámene pojmov a veľké dáta sa zamieňajú s marketingovým produktom. Navyše v niektorých spoločnostiach sú Big Data súčasťou marketingovej divízie. Výsledok analýzy veľkých dát môže byť skutočne zdrojom marketingových aktivít, ale nič viac. Pozrime sa, ako to funguje.
Ak sme pred dvoma mesiacmi identifikovali zoznam tých, ktorí si v našom obchode kúpili tovar v hodnote viac ako tri tisíc rubľov, a potom sme týmto používateľom poslali nejakú ponuku, ide o typický marketing. Zo štrukturálnych údajov odvodzujeme jasný vzor a používame ho na zvýšenie predaja.
Ak však skombinujeme dáta CRM so streamovanými informáciami, napríklad z Instagramu, a analyzujeme ich, nájdeme vzorec: človek, ktorý v stredu večer obmedzil aktivitu a na poslednej fotke sú mačiatka, by mal dať určitú ponuku. Už to budú Big Data. Našli sme spúšť, dali ju obchodníkom a oni ju použili na svoje účely.
Z toho vyplýva, že technológia väčšinou pracuje s neštruktúrovanými dátami a ak sú dáta štruktúrované, systém v nich stále hľadá skryté vzorce, čo marketing nerobí.
Big Data nie sú IT
Druhý extrém tohto príbehu: Big Data sa často zamieňajú s IT. Je to spôsobené tým, že v Ruské spoločnosti Spravidla sú to IT špecialisti, ktorí sú ťahúňmi všetkých technológií, vrátane veľkých dát. Ak sa teda všetko deje v tomto oddelení, pre spoločnosť ako celok sa zdá, že ide o nejakú IT činnosť.
V skutočnosti je tu zásadný rozdiel: Big Data je činnosť zameraná na získanie určitého produktu, ktorá sa vôbec netýka IT, hoci technológia bez nich nemôže existovať.
Veľké dáta nie sú vždy zhromažďovaním a analýzou informácií
Existuje ďalšia mylná predstava o veľkých údajoch. Každý chápe, že táto technológia je spojená s veľkým množstvom údajov, ale nie je vždy jasné, o aký druh údajov ide. Každý môže zbierať a využívať informácie, teraz je to možné nielen vo filmoch o, ale aj v každej, aj veľmi malej firme. Jedinou otázkou je, čo presne zbierať a ako to využiť vo svoj prospech.
Malo by sa však pochopiť, že technológia veľkých údajov nebude zhromažďovať a analyzovať absolútne žiadne informácie. Ak napríklad zbierate údaje o konkrétnej osobe na sociálnych sieťach, nepôjde o Big Data.
Čo sú to vlastne veľké dáta
Veľké dáta pozostávajú z troch prvkov:
- údaje;
- analytika;
- technológie.
Big Data nie sú len jednou z týchto zložiek, ale kombináciou všetkých troch prvkov. Ľudia často nahrádzajú pojmy: niekto si myslí, že veľké dáta sú iba dáta, niekto si myslí, že je to technológia. Ale v skutočnosti, bez ohľadu na to, koľko údajov nazbierate, bez nich s nimi nič neurobíte potrebné technológie a analytika. Ak existuje dobrá analytika, ale žiadne údaje, o to horšie.
Ak hovoríme o údajoch, nejde len o texty, ale aj o všetky fotografie zverejnené na Instagrame a vo všeobecnosti o všetko, čo je možné analyzovať a použiť na rôzne účely a úlohy. Inými slovami, údaje sa týkajú obrovského množstva interných a externých údajov rôznych štruktúr.
Analytika je tiež potrebná, pretože úlohou Big Data je vytvoriť nejaké vzory. To znamená, že analytika je identifikácia skrytých závislostí a hľadanie nových otázok a odpovedí na základe analýzy celého objemu heterogénnych údajov. Navyše, Big Data vyvolávajú otázky, ktoré nie sú priamo odvodené z týchto údajov.
Čo sa týka obrázkov, fakt, že ste zverejnili svoju fotku v modrom tričku, nič nehovorí. Ak však použijete fotografiu na modelovanie veľkých dát, môže sa ukázať, že práve teraz by ste mali ponúknuť pôžičku, pretože vo vašej sociálnej skupine toto správanie naznačuje určitý jav v akciách. Preto „holé“ údaje bez analýzy, bez odhaľovania skrytých a nie očividných závislostí, nie sú veľkými údajmi.
Takže máme veľké dáta. Ich počet je obrovský. Máme aj analytika. Ako však môžeme zabezpečiť, aby sa z týchto nespracovaných údajov zrodilo konkrétne riešenie? Na to potrebujeme technológie, ktoré nám ich umožnia nielen ukladať (a to predtým nebolo možné), ale aj analyzovať.
