تجزیه و تحلیل حجم زیادی از داده ها. ماشین برای داده های بزرگ مقیاس بندی و طبقه بندی
طبق تحقیقات و روندها
داده های بزرگ، "داده های بزرگ" چند سالی است که در مطبوعات IT و بازاریابی به بحث شهر تبدیل شده است. و واضح است: فناوری های دیجیتال در زندگی نفوذ کرده است انسان مدرن، "همه چیز نوشته شده است." حجم داده ها در مورد جنبه های مختلف زندگی در حال افزایش است و در عین حال امکان ذخیره سازی اطلاعات نیز رو به افزایش است.
فناوری های جهانی برای ذخیره سازی اطلاعات
منبع: هیلبرت و لوپز، «ظرفیت تکنولوژیکی جهان برای ذخیره، برقراری ارتباط و محاسبه اطلاعات»، Science، 2011 جهانی.
اکثر کارشناسان موافق هستند که تسریع رشد داده ها یک واقعیت عینی است. شبکههای اجتماعی، دستگاههای تلفن همراه، دادههای دستگاههای اندازهگیری، اطلاعات تجاری تنها چند نوع منبع هستند که میتوانند حجم عظیمی از اطلاعات را تولید کنند. طبق تحقیقات IDCجهان دیجیتال، منتشر شده در سال 2012، 8 سال آینده میزان داده ها در جهان به 40 Zb (زتابایت) می رسد که معادل 5200 گیگابایت برای هر ساکن کره زمین است.
رشد اطلاعات دیجیتال جمع آوری شده در ایالات متحده آمریکا

منبع: IDC
بخش قابل توجهی از اطلاعات توسط افراد ایجاد نمیشود، بلکه توسط روباتهایی که هم با یکدیگر و هم با سایر شبکههای داده تعامل دارند، مانند حسگرها و دستگاه های هوشمند. به گفته محققان با این سرعت رشد، میزان داده ها در جهان هر سال دو برابر می شود. تعداد مجازی و سرورهای فیزیکیدر جهان به دلیل گسترش و ایجاد مراکز داده جدید ده برابر رشد خواهد کرد. در این راستا نیاز روزافزونی به استفاده موثر و کسب درآمد از این داده ها احساس می شود. از آنجایی که استفاده از داده های بزرگ در کسب و کار نیاز به سرمایه گذاری قابل توجهی دارد، درک واضح وضعیت ضروری است. و در اصل ساده است: شما می توانید کارایی کسب و کار را با کاهش هزینه ها و/یا افزایش فروش افزایش دهید.
Big Data برای چیست؟
پارادایم کلان داده سه نوع اصلی کار را تعریف می کند.
- ذخیره و مدیریت صدها ترابایت یا پتابایت داده که پایگاه های داده رابطه ای معمولی نمی توانند به طور موثر از آنها استفاده کنند.
- سازماندهی اطلاعات بدون ساختار متشکل از متون، تصاویر، ویدئوها و انواع دیگر داده ها.
- تجزیه و تحلیل کلان داده، که این سوال را مطرح می کند که چگونه با اطلاعات بدون ساختار، تولید گزارش های تحلیلی و پیاده سازی مدل های پیش بینی کار کنیم.
بازار پروژه داده های بزرگ با بازار هوش تجاری (BA) تلاقی می کند که حجم آن در جهان به گفته کارشناسان در سال 2012 حدود 100 میلیارد دلار بوده است. این شامل اجزای فناوری شبکه، سرورها، نرم افزارو خدمات فنی
همچنین، استفاده از فناوریهای کلان داده برای راهحلهای کلاس تضمین درآمد (RA) که برای خودکارسازی فعالیتهای شرکتها طراحی شدهاند، مرتبط است. سیستم های مدرن تضمین درآمد شامل ابزارهایی برای تشخیص ناسازگاری ها و تجزیه و تحلیل عمیق داده ها است که به شما امکان می دهد به موقع زیان های احتمالی یا تحریف اطلاعات را شناسایی کنید که می تواند منجر به کاهش نتایج مالی شود. در این زمینه، شرکتهای روسی با تایید تقاضا برای فناوریهای Big Data در بازار داخلی، خاطرنشان میکنند که عواملی که توسعه دادههای بزرگ در روسیه را تحریک میکنند، رشد دادهها، تسریع در تصمیمگیری مدیریتی و بهبود عملکرد آنها است. کیفیت
چه چیزی مانع از کار با داده های بزرگ می شود
امروزه تنها 0.5 درصد از داده های دیجیتالی انباشته شده تجزیه و تحلیل می شود، علیرغم این واقعیت که به طور عینی وظایفی در سطح صنعت وجود دارد که می توان با کمک آن ها را حل کرد. راه حل های تحلیلیکلاس داده های بزرگ بازارهای توسعه یافته فناوری اطلاعات در حال حاضر نتایجی دارند که می توان از آنها برای ارزیابی انتظارات مرتبط با انباشت و پردازش کلان داده ها استفاده کرد.
یکی از اصلی ترین عواملی که اجرای پروژه های Big Data را کند می کند، علاوه بر هزینه بالا، می باشد مشکل انتخاب داده هایی که باید پردازش شوند: یعنی تعریف اینکه چه داده هایی باید استخراج، ذخیره و تجزیه و تحلیل شوند و چه داده هایی نباید مورد توجه قرار گیرند.
بسیاری از نمایندگان کسب و کار خاطرنشان می کنند که مشکلات در اجرای پروژه های کلان داده با کمبود متخصص - بازاریابان و تحلیلگران همراه است. نرخ بازگشت سرمایه در Big Data به طور مستقیم به کیفیت کار کارکنان درگیر در تجزیه و تحلیل عمیق و پیش بینی کننده بستگی دارد. پتانسیل عظیم داده هایی که در حال حاضر در یک سازمان وجود دارد، اغلب به دلیل فرآیندهای تجاری قدیمی یا مقررات داخلی، نمی توانند به طور موثر توسط خود بازاریابان استفاده شوند. بنابراین، پروژههای کلان داده اغلب توسط کسبوکارها نه تنها در اجرا، بلکه در ارزیابی نتایج نیز دشوار تلقی میشوند: ارزش دادههای جمعآوریشده. ویژگی های کار با داده ها به بازاریابان و تحلیلگران نیاز دارد که توجه خود را از فناوری و گزارش دهی به حل مشکلات خاص تجاری معطوف کنند.
به دلیل حجم زیاد و سرعت بالاجریان داده ها، فرآیند جمع آوری آنها شامل رویه های ETL بلادرنگ است. برای مرجع:ETL - از جانبانگلیسیاستخراج کردن, تبدیل, بار- به معنای واقعی کلمه "استخراج، تبدیل، بارگذاری") - یکی از فرآیندهای اصلی در مدیریت انبارهای داده که شامل: استخراج داده از منابع خارجی، تبدیل آنها و نظافت برای رفع نیازها ETL نه تنها باید به عنوان فرآیندی برای انتقال داده ها از یک برنامه کاربردی به برنامه دیگر، بلکه به عنوان ابزاری برای آماده سازی داده ها برای تجزیه و تحلیل در نظر گرفته شود.
و سپس مسائل مربوط به اطمینان از امنیت داده های دریافتی از منابع خارجی باید راه حل هایی داشته باشد که با حجم اطلاعات جمع آوری شده مطابقت داشته باشد. از آنجایی که روشهای تحلیل کلان دادهها تاکنون تنها پس از رشد حجم دادهها در حال توسعه هستند، توانایی پلتفرمهای تحلیلی در استفاده از روشهای جدید تهیه و تجمیع دادهها نقش مهمی دارد. این نشان می دهد که برای مثال، داده های مربوط به خریداران بالقوه یا یک انبار داده عظیم با سابقه کلیک در سایت های فروشگاه آنلاین می تواند برای حل مشکلات مختلف جالب باشد.
سختی ها متوقف نمی شوند
علیرغم تمام مشکلاتی که در پیاده سازی Big Data وجود دارد، این کسب و کار قصد دارد سرمایه گذاری در این زمینه را افزایش دهد. بر اساس دادههای گارتنر، در سال 2013، 64 درصد از بزرگترین شرکتهای جهان قبلاً روی استقرار فناوریهای Big Data برای تجارت خود سرمایهگذاری کردهاند یا برنامههایی برای سرمایهگذاری دارند، در حالی که در سال 2012، 58 درصد از این شرکتها وجود داشت. طبق یک مطالعه گارتنر، رهبران صنایع سرمایهگذاری بر روی دادههای بزرگ، شرکتهای رسانهای، مخابرات، بخش بانکی و شرکتهای خدماتی هستند. نتایج موفقیتآمیز اجرای Big Data در حال حاضر توسط بسیاری از بازیگران اصلی صنعت خردهفروشی از نظر استفاده از دادههای بهدستآمده با استفاده از ابزارهای RFID، لجستیک و سیستمهای جابجایی (از انگلیسی) به دست آمده است. دوباره پر کردن- انباشت، دوباره پر کردن - تحقیق و توسعه)، و همچنین از برنامه های وفاداری. تجربه موفق خرده فروشی سایر بخش های بازار را برای یافتن بخش های جدید تحریک می کند. راه های موثرکسب درآمد از کلان داده ها برای تبدیل تجزیه و تحلیل آنها به منبعی که برای توسعه تجارت کار می کند. به همین دلیل، به گفته کارشناسان، تا سال 2020، سرمایه گذاری در مدیریت و ذخیره سازی برای هر گیگابایت داده از 2 دلار به 0.2 دلار کاهش می یابد، اما برای مطالعه و تجزیه و تحلیل ویژگی های فناوری داده های بزرگ تنها 40 رشد خواهد داشت. ٪.
هزینه های ارائه شده در پروژه های مختلف سرمایه گذاری در حوزه داده های بزرگ ماهیت متفاوتی دارند. اقلام هزینه بستگی به انواع محصولاتی دارد که بر اساس تصمیمات خاصی انتخاب می شوند. به گفته کارشناسان، بیشترین بخش از هزینه ها در پروژه های سرمایه گذاری به محصولات مربوط به جمع آوری، ساختار داده ها، تمیز کردن و مدیریت اطلاعات اختصاص دارد.
چگونه انجام می شود
ترکیبات زیادی از نرم افزار و سخت افزارکه به شما امکان ایجاد می دهد راه حل های موثرکلان داده برای رشته های مختلف کسب و کار: از رسانه های اجتماعی و برنامه های موبایل، قبل از تحلیل فکریو تجسم داده های تجاری یک مزیت مهم Big Data سازگاری ابزارهای جدید با پایگاه های داده است که به طور گسترده در تجارت مورد استفاده قرار می گیرد، که به ویژه هنگام کار با پروژه های بین رشته ای، مانند سازماندهی فروش چند کاناله و پشتیبانی از مشتری، اهمیت دارد.
توالی کار با داده های بزرگ شامل جمع آوری داده ها، ساختاردهی اطلاعات دریافتی با استفاده از گزارش ها و داشبورد (داشبورد)، ایجاد بینش و زمینه ها و تدوین توصیه هایی برای اقدام است. از آنجایی که کار با Big Data مستلزم هزینه های بالایی برای جمع آوری داده ها است که نتیجه پردازش آن از قبل مشخص نیست، وظیفه اصلی این است که به وضوح درک کنید که داده ها برای چه چیزی هستند و نه اینکه چه مقدار از آن در دسترس است. در این حالت، جمع آوری داده ها به فرآیندی برای به دست آوردن اطلاعات تبدیل می شود که برای حل مسائل خاص بسیار ضروری است.
به عنوان مثال، ارائه دهندگان مخابرات حجم عظیمی از داده ها، از جمله موقعیت جغرافیایی را که به طور مداوم به روز می شود، جمع آوری می کنند. این اطلاعات ممکن است برای آژانس های تبلیغاتی مورد توجه تجاری قرار گیرد، که ممکن است از آن برای ارائه تبلیغات هدفمند و محلی و همچنین خرده فروشان و بانک ها استفاده کنند. چنین دادههایی میتوانند نقش مهمی در تصمیمگیری برای باز کردن یک فروشگاه خردهفروشی در یک مکان خاص بر اساس دادههای حضور یک جریان هدفمند قدرتمند از مردم ایفا کنند. نمونه ای از اندازه گیری اثربخشی تبلیغات در بیلبوردهای فضای باز در لندن وجود دارد. اکنون پوشش چنین تبلیغاتی تنها با قرار دادن افراد در نزدیکی سازه های تبلیغاتی با دستگاه مخصوصی که رهگذران را شمارش می کند قابل سنجش است. در مقایسه با این نوع سنجش اثربخشی تبلیغات، اپراتور تلفن همراهفرصت های بسیار بیشتر - او دقیقاً مکان مشترکین خود را می داند، ویژگی های جمعیتی، جنسیت، سن، وضعیت تاهل و غیره را می داند.
بر اساس چنین داده هایی، در آینده، چشم انداز تغییر محتوای پیام تبلیغاتی با استفاده از ترجیحات شخصی خاص که از کنار بیلبورد عبور می کند، باز می شود. اگر داده ها نشان می دهد که شخصی که از آنجا می گذرد زیاد سفر می کند، می توان تبلیغی برای استراحتگاه به او نشان داد. برگزارکنندگان یک مسابقه فوتبال فقط می توانند تعداد هواداران را زمانی که به مسابقه می آیند تخمین بزنند. اما اگر فرصت داشتند از اپراتور بپرسند ارتباط سلولیاطلاعات در مورد محل حضور بازدیدکنندگان یک ساعت، یک روز یا یک ماه قبل از مسابقه، این به برگزارکنندگان این فرصت را میدهد تا مکانهایی را برای تبلیغ مسابقات بعدی برنامهریزی کنند.
مثال دیگر این است که چگونه بانک ها می توانند از داده های بزرگ برای جلوگیری از کلاهبرداری استفاده کنند. اگر مشتری مفقود شدن کارت را گزارش دهد و هنگام خرید با استفاده از آن، بانک به صورت لحظه ای موقعیت تلفن مشتری را در منطقه خریدی که تراکنش انجام می شود مشاهده کند، بانک می تواند اطلاعات صورت حساب مشتری را بررسی کند. آیا سعی کرده او را فریب دهد. یا برعکس، وقتی مشتری در فروشگاهی خرید می کند، بانک می بیند کارتی که تراکنش روی آن انجام می شود و تلفن مشتری در یک مکان است، بانک می تواند به این نتیجه برسد که صاحب کارت از آن استفاده می کند. . به لطف این مزیت های Big Data، مرزهایی که انبارهای داده سنتی با آن وقف شده اند در حال گسترش است.
برای یک تصمیم موفقیتآمیز برای اجرای راهحلهای کلان داده، یک شرکت باید یک مورد سرمایهگذاری را محاسبه کند و این به دلیل بسیاری از مؤلفههای ناشناخته، مشکلات زیادی را ایجاد میکند. پارادوکس تحلیل در چنین مواردی پیش بینی آینده بر اساس گذشته است که اطلاعاتی در مورد آن اغلب وجود ندارد. در این مورد، یک عامل مهم برنامه ریزی واضح اقدامات اولیه شما است:
- در مرحله اول، تعیین یک مشکل تجاری خاص، که برای آن از فناوری های داده های بزرگ استفاده می شود، ضروری است، این کار به هسته اصلی تعیین صحت مفهوم انتخاب شده تبدیل می شود. شما باید روی جمع آوری داده های مربوط به این کار خاص تمرکز کنید و در طول اثبات مفهوم، می توانید از ابزارها، فرآیندها و روش های مدیریتی مختلفی استفاده کنید که به شما امکان می دهد در آینده تصمیمات آگاهانه تری بگیرید.
- ثانیاً، بعید است که یک شرکت بدون مهارت و تجربه تجزیه و تحلیل داده بتواند با موفقیت یک پروژه کلان داده را پیاده سازی کند. دانش لازم همیشه از تجربه قبلی در تجزیه و تحلیل می آید که عامل اصلی تأثیرگذار بر کیفیت کار با داده ها است. فرهنگ استفاده از داده ها نقش مهمی ایفا می کند، زیرا اغلب تجزیه و تحلیل اطلاعات باز می شود حقیقت تلخدر مورد تجارت، و برای پذیرش و کار با این حقیقت، به روش های توسعه یافته کار با داده ها نیاز است.
- ثالثاً، ارزش فناوری های کلان داده در ارائه بینش نهفته است.تحلیلگران خوب همچنان در بازار کمبود دارند. آنها متخصصانی نامیده می شوند که درک عمیقی از معنای تجاری داده ها دارند و می دانند چگونه آنها را به درستی اعمال کنند. تجزیه و تحلیل داده ها ابزاری برای دستیابی به اهداف تجاری است و برای درک ارزش کلان داده ها، شما نیاز به یک مدل رفتاری مناسب و درک اقدامات خود دارید. در این مورد، داده های بزرگ چیزهای زیادی را ارائه می دهند اطلاعات مفیددر مورد مصرف کنندگان، که بر اساس آن می توانید تصمیمات تجاری مفیدی بگیرید.
علیرغم این واقعیت که بازار داده های بزرگ روسیه به تازگی در حال شکل گیری است، برخی از پروژه ها در این زمینه در حال حاضر با موفقیت اجرا می شوند. برخی از آنها در زمینه جمع آوری داده ها موفق هستند، مانند پروژه های خدمات مالیاتی فدرال و سیستم های اعتباری Tinkoff، برخی دیگر از نظر تجزیه و تحلیل داده ها و کاربرد عملی نتایج آن: این پروژه Synqera است.
بانک سیستم های اعتباری Tinkoff پروژه ای را برای پیاده سازی پلت فرم EMC2 Greenplum، که ابزاری برای محاسبات موازی گسترده است، اجرا کرد. در سالهای اخیر، این بانک الزامات سرعت پردازش اطلاعات انباشته و تجزیه و تحلیل دادههای لحظهای را افزایش داده است که ناشی از نرخ رشد بالای تعداد کاربران است. کارت های اعتباری. بانک اعلام کرد که قصد دارد استفاده از فناوریهای Big Data را گسترش دهد، به ویژه برای پردازش دادههای بدون ساختار و کار با اطلاعات شرکت هااز منابع مختلف به دست آمده است.