Jednoducho povedané, ak máte veľa údajov, budete potrebovať technológie ako Hadoop, ktoré umožňujú uložiť všetky informácie v ich pôvodnej podobe pre neskoršiu analýzu. Takéto technológie vznikli v internetových gigantoch, pretože ako prví čelili problému ukladania veľkého množstva údajov a ich analýzy na následné speňaženie.
Okrem nástrojov na optimalizované a lacné ukladanie dát sú potrebné analytické nástroje, ako aj doplnky k používanej platforme. Napríklad okolo Hadoopu sa už vytvoril celý ekosystém súvisiacich projektov a technológií. Tu sú niektoré z nich:
- Pig je deklaratívny jazyk analýzy údajov.
- Hive - analýza dát pomocou jazyka blízkeho SQL.
- Oozie je pracovný postup v Hadoop.
- Hbase - databáza (nerelačná), analóg Google Big Table.
- Mahout – strojové učenie.
- Sqoop - prenos dát z RSDDB do Hadoop a naopak.
- Žľab - prenos guľatiny do HDFS.
- Zookeeper, MRUnit, Avro, Giraph, Ambari, Cassandra, HCatalog, Fuse-DFS a tak ďalej.
Všetky tieto nástroje sú dostupné pre každého zadarmo, no existuje aj sada platených doplnkov.
Okrem toho sú potrební špecialisti: ide o vývojára a analytika (tzv. Data Scientist). Potrebujete tiež manažéra, ktorý je schopný pochopiť, ako aplikovať túto analytiku na konkrétnu úlohu, pretože sama o sebe je úplne nezmyselná, ak nie je zabudovaná do obchodných procesov.
Všetci traja zamestnanci musia pracovať ako tím. Manažér, ktorý dáva Data Scientistovi za úlohu nájsť určitý vzor, musí pochopiť, že nie vždy je možné nájsť presne to, čo potrebuje. V tomto prípade by mal manažér pozorne počúvať, čo Data Scientist zistil, pretože jeho zistenia sa často ukážu ako zaujímavejšie a užitočnejšie pre podnikanie. Vašou úlohou je aplikovať ho na podnikanie a vyrobiť z neho produkt.
Napriek tomu, že v súčasnosti existuje veľa rôznych druhov strojov a technológií, konečné rozhodnutie zostáva vždy na človeku. Na to je potrebné informácie nejako vizualizovať. Existuje na to pomerne veľa nástrojov.
Najilustratívnejším príkladom sú geoanalytické správy. Spoločnosť Beeline veľa spolupracuje s vládami rôznych miest a regiónov. Veľmi často si tieto organizácie objednávajú prehľady ako „Zaťaženie premávky na konkrétnom mieste“.
Je jasné, že takáto správa by sa mala dostať k vládnym orgánom v jednoduchej a zrozumiteľnej forme. Ak im poskytneme obrovskú a úplne nezrozumiteľnú tabuľku (teda informácie v takej forme, v akej ich dostávame), je nepravdepodobné, že by si takúto správu kúpili – bude úplne zbytočná, nedostanú z nej vedomosti ktoré chceli dostať.
Preto bez ohľadu na to, akí dobrí dátoví vedci sú a bez ohľadu na to, aké vzory nájdu, s týmito dátami nebudete môcť pracovať bez kvalitných vizualizačných nástrojov.
Zdroje dát
Pole prijatých údajov je veľmi veľké, takže sa dá rozdeliť do niekoľkých skupín.
Interné údaje spoločnosti
Hoci 80 % zozbieraných údajov patrí do tejto skupiny, nie vždy sa tento zdroj využíva. Často sú to údaje, ktoré, ako sa zdá, nikto vôbec nepotrebuje, napríklad protokoly. No ak sa na ne pozriete z iného uhla pohľadu, niekedy v nich môžete nájsť nečakané vzory.
Shareware zdroje
To zahŕňa údaje sociálne siete, internet a všetko, kam sa dá dostať zadarmo. Prečo shareware? Na jednej strane sú tieto dáta dostupné každému, no ak ste veľká firma, tak získať ich vo veľkosti predplatiteľskej základne desaťtisíc, stovky či milióny zákazníkov už nie je jednoduchá záležitosť. Preto má trh platených služieb poskytnúť tieto údaje.
Platené zdroje
Patria sem spoločnosti, ktoré predávajú dáta za peniaze. Môžu to byť telekomunikácie, DMP, internetové spoločnosti, úverové kancelárie a agregátory. V Rusku telekomunikácie nepredávajú dáta. Po prvé je to ekonomicky nerentabilné a po druhé je to zákonom zakázané. Preto predávajú výsledky svojho spracovania, napríklad geoanalytické správy.
otvorené dáta
Štát vychádza v ústrety biznisu a umožňuje využívať údaje, ktoré zbierajú. Vo väčšej miere je to rozvinuté na Západe, ale aj Rusko v tomto smere drží krok s dobou. Napríklad existuje portál otvorených údajov vlády Moskvy, ktorý zverejňuje informácie o rôznych objektoch mestskej infraštruktúry.