سرویس مالیات فدرال روسیه در حال حاضر در حال ایجاد یک لایه تحلیلی از انبار داده فدرال است. بر اساس آن، یکپارچه فضای اطلاعاتیو فناوری دسترسی به داده های مالیاتی برای پردازش آماری و تحلیلی. در طول اجرای پروژه، کار برای متمرکز سازی در حال انجام است اطلاعات تحلیلیبا بیش از 1200 منبع سطح محلی IFTS.
یکی دیگر مثال جالبتجزیه و تحلیل داده های بزرگ در زمان واقعی استارتاپ روسی Synqera است که پلتفرم Simplate را توسعه داده است. این راه حل مبتنی بر پردازش آرایه های داده بزرگ است، برنامه اطلاعات مربوط به مشتریان، تاریخچه خرید، سن، جنسیت و حتی خلق و خوی آنها را تجزیه و تحلیل می کند. در صندوق ها در شبکه فروشگاه های لوازم آرایشی نصب شد صفحه نمایش های لمسیبا حسگرهایی که احساسات مشتریان را تشخیص می دهند. این برنامه خلق و خوی فرد را تعیین می کند، اطلاعات مربوط به او را تجزیه و تحلیل می کند، زمان روز را تعیین می کند و پایگاه داده تخفیف فروشگاه را اسکن می کند، پس از آن پیام های هدفمندی را در مورد تبلیغات و به خریدار ارسال می کند. پیشنهادهای ویژه. این راه حل وفاداری مشتری را بهبود می بخشد و فروش خرده فروش را افزایش می دهد.
اگر در مورد موارد موفق خارجی صحبت کنیم، در این زمینه، تجربه استفاده از فناوری های Big Data در Dunkin` Donuts که از داده های بلادرنگ برای فروش محصولات استفاده می کند، جالب است. نمایشگرهای دیجیتال در فروشگاه ها پیشنهاداتی را به نمایش می گذارند که هر دقیقه بسته به زمان روز و در دسترس بودن محصول تغییر می کند. طبق دریافتهای نقدی، شرکت دادههایی را دریافت میکند که کدام پیشنهادها بیشترین پاسخ را از سوی خریداران دریافت کردهاند. این رویکرد پردازش داده باعث افزایش سود و گردش کالا در انبار شد.
همانطور که تجربه اجرای پروژه های Big Data نشان می دهد، این حوزه برای حل موفقیت آمیز مشکلات تجاری مدرن طراحی شده است. در عین حال، یک عامل مهم در دستیابی به اهداف تجاری هنگام کار با داده های بزرگ، انتخاب استراتژی مناسب است که شامل تجزیه و تحلیل هایی است که درخواست های مصرف کننده را شناسایی می کند و همچنین استفاده از فن آوری های نوآورانهدر زمینه داده های بزرگ
بر اساس یک نظرسنجی جهانی که سالانه توسط Econsultancy و Adobe از سال 2012 در میان بازاریابان شرکت ها انجام می شود، "داده های بزرگ" که اقدامات افراد در اینترنت را مشخص می کند، می تواند کارهای زیادی انجام دهد. آنها میتوانند فرآیندهای کسبوکار آفلاین را بهینهسازی کنند، به درک اینکه چگونه صاحبان دستگاههای تلفن همراه از آنها برای جستجوی اطلاعات استفاده میکنند یا به سادگی «بازاریابی را بهتر میکنند» کمک کنند. کارآمدتر. علاوه بر این، آخرین تابع از سال به سال محبوب تر می شود، همانطور که در نمودار ما نشان داده شده است.
زمینه های اصلی کار بازاریابان اینترنتی از نظر ارتباط با مشتری

منبع: Econsultancy و Adobe، منتشر شده استemarketer.com
توجه داشته باشید که ملیت پاسخ دهندگان واجد اهمیت زیادندارد. بر اساس نظرسنجی انجام شده توسط KPMG در سال 2013، نسبت "خوشبین"، یعنی. از کسانی که از Big Data هنگام توسعه یک استراتژی تجاری استفاده می کنند، 56٪ است و نوسانات از منطقه به منطقه کوچک است: از 63٪ در کشورهای آمریکای شمالی تا 50٪ در EMEA.
استفاده از داده های بزرگ در مناطق مختلف جهان

منبع: KPMG، منتشر شده استemarketer.com
در همین حال، نگرش بازاریابان به چنین "روندهای مد" تا حدودی یادآور یک حکایت معروف است:
بگو وانو تو گوجه فرنگی دوست داری؟
- من دوست دارم غذا بخورم، اما نه.
با وجود این واقعیت که بازاریابان می گویند که آنها Big Data را «دوست دارند» و حتی به نظر می رسد از آن استفاده می کنند، در واقع «همه چیز پیچیده است»، زیرا آنها در مورد دلبستگی های قلبی خود در شبکه های اجتماعی می نویسند.
طبق نظرسنجی انجام شده توسط Circle Research در ژانویه 2014 در میان بازاریابان اروپایی، 4 نفر از 5 پاسخ دهندگان از Big Data استفاده نمی کنند (با وجود این واقعیت که آنها، البته، آن را "دوست دارند"). دلایل متفاوت است. تعداد کمی از شکاکان بدبین وجود دارد - 17٪ و دقیقاً همان تعداد پادپاهای آنها، یعنی. کسانی که با اطمینان پاسخ می دهند "بله". بقیه مردد و شک هستند، «مرداب». آنها با بهانه های قابل قبولی مانند «هنوز نه، اما به زودی» یا «منتظر شروع دیگران هستیم» از پاسخ مستقیم طفره می روند.
استفاده از داده های بزرگ توسط بازاریابان، اروپا، ژانویه 2014

منبع:dnx، منتشر شده -بازاریابcom
چه چیزی آنها را گیج می کند؟ مزخرف محض برخی (دقیقا نیمی از آنها) به سادگی این داده ها را باور نمی کنند. دیگران (همچنین تعداد کمی از آنها وجود دارد - 55٪) به سختی می توانند مجموعه "داده ها" و "کاربران" را بین خود مرتبط کنند. یک نفر (بگذارید از نظر سیاسی درست بگوییم) یک آشفتگی درونی شرکتی دارد: دادهها بدون مالک بین بخشهای بازاریابی و ساختارهای فناوری اطلاعات حرکت میکنند. برای دیگران، نرم افزار نمی تواند با هجوم کار کنار بیاید. و غیره. از آنجایی که کل سهام بسیار بالای 100 درصد است، واضح است که وضعیت «موانع متعدد» غیرعادی نیست.
موانعی که از استفاده از داده های بزرگ در بازاریابی جلوگیری می کند

منبع:dnx، منتشر شده -بازاریابcom
بنابراین، ما باید بگوییم که تا کنون "داده های بزرگ" یک پتانسیل بزرگ است که هنوز باید از آن استفاده شود. به هر حال، این ممکن است دلیلی باشد که Big Data هاله "روند مد" خود را از دست می دهد، همانطور که توسط داده های نظرسنجی انجام شده توسط شرکت Econsultancy که قبلاً ذکر کردیم نشان می دهد.
مهم ترین روندها در بازاریابی دیجیتال 2013-2014

منبع: مشاوره و Adobe
آنها با یک پادشاه دیگر جایگزین می شوند - بازاریابی محتوا. چه مدت؟
نمی توان گفت که داده های بزرگ یک پدیده اساساً جدید است. منابع کلان داده سالهاست که وجود داشته اند: پایگاه های داده خرید مشتری، تاریخچه اعتباری، شیوه زندگی. و برای سالها، دانشمندان از این دادهها برای کمک به شرکتها در ارزیابی ریسک و پیشبینی نیازهای آینده مشتریان استفاده کردهاند. اما امروزه وضعیت از دو جنبه تغییر کرده است:
ابزارها و روش های پیچیده تری برای تجزیه و تحلیل و ترکیب مجموعه داده های مختلف پدید آمده است.
این ابزارهای تحلیلی با انبوهی از منابع داده جدید که توسط دیجیتالی کردن تقریباً هر روش جمعآوری و اندازهگیری دادهها هدایت میشوند، تکمیل میشوند.
گستره اطلاعات موجود برای محققانی که در یک محیط تحقیقاتی ساختاریافته بزرگ شده اند، هم الهام بخش و هم ترسناک است. احساسات مصرف کننده توسط وب سایت ها و انواع رسانه های اجتماعی ضبط می شود. واقعیت مشاهده تبلیغات نه تنها ثبت می شود ست تاپ باکس ها، بلکه با برچسب های دیجیتال و دستگاه های تلفن همراهارتباط با تلویزیون
دادههای رفتاری (مانند تعداد تماسها، عادات خرید و خریدها) اکنون در زمان واقعی در دسترس هستند. بنابراین، بسیاری از چیزهایی که قبلاً میتوانستند از طریق تحقیق یاد بگیرند، اکنون میتوانند از طریق منابع کلان داده یاد بگیرند. و تمام این دارایی های اطلاعاتی بدون در نظر گرفتن هر گونه فرآیند تحقیقاتی به طور مداوم در حال تولید هستند. این تغییرات ما را به این فکر میاندازد که آیا کلان داده میتواند جایگزین تحقیقات بازار کلاسیک شود.
این در مورد داده ها نیست، بلکه در مورد پرسش و پاسخ است
قبل از دستور دادن ناقوس مرگ برای تحقیقات کلاسیک، باید به خود یادآوری کنیم که وجود این یا آن دارایی داده نیست، بلکه چیز دیگری است که تعیین کننده است. دقیقا چه چیزی؟ توانایی ما برای پاسخ دادن به سوالات، همین است. یک چیز خنده دار در مورد دنیای جدید داده های بزرگ این است که نتایج حاصل از دارایی های داده جدید منجر به سؤالات حتی بیشتر می شود و این سؤالات معمولاً توسط تحقیقات سنتی به بهترین وجه پاسخ داده می شوند. بنابراین، با رشد دادههای بزرگ، شاهد افزایش موازی در دسترس بودن و تقاضا برای «دادههای کوچک» هستیم که میتواند پاسخهایی به سؤالات دنیای دادههای بزرگ ارائه دهد.
بیایید وضعیتی را در نظر بگیریم: یک تبلیغ کننده بزرگ دائماً ترافیک فروشگاه ها و حجم فروش را در زمان واقعی نظارت می کند. روشهای تحقیق موجود (که در آن از شرکتکنندگان در پانلهای تحقیقاتی درباره انگیزههای خرید و رفتارشان در محل فروش میپرسیم) به ما کمک میکند تا بخشهای خاص مشتری را بهتر هدف قرار دهیم. این روششناسیها را میتوان گسترش داد تا طیف وسیعتری از داراییهای کلان داده را در بر گیرد، تا جایی که دادههای بزرگ به وسیلهای برای مشاهده غیرفعال و تحقیق به روشی برای بررسی مداوم و با تمرکز محدود تغییرات یا رویدادهایی که نیاز به مطالعه دارند، تبدیل میشوند. به این ترتیب کلان داده ها می توانند تحقیقات را از روال غیر ضروری رها کنند. تحقیقات اولیه دیگر نباید بر آنچه در حال وقوع است متمرکز شود (داده های بزرگ خواهد شد). در عوض، تحقیقات اولیه میتواند بر توضیح اینکه چرا ما روندها یا انحرافات خاصی را از روندها میبینیم تمرکز کند. محقق قادر خواهد بود کمتر در مورد بدست آوردن داده ها فکر کند و بیشتر در مورد چگونگی تجزیه و تحلیل و استفاده از آنها فکر کند.
در عین حال، می بینیم که کلان داده یکی از بزرگترین مشکلات ما را حل می کند، مشکل مطالعات بیش از حد طولانی. بررسی خود مطالعات نشان داده است که ابزارهای تحقیقاتی بیش از حد متورم تأثیر منفی بر کیفیت داده ها دارند. اگرچه بسیاری از کارشناسان برای مدت طولانی به این مشکل اذعان داشتند، اما همیشه با این عبارت پاسخ دادند: "اما من به این اطلاعات برای مدیریت ارشد نیاز دارم" و مصاحبه های طولانی ادامه یافت.
در دنیای داده های بزرگ، جایی که می توان شاخص های کمی را از طریق مشاهده غیرفعال به دست آورد، این موضوع مطرح می شود. دوباره، بیایید به تمام این تحقیقات مصرف فکر کنیم. اگر داده های بزرگ به ما بینشی در مورد مصرف از طریق مشاهده غیرفعال به ما بدهد، در آن صورت تحقیقات اولیه در قالب نظرسنجی دیگر نیازی به جمع آوری این نوع اطلاعات ندارد و ما در نهایت می توانیم دیدگاه خود را از نظرسنجی های کوتاه نه تنها با آرزوهای خوب، بلکه با چیزی واقعی
Big Data به کمک شما نیاز دارد
در نهایت، "بزرگ" تنها یکی از ویژگی های داده های بزرگ است. مشخصه "بزرگ" به اندازه و مقیاس داده ها اشاره دارد. البته، این ویژگی اصلی است، زیرا حجم این داده ها فراتر از محدوده همه چیزهایی است که قبلاً با آن کار کرده ایم. اما ویژگیهای دیگر این جریانهای داده جدید نیز مهم هستند: آنها اغلب قالببندی ضعیفی دارند، ساختاری ندارند (یا در بهترین حالت، تا حدی ساختار یافتهاند) و مملو از عدم قطعیت هستند. حوزه نوظهور مدیریت داده که به درستی «تحلیل نهادی» نامیده می شود، هدف آن حل مشکل غلبه بر نویز در داده های بزرگ است. وظیفه آن تجزیه و تحلیل این مجموعه داده ها و یافتن تعداد مشاهدات برای یک شخص است، مشاهدات فعلی و کدام یک از آنها قابل استفاده هستند.
این نوع پاکسازی داده ها برای حذف نویز یا داده های اشتباه هنگام کار با دارایی های داده بزرگ یا کوچک ضروری است، اما کافی نیست. ما همچنین باید بر اساس تجربیات قبلی، تجزیه و تحلیل و دانش دسته بندی، زمینه ای پیرامون دارایی های کلان داده ایجاد کنیم. در واقع، بسیاری از تحلیلگران به توانایی مدیریت عدم قطعیت ذاتی در کلان داده ها به عنوان منبع مزیت رقابتی اشاره می کنند، زیرا تصمیم گیری بهتر را ممکن می سازد.
و اینجاست که تحقیقات اولیه نه تنها به لطف دادههای بزرگ از کارهای روزمره رها میشود، بلکه به ایجاد و تجزیه و تحلیل محتوا در دادههای بزرگ نیز کمک میکند.
نمونه بارز این کار، استفاده از چارچوب جدید ارزش ویژه برند ما در رسانه های اجتماعی است. (ما در مورد یک توسعه یافته صحبت می کنیممیلوارد رنگ قهوه ایرویکردی جدید برای اندازه گیری ارزش برندرا معنی دار ناهمسان چارچوب- "پارادایم تفاوت های مهم" -آر & تی ). این مدل در بازارهای خاص مورد آزمایش رفتار قرار می گیرد، بر اساس استاندارد پیاده سازی می شود و به راحتی می تواند در سایر رشته های بازاریابی و سیستم های اطلاعات پشتیبانی تصمیم اعمال شود. به عبارت دیگر، مدل ارزش ویژه برند ما، که مبتنی بر تحقیقات پیمایشی است (البته نه تنها تحقیقات پیمایشی)، دارای تمام ویژگی های مورد نیاز برای غلبه بر ماهیت بدون ساختار، قطع و نامشخص کلان داده است.
دادههای احساسات مصرفکننده ارائه شده توسط رسانههای اجتماعی را در نظر بگیرید. در شکل خام، اوج ها و دره ها در احساسات مصرف کننده اغلب با معیارهای آفلاین ارزش ویژه برند و رفتار همبستگی دارند: به سادگی نویز بیش از حد در داده ها وجود دارد. اما ما میتوانیم این نویز را با استفاده از مدلهای معنای مصرفکننده، تمایز برند، پویایی و هویت خود در دادههای خام احساسات مصرفکننده، که راهی برای پردازش و جمعآوری دادههای رسانههای اجتماعی در این ابعاد است، کاهش دهیم.
هنگامی که داده ها بر اساس مدل چارچوب ما سازماندهی می شوند، روندهای شناسایی شده معمولاً با اندازه گیری های ارزش ویژه برند و رفتار به دست آمده به صورت آفلاین مطابقت دارند. در واقع، داده های رسانه های اجتماعی نمی توانند برای خود صحبت کنند. استفاده از آنها برای این منظور نیاز به تجربه و مدل هایی دارد که بر اساس برندها ساخته شده اند. وقتی رسانههای اجتماعی اطلاعات منحصربهفردی را به ما میدهند که به زبانی بیان میشود که مصرفکنندگان برای توصیف برندها از آن استفاده میکنند، ما باید هنگام ایجاد تحقیقات خود از آن زبان استفاده کنیم تا تحقیقات اولیه را بسیار مؤثرتر کنیم.
مزایای مطالعات معافیت
این ما را به این واقعیت برمیگرداند که دادههای بزرگ نه آنقدر که جایگزین تحقیقات میشوند بلکه آنها را آزاد میکنند. محققان از اینکه مجبورند برای هر مورد جدید یک مطالعه جدید ایجاد کنند راحت خواهند شد. داراییهای کلان دادهای که همیشه در حال رشد هستند را میتوان برای موضوعات مختلف تحقیقاتی مورد استفاده قرار داد و به تحقیقات اولیه بعدی اجازه میدهد تا عمیقتر به موضوع بپردازند و شکافها را پر کنند. محققان از تکیه بر نظرسنجی های بیش از حد متورم رهایی خواهند یافت. در عوض، آنها قادر خواهند بود از نظرسنجی های کوتاه استفاده کنند و بر روی مهمترین پارامترها تمرکز کنند که کیفیت داده ها را بهبود می بخشد.
با این نسخه، محققان میتوانند از اصول و بینشهای تثبیتشده خود برای افزودن دقت و معنا به داراییهای کلان داده استفاده کنند که منجر به ایجاد زمینههای جدیدی برای تحقیقات نظرسنجی میشود. این چرخه باید به درک عمیقتر در مورد طیف وسیعی از موضوعات استراتژیک و در نهایت حرکت به سمت آنچه که همیشه باید هدف اصلی ما از اطلاعرسانی و بهبود کیفیت تصمیمات برند و ارتباطات باشد، منجر شود.