Pre obyvateľov a hostí Moskvy sú údaje prezentované v tabuľkovej a kartografickej forme a pre vývojárov - v špeciálnych strojovo čitateľných formátoch. Projekt síce funguje v obmedzenom režime, ale vyvíja sa, čo znamená, že je aj zdrojom dát, ktoré môžete využiť pre svoje obchodné úlohy.
Výskum
Ako už bolo uvedené, úlohou Big Data je nájsť vzor. Štúdie po celom svete sa často môžu stať referenčným bodom pre nájdenie konkrétneho vzoru - môžete získať konkrétny výsledok a pokúsiť sa použiť podobnú logiku na svoje ciele.
Big Data sú oblasťou, v ktorej nefungujú všetky matematické zákony. Napríklad "1" + "1" nie je "2", ale oveľa viac, pretože pri zmiešaní zdrojov údajov sa môže účinok výrazne zvýšiť.
Príklady produktov
Mnoho ľudí pozná službu výberu hudby Spotify. Krása je v tom, že sa nepýta používateľov, akú majú dnes náladu, ale namiesto toho ju vypočítava na základe zdrojov, ktoré má k dispozícii. Vždy vie, čo teraz potrebujete – jazz alebo hard rock. Toto je kľúčový rozdiel, ktorý mu poskytuje fanúšikov a odlišuje ho od iných služieb.

Takéto produkty sa zvyčajne nazývajú sense-produkty - tie, ktoré cítia svojho klienta.
Technológia Big Data sa využíva aj v automobilovom priemysle. Toto robí napríklad Tesla – v ich najnovší model je tam autopilot. Spoločnosť sa snaží vytvoriť auto, ktoré odvezie pasažiera tam, kam potrebuje. Bez veľkých dát je to nemožné, pretože ak použijeme iba údaje, ktoré dostaneme priamo, ako to robí človek, potom sa auto nebude môcť zlepšiť.

Keď sami riadime auto, používame naše neuróny na rozhodovanie na základe mnohých faktorov, ktoré si ani nevšimneme. Napríklad si možno neuvedomujeme, prečo sme sa rozhodli nezapnúť hneď zelenú, a potom sa ukáže, že rozhodnutie bolo správne – auto okolo vás prefrčalo závratnou rýchlosťou a vy ste sa vyhli nehode.
Môžete uviesť aj príklad využitia Big Data v športe. V roku 2002 sa generálny manažér bejzbalového tímu Oakland Athletics Billy Bean rozhodol prelomiť paradigmu, ako hľadať športovcov – hráčov vyberal a trénoval „do počtu“.
Manažéri sa zvyčajne pozerajú na úspech hráčov, ale v tomto prípade to bolo inak - aby získal výsledok, manažér študoval, aké kombinácie športovcov potreboval, pričom venoval pozornosť individuálnym charakteristikám. Navyše si vybral športovcov, ktorí sami o sebe nepredstavovali veľký potenciál, ale tím ako celok sa ukázal byť natoľko úspešný, že vyhral dvadsať zápasov v rade.

Režisér Bennett Miller následne natočil film venovaný tomuto príbehu – „Muž, ktorý zmenil všetko“ s Bradom Pittom v hlavnej úlohe.
Technológia Big Data je užitočná aj vo finančnom sektore. Ani jeden človek na svete nedokáže samostatne a presne určiť, či sa oplatí dať niekomu pôžičku. Na rozhodnutie sa vykonáva bodovanie, to znamená, že sa zostavuje pravdepodobnostný model, pomocou ktorého možno pochopiť, či táto osoba vráti peniaze alebo nie. Ďalej sa bodovanie používa vo všetkých fázach: môžete napríklad vypočítať, že v určitom okamihu osoba prestane platiť.
Veľké dáta umožňujú nielen zarábať, ale aj šetriť. Najmä táto technológia pomohla nemeckému ministerstvu práce znížiť náklady na dávky v nezamestnanosti o 10 miliárd eur, keďže po analýze informácií vyšlo najavo, že 20 % dávok bolo vyplatených nezaslúžene.
Technológie sa využívajú aj v medicíne (platí to najmä pre Izrael). Pomocou Big Data môžete urobiť oveľa presnejšiu analýzu, ako dokáže urobiť lekár s tridsaťročnou praxou.