معمولاً وقتی از پردازش تحلیلی جدی صحبت می کنند، به خصوص اگر از اصطلاح داده کاوی استفاده کنند، به این معنی است که حجم عظیمی از داده وجود دارد. در حالت کلی، اینطور نیست، زیرا اغلب اوقات شما باید مجموعه داده های کوچکی را پردازش کنید و یافتن الگوها در آنها آسان تر از صدها میلیون رکورد نیست. اگر چه شکی وجود ندارد که نیاز به جستجوی الگوها در پایگاه های داده بزرگ، کار غیر پیش پا افتاده تحلیل را پیچیده می کند.
این وضعیت به ویژه برای مشاغل مرتبط با خرده فروشی، مخابرات ، بانک ، اینترنت. پایگاه های داده آنها حجم عظیمی از اطلاعات مربوط به تراکنش ها را جمع آوری می کند: چک ها، پرداخت ها، تماس ها، گزارش ها و غیره.
هیچ روش جهانی تحلیل یا الگوریتم مناسب برای هر مورد و هر مقدار اطلاعات وجود ندارد. روش های تجزیه و تحلیل داده ها از نظر عملکرد، کیفیت نتایج، سهولت استفاده و نیاز به داده ها به طور قابل توجهی با یکدیگر تفاوت دارند. بهینه سازی را می توان در سطوح مختلف انجام داد: تجهیزات، پایگاه های داده، پلت فرم تحلیلی، آماده سازی داده های اولیه، الگوریتم های تخصصی. تجزیه و تحلیل حجم زیادی از داده ها نیازمند رویکرد خاصی است، زیرا پردازش آنها تنها با استفاده از "از نظر فنی دشوار است نیروی بی رحم"، یعنی استفاده از تجهیزات قوی تر.
البته می توانید سرعت پردازش داده ها را به دلیل تجهیزات پربارتر افزایش دهید، به خصوص که سرورها و ایستگاه های کاری مدرن از پردازنده های چند هسته ای استفاده می کنند. رماندازه قابل توجه و آرایه های دیسک قدرتمند. با این حال، روشهای بسیار دیگری برای پردازش مقادیر زیادی داده وجود دارد که به شما امکان میدهد مقیاسپذیری را افزایش دهید و نیازی به آن ندارید به روز رسانی بی پایانتجهیزات.
ویژگی های DBMS
پایگاه های داده مدرن شامل مکانیسم های مختلفی است که استفاده از آنها سرعت پردازش تحلیلی را به میزان قابل توجهی افزایش می دهد:
- محاسبه اولیه داده ها اطلاعاتی که اغلب برای تجزیه و تحلیل استفاده می شود را می توان از قبل محاسبه کرد (مثلاً در شب) و به شکلی که برای پردازش در سرور پایگاه داده آماده شده است در قالب مکعب های چند بعدی ، نماهای مادی شده ، جداول ویژه ذخیره می شود.
- کش کردن جدول در رم. داده هایی که فضای کمی را اشغال می کنند، اما اغلب در طول تجزیه و تحلیل به آنها دسترسی پیدا می کنند، به عنوان مثال، دایرکتوری ها، می توانند با استفاده از ابزارهای پایگاه داده در حافظه پنهان ذخیره شوند. به این ترتیب، تماسهای زیرسیستم دیسک کندتر چندین برابر کاهش مییابد.
- پارتیشن بندی جداول به پارتیشن و جدول. می توانید داده ها، فهرست ها، جداول کمکی را روی دیسک های جداگانه قرار دهید. این به DBMS اجازه می دهد تا اطلاعات را به صورت موازی روی دیسک بخواند و بنویسد. علاوه بر این، جداول را می توان به بخش هایی (پارتیشن) تقسیم کرد به گونه ای که هنگام دسترسی به داده ها حداقل تعداد عملیات دیسک وجود داشته باشد. به عنوان مثال، اگر ما اغلب دادههای ماه گذشته را تجزیه و تحلیل میکنیم، میتوانیم به طور منطقی از یک جدول با دادههای تاریخی استفاده کنیم، اما به صورت فیزیکی آن را به چند بخش تقسیم کنیم تا هنگام دسترسی به دادههای ماهانه، یک بخش کوچک خوانده شود و هیچ دسترسی به آن وجود نداشته باشد. تمام داده های تاریخی
این تنها بخشی از امکاناتی است که DBMS مدرن ارائه می کند. ده ها راه دیگر برای افزایش سرعت استخراج اطلاعات از پایگاه داده وجود دارد: نمایه سازی منطقی، ساختن طرح های پرس و جو، پردازش موازی پرس و جوهای SQL، استفاده از خوشه ها، تهیه داده های تجزیه و تحلیل شده با استفاده از رویه های ذخیره شده و تریگرها در سمت سرور پایگاه داده و غیره. علاوه بر این، بسیاری از این مکانیسم ها را می توان نه تنها با استفاده از DBMS "سنگین"، بلکه همچنین با استفاده از پایگاه های داده رایگان استفاده کرد.
ترکیبی از مدل ها
فرصت های بهبود سرعت به بهینه سازی پایگاه داده محدود نمی شود، با ترکیب مدل های مختلف می توان کارهای زیادی انجام داد. مشخص است که سرعت پردازش به طور قابل توجهی با پیچیدگی دستگاه ریاضی مورد استفاده مرتبط است. هرچه مکانیسم های تحلیل ساده تری استفاده شود، داده ها سریعتر تجزیه و تحلیل می شوند.
می توان سناریوی پردازش داده را به گونه ای ساخت که داده ها از طریق غربال مدل ها "رانده" شوند. یک ایده ساده در اینجا کاربرد دارد: زمان را برای پردازش چیزهایی که نمی توانید تجزیه و تحلیل کنید تلف نکنید.
ابتدا از ساده ترین الگوریتم ها استفاده می شود. بخشی از داده هایی که می توان با استفاده از چنین الگوریتم هایی پردازش کرد و پردازش آنها با استفاده بیشتر بی معنی است روش های پیچیده، تجزیه و تحلیل می شود و از پردازش بیشتر حذف می شود. دادههای باقیمانده به مرحله بعدی پردازش منتقل میشوند، جایی که از الگوریتمهای پیچیدهتر استفاده میشود و به همین ترتیب در زنجیره. در آخرین گره سناریوی پردازش، از پیچیده ترین الگوریتم ها استفاده می شود، اما میزان داده های تحلیل شده چندین برابر کمتر از نمونه اولیه است. در نتیجه، کل زمان مورد نیاز برای پردازش همه دادهها با مرتبهای کاهش مییابد.
بیاوریم مثال عملیبا استفاده از این رویکرد هنگام حل مشکل پیش بینی تقاضا، در ابتدا توصیه می شود که تجزیه و تحلیل XYZ را انجام دهید، که به شما امکان می دهد تعیین کنید که تقاضا برای کالاهای مختلف چقدر پایدار است. محصولات گروه X کاملاً پایدار فروخته می شوند ، بنابراین استفاده از الگوریتم های پیش بینی برای آنها به شما امکان می دهد پیش بینی با کیفیت بالایی داشته باشید. محصولات گروه Y با ثبات کمتری فروخته می شوند، شاید برای آنها ارزش ساختن مدل هایی را داشته باشد نه برای هر مقاله، بلکه برای یک گروه، این به شما امکان می دهد سری های زمانی را صاف کنید و از عملکرد الگوریتم پیش بینی اطمینان حاصل کنید. محصولات گروه Z به طور آشفته فروخته می شوند، بنابراین به هیچ وجه نباید برای آنها مدل های پیش بینی بسازید، نیاز آنها را باید بر اساس فرمول های ساده مثلاً میانگین فروش ماهانه محاسبه کرد.
طبق آمار، حدود 70 درصد مجموعه را محصولات گروه Z تشکیل می دهد. 25 درصد دیگر را محصولات گروه Y و تنها حدود 5 درصد را محصولات گروه X تشکیل می دهند. بنابراین، ساخت و استفاده از مدل های پیچیده برای یک حداکثر 30 درصد محصولات بنابراین، استفاده از رویکردی که در بالا توضیح داده شد، زمان تجزیه و تحلیل و پیش بینی را 5-10 برابر کاهش می دهد.
پردازش موازی
یکی دیگر از استراتژیهای مؤثر برای پردازش مقادیر زیاد داده، تقسیم دادهها به بخشها و ساخت مدلهایی برای هر بخش به طور جداگانه، با ادغام بیشتر نتایج است. اغلب، در حجم زیادی از داده ها، می توان چندین زیر مجموعه مجزا را از یکدیگر متمایز کرد. به عنوان مثال، اینها می توانند گروهی از مشتریان، کالاهایی باشند که رفتار مشابهی دارند و توصیه می شود برای آنها یک مدل ساخته شود.
در این حالت، به جای ساخت یک مدل پیچیده برای همه، می توانید چندین مدل ساده برای هر بخش بسازید. این رویکرد سرعت تجزیه و تحلیل را بهبود می بخشد و نیاز به حافظه را با پردازش مقادیر کمتری از داده در یک پاس کاهش می دهد. علاوه بر این، در این مورد، پردازش تحلیلی را می توان موازی کرد، که همچنین تأثیر مثبتی بر زمان صرف شده دارد. علاوه بر این، مدلهایی برای هر بخش میتواند توسط تحلیلگران مختلف ساخته شود.
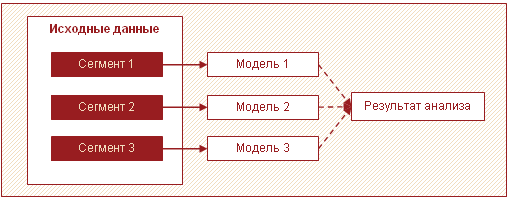
علاوه بر افزایش سرعت، این رویکرد یک مزیت مهم دیگر نیز دارد - ایجاد و نگهداری چندین مدل نسبتا ساده به صورت جداگانه آسانتر از یک مدل بزرگ است. شما می توانید مدل ها را به صورت مرحله ای اجرا کنید و به این ترتیب اولین نتایج را در کمترین زمان ممکن به دست آورید.
نمونه های نمایندگی
در حضور مقادیر زیادی داده، می توان از همه اطلاعات برای ساخت یک مدل استفاده نکرد، بلکه از برخی زیر مجموعه ها - یک نمونه معرف استفاده کرد. یک نمونه نماینده به درستی آماده شده حاوی اطلاعات لازم برای ساخت یک مدل با کیفیت است.
فرآیند پردازش تحلیلی به دو بخش تقسیم میشود: ساخت مدل و استفاده از مدل ساخته شده برای دادههای جدید. ساختن یک مدل پیچیده فرآیندی با منابع فشرده است. بسته به الگوریتم مورد استفاده، داده ها ذخیره می شوند، هزاران بار اسکن می شوند، بسیاری از پارامترهای کمکی محاسبه می شوند و غیره. استفاده از مدل از قبل ساخته شده برای داده های جدید به منابع ده ها و صدها برابر کمتر نیاز دارد. اغلب اوقات به محاسبه چند توابع ساده ختم می شود.
بنابراین، اگر مدل بر روی مجموعههای نسبتاً کوچکی ساخته شود و متعاقباً در کل مجموعه داده اعمال شود، زمان به دست آوردن نتیجه در مقایسه با تلاش برای بازسازی کامل کل مجموعه دادههای موجود کاهش مییابد.

برای به دست آوردن نمونه های نماینده، روش های خاصی وجود دارد، به عنوان مثال، نمونه برداری. استفاده از آنها به شما امکان می دهد تا سرعت پردازش تحلیلی را بدون به خطر انداختن کیفیت تجزیه و تحلیل افزایش دهید.
خلاصه
رویکردهای توصیف شده تنها بخش کوچکی از روش هایی هستند که به شما امکان تجزیه و تحلیل حجم عظیمی از داده ها را می دهند. راه های دیگری نیز وجود دارد، به عنوان مثال استفاده از الگوریتم های مقیاس پذیر ویژه، مدل های سلسله مراتبی، یادگیری پنجره ها و غیره.
تحلیل و بررسی پایگاه های عظیمداده کاوی یک کار غیر پیش پا افتاده است که در بیشتر موارد نمی توان آن را به صورت مستقیم حل کرد، با این حال پایگاه های داده مدرن و پلت فرم های تحلیلی روش های بسیاری را برای حل این مشکل ارائه می دهند. هنگامی که به طور عاقلانه استفاده می شود، سیستم ها قادر به پردازش ترابایت داده با سرعت معقولی هستند.
ستون معلمان HSE درباره افسانه ها و موارد کار با داده های بزرگ
به نشانک ها
کنستانتین رومانوف و الکساندر پیاتیگورسکی، مدرسان دانشکده رسانه های جدید HSE، که همچنین مدیر تحول دیجیتال در Beeline است، ستونی را برای سایت در مورد تصورات غلط اصلی در مورد کلان داده - نمونه هایی از استفاده از فناوری و ابزار نوشتند. نویسندگان پیشنهاد می کنند که این نشریه به رهبران شرکت کمک می کند تا این مفهوم را درک کنند.
افسانه ها و باورهای غلط در مورد داده های بزرگ
کلان داده بازاریابی نیست
اصطلاح Big Data بسیار مد شده است - در میلیون ها موقعیت و در صدها تفسیر مختلف استفاده می شود که اغلب به آنچه که هست مربوط نمی شود. اغلب در ذهن مردم جایگزینی مفاهیم وجود دارد و داده های بزرگ با یک محصول بازاریابی اشتباه گرفته می شود. علاوه بر این، در برخی از شرکت ها، داده های بزرگ بخشی از بخش بازاریابی است. نتیجه تجزیه و تحلیل کلان داده در واقع می تواند منبعی برای فعالیت بازاریابی باشد، اما نه چیزی بیشتر. بیایید ببینیم چگونه کار می کند.
اگر ما لیستی از کسانی را که دو ماه پیش در فروشگاه ما کالاهایی به ارزش بیش از سه هزار روبل خریدند شناسایی کردیم و سپس نوعی پیشنهاد را برای این کاربران ارسال کردیم، این یک بازاریابی معمولی است. ما یک الگوی واضح از داده های ساختاری استخراج می کنیم و از آن برای افزایش فروش استفاده می کنیم.
با این حال، اگر دادههای CRM را با اطلاعات استریم، مثلاً از اینستاگرام ترکیب کنیم و آنها را تجزیه و تحلیل کنیم، الگویی پیدا میکنیم: فردی که فعالیت خود را در عصر چهارشنبه کاهش داده است و آخرین عکسش بچه گربهها را نشان میدهد، باید پیشنهاد خاصی بدهد. از قبل بیگ دیتا خواهد بود. ما محرک را پیدا کردیم، آن را به بازاریابان دادیم و آنها از آن برای اهداف خود استفاده کردند.
از این نتیجه میشود که این فناوری معمولاً با دادههای بدون ساختار کار میکند و اگر دادهها ساختاری داشته باشند، سیستم همچنان به جستجوی الگوهای پنهان در آنها ادامه میدهد، که بازاریابی انجام نمیدهد.
کلان داده IT نیست
مرحله دوم این داستان: کلان داده اغلب با فناوری اطلاعات اشتباه گرفته می شود. این به این دلیل است که در شرکت های روسیبه عنوان یک قاعده، این متخصصان فناوری اطلاعات هستند که محرک همه فناوری ها، از جمله داده های بزرگ هستند. بنابراین، اگر همه چیز در این بخش اتفاق بیفتد، این تصور را برای کل شرکت ایجاد می کند که این نوعی فعالیت فناوری اطلاعات است.
در واقع، یک تفاوت اساسی در اینجا وجود دارد: Big Data فعالیتی با هدف به دست آوردن یک محصول خاص است که به هیچ وجه در مورد IT صدق نمی کند، اگرچه فناوری بدون آنها نمی تواند وجود داشته باشد.
کلان داده همیشه جمع آوری و تجزیه و تحلیل اطلاعات نیست
تصور نادرست دیگری درباره کلان داده وجود دارد. همه میدانند که این فناوری با حجم زیادی از دادهها همراه است، اما همیشه مشخص نیست که منظور از چه نوع دادههایی است. همه می توانند اطلاعات را جمع آوری و استفاده کنند، اکنون نه تنها در فیلم های مربوط به آن، بلکه در هر شرکت، حتی یک شرکت بسیار کوچک، امکان پذیر است. تنها سوال این است که دقیقاً چه چیزی را جمع آوری کنید و چگونه از آن به نفع خود استفاده کنید.
اما باید درک کرد که فناوری کلان داده جمع آوری و تجزیه و تحلیل مطلقاً هیچ اطلاعاتی نخواهد بود. به عنوان مثال، اگر دادههای مربوط به یک فرد خاص را در شبکههای اجتماعی جمعآوری کنید، دادههای بزرگ نخواهد بود.
Big Data واقعا چیست
کلان داده از سه عنصر تشکیل شده است:
- داده ها؛
- تجزیه و تحلیل؛
- فن آوری.
Big Data تنها یکی از این اجزا نیست، بلکه ترکیبی از هر سه عنصر است. اغلب مردم مفاهیم را جایگزین می کنند: کسی فکر می کند که کلان داده فقط داده است، کسی فکر می کند که فناوری است. اما در واقع، مهم نیست چقدر داده جمع آوری می کنید، بدون آن نمی توانید کاری انجام دهید فن آوری های لازمو تجزیه و تحلیل اگر تجزیه و تحلیل خوبی وجود داشته باشد، اما داده ای وجود نداشته باشد، بدتر است.
اگر در مورد داده ها صحبت می کنیم، پس این فقط متن ها نیست، بلکه تمام عکس های ارسال شده در اینستاگرام و به طور کلی همه چیزهایی هستند که می توانند برای اهداف و کارهای مختلف تجزیه و تحلیل و استفاده شوند. به عبارت دیگر داده به حجم عظیمی از داده های داخلی و خارجی ساختارهای مختلف اطلاق می شود.