Každý lekár sa pri stanovení diagnózy spolieha iba na svoje vlastné skúsenosti. Keď to robí stroj, vychádza to zo skúseností tisícok takýchto lekárov a všetkých existujúcich anamnéz. Berie do úvahy, z akého materiálu je vyrobený dom pacienta, v akej oblasti obeť žije, aký je tam dym atď. To znamená, že zohľadňuje veľa faktorov, ktoré lekári neberú do úvahy.
Príkladom využitia Big Data v zdravotníctve je projekt Project Artemis, ktorý realizovala Detská nemocnica v Toronte. to Informačný systém, ktorá zhromažďuje a analyzuje údaje o bábätkách v reálnom čase. Prístroj umožňuje každú sekundu analyzovať 1260 zdravotných indikátorov každého dieťaťa. Tento projekt je zameraný na predpovedanie nestabilného stavu dieťaťa a prevenciu chorôb u detí.
Big data sa začínajú používať aj v Rusku: napríklad Yandex má divíziu veľkých dát. Spoločnosť spolu s AstraZeneca a Ruskou spoločnosťou klinickej onkológie RUSSCO spustila platformu RAY pre genetikov a molekulárnych biológov. Projekt zlepšuje metódy diagnostiky rakoviny a identifikácie predispozície k rakovine. Platforma bude spustená v decembri 2016.
Pojem Big Data sa zvyčajne vzťahuje na akékoľvek množstvo štruktúrovaných, pološtruktúrovaných a neštruktúrovaných údajov. Druhý a tretí však môžu a mali by byť objednané na následnú analýzu informácií. Veľké dáta sa nerovnajú žiadnemu skutočnému objemu, ale keď hovoríme o veľkých dátach, vo väčšine prípadov máme na mysli terabajty, petabajty a dokonca extrabajty informácií. Toto množstvo údajov sa môže časom nahromadiť v akomkoľvek podniku alebo v prípadoch, keď spoločnosť potrebuje získať veľa informácií, v reálnom čase.
Analýza veľkých dát
Keď hovoríme o analýze veľkých dát, v prvom rade máme na mysli zhromažďovanie a uchovávanie informácií z rôznych zdrojov. Napríklad údaje o zákazníkoch, ktorí nakupovali, ich vlastnosti, informácie o spustení reklamné spoločnosti a hodnotenie jeho efektívnosti, dáta kontaktné centrum. Áno, všetky tieto informácie je možné porovnávať a analyzovať. Je to možné a potrebné. Na to však musíte nastaviť systém, ktorý vám umožní zhromažďovať a transformovať informácie bez skreslenia informácií, ukladať ich a nakoniec ich vizualizovať. Súhlasíte, s veľkými údajmi tabuľky vytlačené na niekoľko tisíc strán pri obchodných rozhodnutiach veľmi nepomôžu.
1. Príchod veľkých dát
Väčšina služieb, ktoré zhromažďujú informácie o akciách používateľov, má možnosť exportovať. Na to, aby vstúpili do spoločnosti v štruktúrovanej forme, sa používajú rôzne, napríklad Alteryx. Tento softvér vám umožňuje prijímať automatický režim informácie, spracovať, ale hlavne pretaviť do požadovaný pohľad a formátovať bez skreslenia.
2. Ukladanie a spracovanie veľkých dát
Takmer vždy pri zhromažďovaní veľkého množstva informácií vzniká problém s ich ukladaním. Zo všetkých platforiem, ktoré sme študovali, naša spoločnosť uprednostňuje Verticu. Na rozdiel od iných produktov je Vertica schopná rýchlo „dať“ informácie v nej uložené. Medzi nevýhody patrí dlhé nahrávanie, no pri analýze veľkých dát vystupuje do popredia rýchlosť návratu. Napríklad, ak hovoríme o kompilácii pomocou petabajtu informácií, rýchlosť nahrávania je jednou z najdôležitejších charakteristík.
3. Vizualizácia veľkých dát
A napokon treťou fázou analýzy veľkého množstva údajov je . To si vyžaduje platformu, ktorá je schopná vizuálne odrážať všetky prijaté informácie vo vhodnej forme. Podľa nášho názoru sa s touto úlohou dokáže vyrovnať iba jeden softvérový produkt, Tableau. Jednoznačne jeden z najlepších na dnes riešenie, ktoré dokáže vizuálne zobraziť akékoľvek informácie, premieňa prácu spoločnosti na trojrozmerný model, zbiera akcie všetkých oddelení do jedného vzájomne závislého reťazca (viac o schopnostiach Tableau si môžete prečítať).
Namiesto zhrnutia si všimneme, že takmer každá spoločnosť môže teraz generovať svoje vlastné veľké údaje. Analýza veľkých dát už nie je zložitý a nákladný proces. Vedenie spoločnosti je teraz povinné správne formulovať otázky zhromaždené informácie, pričom prakticky neexistujú žiadne neviditeľné sivé oblasti.
Stiahnite si Tableau