تجزیه و تحلیل نیز مورد نیاز است، زیرا وظیفه Big Data ایجاد برخی الگوها است. یعنی تجزیه و تحلیل شناسایی وابستگی های پنهان و جستجوی پرسش ها و پاسخ های جدید بر اساس تجزیه و تحلیل کل حجم داده های ناهمگن است. علاوه بر این، داده های بزرگ سوالاتی را مطرح می کند که مستقیماً از این داده ها مشتق نمی شوند.
وقتی صحبت از تصاویر می شود، این واقعیت که شما عکسی از خود در یک تی شرت آبی ارسال کرده اید چیزی نمی گوید. اما اگر از یک عکس برای مدل سازی Big Data استفاده می کنید، ممکن است معلوم شود که در حال حاضر باید وام ارائه دهید، زیرا در گروه اجتماعی شما این رفتار نشان دهنده پدیده خاصی در اقدامات است. بنابراین، داده های "لخت" بدون تجزیه و تحلیل، بدون آشکار کردن وابستگی های پنهان و غیر آشکار، داده های بزرگ نیستند.
بنابراین ما داده های بزرگ داریم. آرایه آنها بسیار زیاد است. یک تحلیلگر هم داریم. اما چگونه می توانیم مطمئن شویم که یک راه حل خاص از این داده های خام متولد شده است؟ برای انجام این کار، ما به فناوریهایی نیاز داریم که به ما امکان میدهند نه تنها آنها را ذخیره کنیم (و قبلاً غیرممکن بود)، بلکه آنها را تجزیه و تحلیل کنیم.
به عبارت ساده، اگر داده های زیادی دارید، به فناوری هایی مانند Hadoop نیاز خواهید داشت که امکان ذخیره تمام اطلاعات را به شکل اصلی برای تجزیه و تحلیل بعدی فراهم می کند. چنین فناوری هایی در غول های اینترنتی به وجود آمدند، زیرا آنها اولین کسانی بودند که با مشکل ذخیره حجم زیادی از داده ها و تجزیه و تحلیل آن برای کسب درآمد بعدی مواجه شدند.
علاوه بر ابزارهایی برای ذخیره سازی داده ها بهینه و ارزان، به ابزارهای تحلیلی و همچنین افزونه هایی برای پلتفرم مورد استفاده نیاز است. به عنوان مثال، یک اکوسیستم کامل از پروژهها و فناوریهای مرتبط در اطراف Hadoop شکل گرفته است. در اینجا برخی از آنها آورده شده است:
- Pig یک زبان تجزیه و تحلیل داده های اعلامی است.
- Hive - تجزیه و تحلیل داده ها با استفاده از زبانی نزدیک به SQL.
- Oozie یک گردش کار در Hadoop است.
- Hbase - پایگاه داده (غیر رابطه ای)، آنالوگ Google Big Table.
- ماهوت - یادگیری ماشینی.
- Sqoop - انتقال داده از RSDDB به Hadoop و بالعکس.
- فلوم - انتقال لاگ ها به HDFS.
- Zookeeper، MRUnit، Avro، Giraph، Ambari، Cassandra، HCatalog، Fuse-DFS و غیره.
همه این ابزارها به صورت رایگان در دسترس همه هستند، اما مجموعه ای از افزونه های پولی نیز وجود دارد.
علاوه بر این، متخصصان مورد نیاز هستند: این یک توسعه دهنده و یک تحلیلگر است (به اصطلاح دانشمند داده). شما همچنین به مدیری نیاز دارید که بتواند درک کند که چگونه این تجزیه و تحلیل را برای یک کار خاص اعمال کند، زیرا به خودی خود کاملاً بی معنی است اگر در فرآیندهای تجاری تعبیه نشده باشد.
هر سه کارمند باید به صورت تیمی کار کنند. مدیری که به یک دانشمند داده وظیفه پیدا کردن یک الگوی خاص را میدهد باید درک کند که همیشه نمیتوان دقیقاً آنچه را که او نیاز دارد پیدا کرد. در این مورد، مدیر باید با دقت به آنچه دانشمند داده یافته است گوش دهد، زیرا اغلب یافته های او برای کسب و کار جالب تر و مفیدتر می شود. وظیفه شما این است که آن را در تجارت اعمال کنید و از آن محصولی بسازید.
علیرغم این واقعیت که در حال حاضر انواع مختلفی از ماشین ها و فناوری ها وجود دارد، تصمیم نهایی همیشه با خود شخص باقی می ماند. برای انجام این کار، اطلاعات باید به نحوی تجسم شوند. ابزارهای زیادی برای این کار وجود دارد.
گویاترین مثال گزارش های زمین تحلیلی است. شرکت Beeline با دولت های شهرها و مناطق مختلف بسیار کار می کند. اغلب، این سازمان ها گزارش هایی مانند "بار ترافیک در یک مکان خاص" را سفارش می دهند.
واضح است که چنین گزارشی باید به شکلی ساده و قابل فهم به دست سازمان های دولتی برسد. اگر یک جدول عظیم و کاملاً نامفهوم در اختیار آنها قرار دهیم (یعنی اطلاعاتی به شکلی که آن را دریافت می کنیم)، بعید است که چنین گزارشی را بخرند - کاملاً بی فایده خواهد بود، آنها دانش را از آن خارج نخواهند کرد. که می خواستند دریافت کنند.
بنابراین، مهم نیست که دانشمندان داده چقدر خوب باشند و هر چه الگوهایی پیدا کنند، بدون ابزارهای تجسم با کیفیت نمیتوانید با این دادهها کار کنید.
منابع داده
آرایه داده های دریافتی بسیار بزرگ است، بنابراین می توان آنها را به چند گروه تقسیم کرد.
داده های داخلی شرکت
اگرچه 80 درصد از داده های جمع آوری شده متعلق به این گروه است، اما همیشه از این منبع استفاده نمی شود. اغلب این دادههایی است که به نظر میرسد هیچ کس اصلاً به آنها نیاز ندارد، مثلاً لاگ. اما اگر از زاویه دیگری به آنها نگاه کنید، گاهی اوقات می توانید الگوهای غیرمنتظره ای را در آنها پیدا کنید.
منابع اشتراکافزار
این شامل داده ها می شود شبکه های اجتماعی، اینترنت و هر چیزی که می توانید به صورت رایگان وارد آن شوید. چرا اشتراک افزار؟ از یک طرف، این داده ها در دسترس همه است، اما اگر شرکت بزرگی هستید، دریافت آن به اندازه یک پایگاه مشترک ده ها هزار، صدها یا میلیون ها مشتری دیگر کار آسانی نیست. بنابراین، بازار دارد خدمات پولیبرای ارائه این داده ها
منابع پولی
این شامل شرکت هایی می شود که داده ها را برای پول می فروشند. اینها می توانند مخابرات، DMP ها، شرکت های اینترنتی، دفاتر اعتباری و تجمیع کننده ها باشند. در روسیه، مخابرات داده نمی فروشد. اولاً از نظر اقتصادی زیان آور است و ثانیاً قانوناً ممنوع است. بنابراین، آنها نتایج پردازش خود را می فروشند، به عنوان مثال، گزارش های geoanalytical.
باز کردن داده ها
ایالت نیازهای کسب و کار را برآورده می کند و استفاده از داده هایی را که آنها جمع آوری می کنند ممکن می سازد. این امر تا حد زیادی در غرب توسعه یافته است، اما روسیه نیز در این زمینه همگام با زمانه پیش می رود. به عنوان مثال، پورتال داده های باز دولت مسکو وجود دارد که اطلاعاتی را در مورد اشیاء مختلف زیرساخت های شهری منتشر می کند.
برای ساکنان و مهمانان مسکو، داده ها به صورت جدولی و نقشه برداری و برای توسعه دهندگان - در قالب های ویژه قابل خواندن توسط ماشین ارائه می شود. در حالی که پروژه در حالت محدود کار می کند، اما در حال توسعه است، به این معنی که منبع داده ای است که می توانید برای کارهای تجاری خود از آن استفاده کنید.
پژوهش
همانطور که قبلا ذکر شد، وظیفه Big Data پیدا کردن یک الگو است. اغلب، مطالعات در سراسر جهان می تواند به نقطه مرجعی برای یافتن یک الگوی خاص تبدیل شود - شما می توانید یک نتیجه خاص بگیرید و سعی کنید منطق مشابهی را برای اهداف خود اعمال کنید.
کلان داده حوزه ای است که همه قوانین ریاضی در آن کار نمی کنند. به عنوان مثال، "1" + "1" "2" نیست، بلکه بسیار بیشتر است، زیرا هنگام مخلوط کردن منابع داده، اثر را می توان تا حد زیادی افزایش داد.
نمونه های محصول
بسیاری از افراد با سرویس انتخاب موسیقی Spotify آشنا هستند. زیبایی آن این است که از کاربران نمی پرسد حال و هوای امروز آنها چیست، بلکه آن را بر اساس منابع موجود محاسبه می کند. او همیشه می داند که اکنون به چه چیزی نیاز دارید - جاز یا هارد راک. این تفاوت کلیدی است که برای او طرفدارانی فراهم می کند و او را از سایر خدمات متمایز می کند.

چنین محصولاتی معمولاً محصولات حسی نامیده می شوند - آنهایی که مشتری خود را احساس می کنند.
فناوری Big Data در صنعت خودروسازی نیز مورد استفاده قرار می گیرد. به عنوان مثال، تسلا این کار را انجام می دهد - در آنها آخرین مدلیک خلبان خودکار وجود دارد این شرکت در تلاش است تا خودرویی بسازد که مسافر را به جایی که باید برود ببرد. بدون Big Data، این غیرممکن است، زیرا اگر ما فقط از دادههایی استفاده کنیم که مستقیماً دریافت میکنیم، همانطور که یک شخص انجام میدهد، خودرو نمیتواند پیشرفت کند.

وقتی خودمان ماشین میرانیم، از نورونهایمان برای تصمیمگیری بر اساس عوامل زیادی استفاده میکنیم که حتی متوجه آنها هم نمیشویم. به عنوان مثال، ممکن است متوجه نشویم که چرا تصمیم گرفتیم فوراً چراغ سبز را روشن نکنیم، و سپس معلوم شود که تصمیم درست بوده است - خودرویی با سرعت سرسام آور از کنار شما گذشت و از تصادف جلوگیری کردید.
همچنین می توانید مثالی از استفاده از Big Data در ورزش بیاورید. در سال 2002، مدیر کل تیم بیسبال اوکلند دو و میدانی، بیلی بین، تصمیم گرفت تا پارادایم چگونگی جستجوی ورزشکاران را بشکند - او بازیکنان را "بر اساس اعداد" انتخاب و آموزش داد.
معمولاً مدیران به موفقیت بازیکنان نگاه می کنند ، اما در این مورد متفاوت بود - برای به دست آوردن نتیجه ، مدیر با توجه به ویژگی های فردی به چه ترکیبی از ورزشکاران نیاز داشت. علاوه بر این ، او ورزشکارانی را انتخاب کرد که به خودی خود پتانسیل بالایی نداشتند ، اما تیم در کل آنقدر موفق بود که بیست مسابقه متوالی را برد.

کارگردان بنت میلر متعاقباً فیلمی را به این داستان اختصاص داد - "مردی که همه چیز را تغییر داد" با بازی برد پیت.
فناوری Big Data در بخش مالی نیز مفید است. حتی یک نفر در جهان نمی تواند به طور مستقل و دقیق تعیین کند که آیا ارزش وام دادن به کسی را دارد یا خیر. برای تصمیم گیری، نمره گذاری انجام می شود، یعنی یک مدل احتمالی ساخته می شود که با آن می توان فهمید که آیا این شخص پول را پس می دهد یا خیر. علاوه بر این، امتیازدهی در تمام مراحل اعمال می شود: به عنوان مثال، می توانید محاسبه کنید که در یک لحظه مشخص، شخص پرداخت را متوقف می کند.
داده های بزرگ نه تنها به کسب درآمد، بلکه ذخیره آنها نیز اجازه می دهد. به ویژه، این فناوری به وزارت کار آلمان کمک کرد تا هزینه مزایای بیکاری را تا 10 میلیارد یورو کاهش دهد، زیرا پس از تجزیه و تحلیل اطلاعات مشخص شد که 20٪ از مزایا به طور غیرمستقیم پرداخت شده است.
فن آوری ها همچنین در پزشکی استفاده می شود (این امر به ویژه در مورد اسرائیل صادق است). با کمک بیگ دیتا می توانید تحلیل بسیار دقیق تری نسبت به یک پزشک با سی سال تجربه انجام دهید.
هر پزشک هنگام تشخیص، فقط به تجربه خود متکی است. هنگامی که دستگاه این کار را انجام می دهد، از تجربه هزاران پزشک از این قبیل و تمام سوابق پرونده موجود می آید. این در نظر می گیرد که خانه بیمار از چه موادی ساخته شده است، قربانی در چه منطقه ای زندگی می کند، چه دودی در آنجا وجود دارد و غیره. یعنی فاکتورهای زیادی را در نظر می گیرد که پزشکان در نظر نمی گیرند.
نمونه ای از استفاده از داده های بزرگ در مراقبت های بهداشتی، پروژه پروژه آرتمیس است که توسط بیمارستان کودکان تورنتو اجرا شد. آی تی سیستم اطلاعات، که داده های مربوط به نوزادان را در زمان واقعی جمع آوری و تجزیه و تحلیل می کند. این دستگاه به شما امکان می دهد در هر ثانیه 1260 شاخص سلامتی هر کودک را تجزیه و تحلیل کنید. این پروژه با هدف پیش بینی وضعیت ناپایدار کودک و پیشگیری از بیماری در کودکان انجام می شود.
استفاده از داده های بزرگ در روسیه نیز آغاز شده است: به عنوان مثال، Yandex دارای یک بخش کلان داده است. این شرکت به همراه AstraZeneca و انجمن روسی انکولوژی بالینی RUSSCO، پلتفرم RAY را برای ژنتیک دانان و زیست شناسان مولکولی راه اندازی کرد. این پروژه روش های تشخیص سرطان و شناسایی استعداد ابتلا به سرطان را بهبود می بخشد. این پلتفرم در دسامبر 2016 راه اندازی می شود.
اصطلاح Big Data معمولاً به هر مقدار داده ساختاریافته، نیمه ساختاریافته و بدون ساختار اشاره دارد. با این حال، می توان و باید دوم و سوم را برای تجزیه و تحلیل بعدی اطلاعات سفارش داد. کلان داده با حجم واقعی برابری نمی کند، اما در بیشتر موارد از Big Data صحبت می کنیم، منظور ما ترابایت، پتابایت و حتی اکسترا بایت اطلاعات است. این مقدار داده می تواند در هر کسب و کاری در طول زمان، یا در مواردی که یک شرکت نیاز به دریافت اطلاعات زیادی دارد، در زمان واقعی جمع شود.
تجزیه و تحلیل داده های بزرگ
در مورد تجزیه و تحلیل داده های بزرگ، اول از همه، منظور ما جمع آوری و ذخیره سازی اطلاعات از منابع مختلف است. به عنوان مثال، دادههای مربوط به مشتریانی که خرید کردهاند، ویژگیهای آنها، اطلاعات مربوط به راهاندازی شرکت های تبلیغاتیو ارزیابی اثربخشی آن، داده ها مرکز تماس. بله، همه این اطلاعات قابل مقایسه و تجزیه و تحلیل هستند. ممکن و ضروری است. اما برای این کار باید سیستمی راه اندازی کنید که به شما امکان می دهد اطلاعات را بدون تحریف اطلاعات جمع آوری و تبدیل کنید، آن ها را ذخیره کنید و در نهایت آن ها را تجسم کنید. موافقم، با داده های بزرگ، جداول چاپ شده در چندین هزار صفحه کمک چندانی به تصمیم گیری های تجاری نمی کند.
1. ورود کلان داده ها
اکثر سرویس هایی که اطلاعات مربوط به اقدامات کاربر را جمع آوری می کنند، قابلیت صادرات را دارند. برای اینکه آنها به شکل ساختار یافته وارد شرکت شوند، از انواع مختلفی استفاده می شود، به عنوان مثال، Alteryx. این نرم افزار امکان دریافت را به شما می دهد حالت خودکاراطلاعات، آنها را پردازش کنید، اما مهمتر از همه، تبدیل آن به نمای مورد نظرو بدون تحریف فرمت کنید.
2. ذخیره سازی و پردازش داده های بزرگ
تقریباً همیشه هنگام جمع آوری حجم زیادی از اطلاعات، مشکل ذخیره سازی آن به وجود می آید. از بین تمام پلتفرم هایی که ما مطالعه کردیم، شرکت ما Vertica را ترجیح می دهد. بر خلاف سایر محصولات، Vertica قادر است اطلاعات ذخیره شده در آن را به سرعت "داده" کند. از معایب آن می توان به ضبط طولانی مدت اشاره کرد، اما در هنگام تجزیه و تحلیل داده های بزرگ، سرعت بازگشت به منصه ظهور می رسد. به عنوان مثال، اگر ما در مورد کامپایل با استفاده از یک پتابایت اطلاعات صحبت می کنیم، سرعت آپلود یکی از مهمترین ویژگی ها است.
3. تجسم داده های بزرگ
و در نهایت، مرحله سوم تجزیه و تحلیل حجم زیادی از داده ها است. این نیاز به پلتفرمی دارد که بتواند به صورت بصری تمام اطلاعات دریافتی را به شکلی مناسب منعکس کند. به نظر ما، تنها یک محصول نرم افزاری، Tableau، می تواند با این کار کنار بیاید. قطعا یکی از بهترین هاست امروزراه حلی که قادر است هر اطلاعاتی را به صورت بصری نشان دهد، کار شرکت را به یک مدل سه بعدی تبدیل کند، اقدامات همه بخش ها را در یک زنجیره واحد به هم وابسته جمع آوری کند (در مورد قابلیت های Tableau می توانید بیشتر بخوانید).
به جای خلاصه، توجه می کنیم که تقریباً هر شرکتی اکنون می تواند داده های بزرگ خود را تولید کند. تجزیه و تحلیل کلان داده دیگر یک فرآیند پیچیده و پرهزینه نیست. اکنون مدیریت شرکت موظف است سوالات خود را به درستی فرموله کند اطلاعات جمع آوری شده، در حالی که عملاً هیچ ناحیه خاکستری نامرئی وجود ندارد.
دانلود تابلو